Clear Sky Science · zh
神经网络中的精确特征碰撞
不同图像如何愚弄智能机器
现代人工智能系统可以识别面孔、解读医学影像并为自动驾驶汽车提供导航。我们已经知道,它们可以被对图像施加微小且精心设计的改动所欺骗。本文展示了更令人惊讶的现象:这些网络对巨大的、显而易见的变化也会视而不见,将截然不同的图像当作相同。理解这种现象发生的原因对于构建真正值得信赖的 AI 系统至关重要。
从微小调整到巨大的盲点
深度神经网络驱动着当今在视觉、语言和许多其他领域的突破。先前关于对抗样本的研究表明,对图像做几乎不可见的改变就能使网络以高置信度错误分类。近来的工作揭示了相反的问题:有些网络对大幅且显著的变化几乎没有反应,仍给出几乎相同的预测。在这些情况下,从两张非常不同的图像中提取的内部特征会“碰撞”,即网络以几乎相同的方式表示它们。本研究将这一观点推进到更深的层次,证明常见网络不仅存在近似碰撞,还能出现精确的特征碰撞——两个不同的输入会被映射为完全相同的内部信号。
碰撞如何在网络内部产生
为了解释这些碰撞,作者深入检查神经网络的内部,重点关注它们的权重矩阵——连接层与层之间的训练数值。当两个不同的输入在某一层产生相同的输出时,就会发生特征碰撞;一旦发生,后续所有层看到的也相同,因此无法区分这些输入。从数学上讲,这发生在两个输入的差值位于该层权重的“零空间”时:即输入空间中被该层完全忽略的方向。作者证明,当权重矩阵存在零特征值或从更高维映射到更低维时,这类被忽略的方向必然存在。由于大多数现实中的架构(包括流行的分类、分割和目标检测模型)使用了许多这样的层,碰撞并非罕见的边缘情况,而是这些网络的几乎不可避免的属性。
构造碰撞输入的一种新方法
基于这一洞见,论文提出了一种实用方案,称为零空间搜索。该方法并不依赖反复试验或基于梯度的技巧,而是直接利用第一层权重矩阵的零空间。从任意一张图像出发,作者计算出一个第一层会忽略的向量,然后将该向量的缩放版加到图像上。由于这个方向对第一层不可见,网络的内部特征——以及最终预测——保持完全相同,即使对人类观察者而言图像本身可能被严重扭曲。相同的思想可以扩展到卷积层,并且原则上可适用于更晚的层。作者考察了许多标准模型,发现大多数模型都有大量此类被忽略的方向,意味着可以用这种方法为多种任务生成无数碰撞图像。
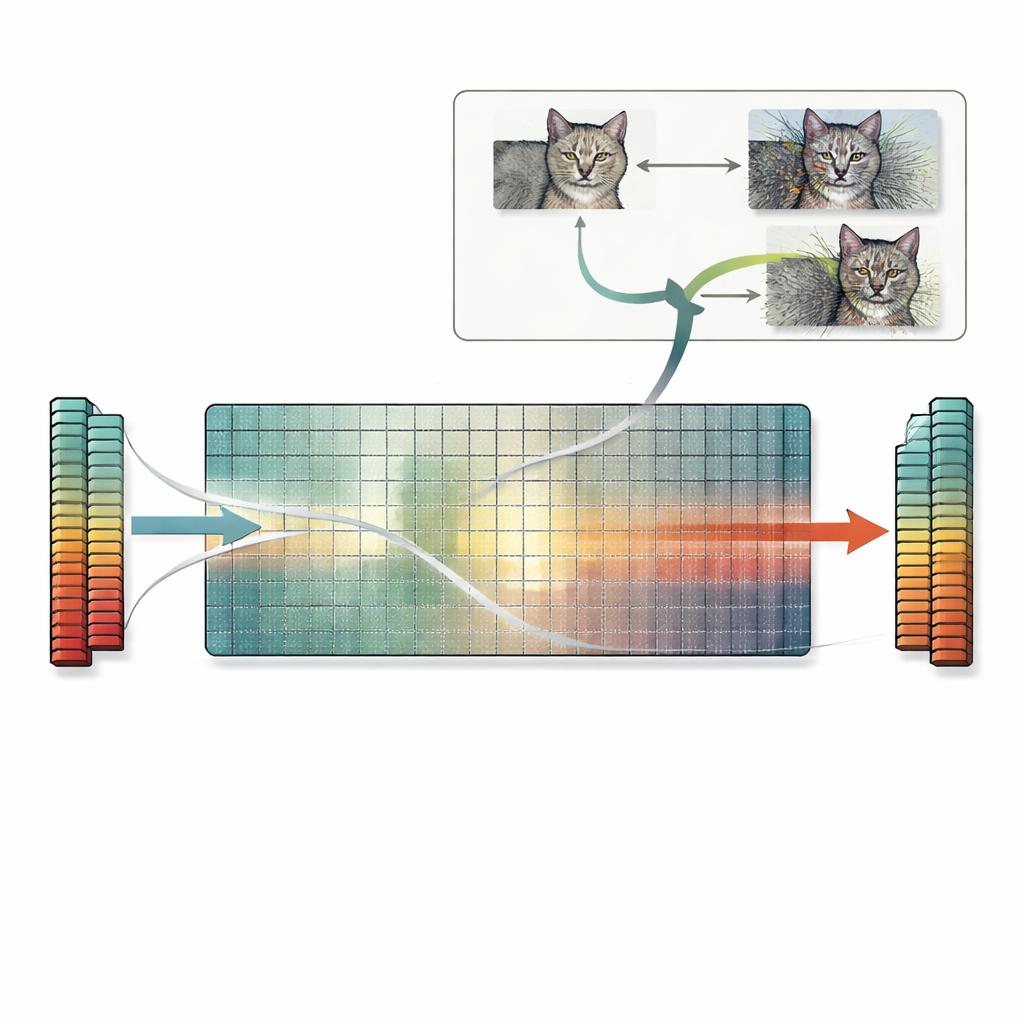
对相似性、可解释性与安全性的隐含风险
这些精确特征碰撞具有深远影响。特征发生碰撞的两张图像不仅会共享相同的预测,它们通常还会共享由流行可解释性工具产生的相同解释图谱。这可能导致一张难以辨认、被严重扰动的图像看起来与一张干净图像同样有力地被支持,从而破坏对解释方法的信任。该问题也影响基于特征的相似性度量:由于特征完全匹配,这类度量可能将一张被严重破坏的图像判断为与原图“相同”,尽管简单的基于像素的评分会正确指出巨大的差异。最后,零空间搜索可以与常见的对抗攻击结合,产生许多不同的对抗图像,这些图像都给出相同的错误预测并保持在标准扰动限制内,加剧了现有的安全隐忧。
这对构建更安全 AI 的启示
简言之,这项工作表明,当今的神经网络常以可预测的方式丢弃信息,留下一整类在输入空间中不会影响其决策的方向。攻击者可以利用这些盲点创建网络将其视为与正常图像相同的奇异或对抗性图像。作者建议使用这些被忽略方向的简单计数作为评估模型脆弱性的一种手段,并认为更精简、正则化更好、零空间更小的网络可能更具鲁棒性。尽管理论到实践还有许多待验证之处,但核心信息很明确:如果我们想要可靠的 AI,就必须关注网络响应的内容,也要关注它们忽略的内容。
引用: Ozbulak, U., Rao, S., De Neve, W. et al. Exact feature collisions in neural networks. Sci Rep 16, 10139 (2026). https://doi.org/10.1038/s41598-026-40605-4
关键词: 神经网络, 对抗样本, 特征碰撞, 模型鲁棒性, 零空间搜索