Clear Sky Science · zh
在分布式医学影像中用于自动白血病检测的轻量级注意力改进卷积神经网络的隐私保护联邦学习
在不共享隐私的情况下共享知识为何重要
现代医学越来越依赖计算机来解读医学影像,从X光片到显微镜切片。但训练这些系统通常意味着将敏感的患者数据集中到一个地方,从而引发严重的隐私问题。本研究展示了一种方法,使医院能够在不共享原始患者数据的情况下构建用于从血液图像检测白血病的强大系统,将隐私保护与接近顶级的诊断准确性相结合。
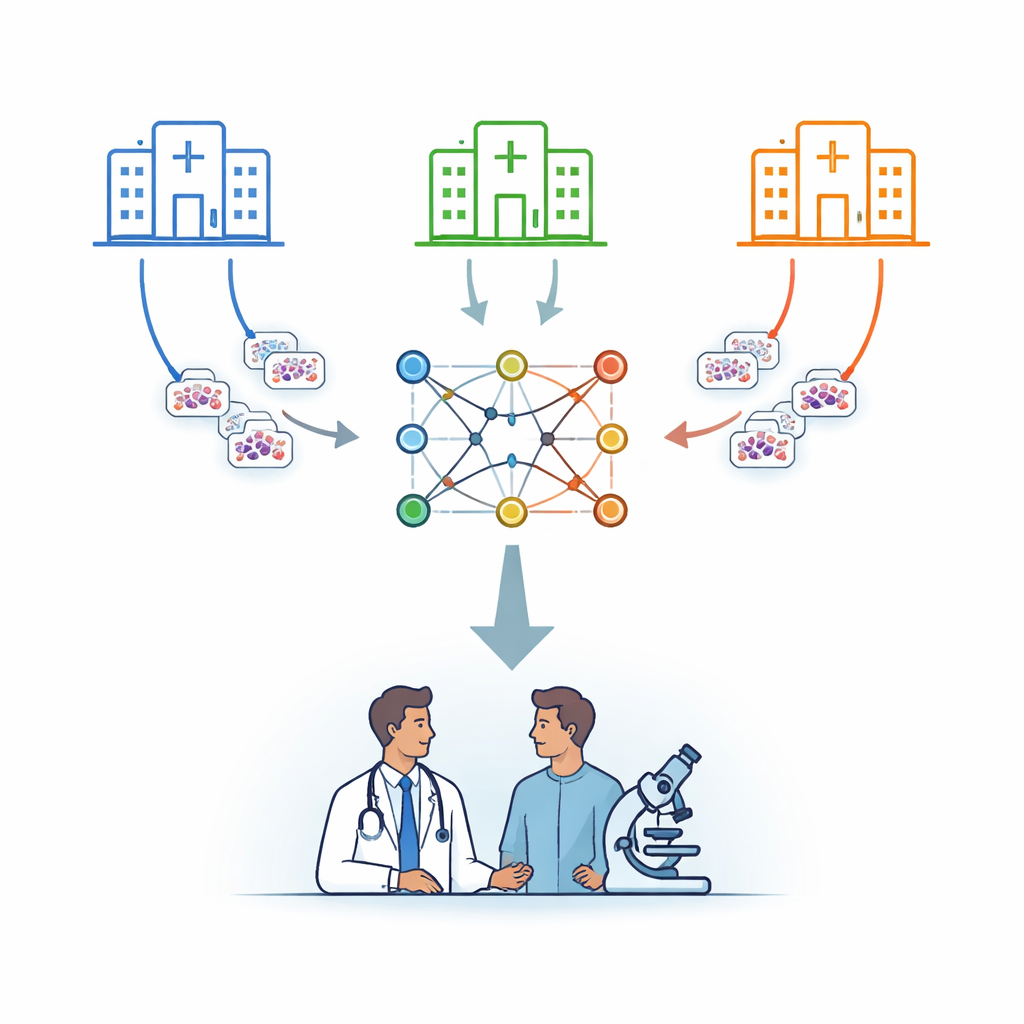
多家医院,共享一个“大脑”
研究者将重点放在白血病上,这是一种可以通过显微镜下检查细胞来辅助诊断的血液癌症。研究中没有将患者图像发送到中央服务器,而是采用称为联邦学习的策略。在这种设置下,若干医院各自在本地保留图像并训练同一计算模型的拷贝。定期只将模型学到的参数发送到一个安全的中央服务器,由其进行平均并将改进后的合成模型返回。通过这种方式,知识被汇聚,而底层的图像始终留在所属机构。
教一网络如何聚焦要点
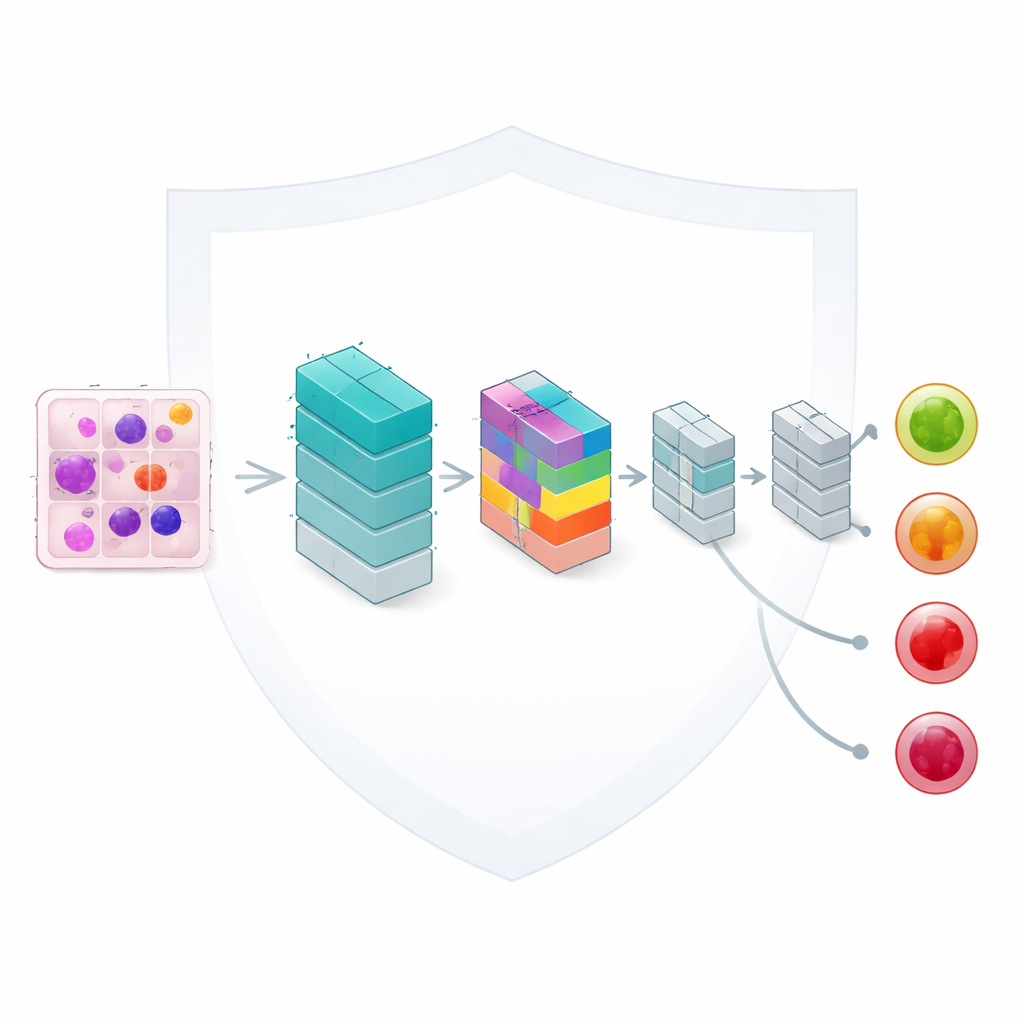
该框架的核心是一种基于卷积神经网络的轻量级图像分析模型,这是读取图像的常用工具。作者用一种紧凑的“注意力”机制增强了模型,帮助网络聚焦于每个血细胞中信息量最大的部分,例如细胞核的形状和周围物质的纹理。尽管该模型只有大约33,000个可调参数——仅为许多现代网络规模的一小部分——它仍能区分四个临床重要的类别:良性细胞、早期变化、白血病前期状态和完全发展的促白血病细胞。精心的设计使计算速度足够快,适合常规实验室的实际使用。
从不均衡与分散的数据中公平学习
在真实的医疗系统中,各医院遇到的患者构成并不相同。一个中心可能主要见到早期病例,另一个则更多晚期病例。团队通过将3,256张血涂片图像的数据集分配到多个模拟医院,并使每个医院具有不同阶段的比例,刻意模拟了这种现实世界的不平衡。然后他们分析这种不均匀分布如何影响学习,使用统计度量来量化每个医院数据的差异性以及它们最终准确率的相似性。一种加权平均方案确保数据较多的站点具有相应的影响力,同时仍将站点之间的性能差异保持在很小的范围内。
可与集中训练媲美的准确性
尽管数据保持分散且分布不均,所共享的模型仍学会了以令人印象深刻的能力对白血病分期进行分类。在三个模拟医院的情况下,全局模型在留出测试图像上的准确率约为95.7%;在五个医院并经过更多训练轮次时,准确率上升到约96.6%。恶性类别——代表白血病前期及更晚期的那些类别——识别表现尤其出色,在某些情况下接近完美。表现更具挑战性的良性类别由于样本较少,表现略差,凸显了需要更好平衡或针对罕见但重要类别的技术改进。尽管如此,该联邦系统在保留本地存储隐私优势的同时,其准确性仅与集中所有数据时的结果相差一小部分。
让机器的推理可视且值得信赖
为与临床医生建立信任,作者不仅关注原始准确率,还审视模型的决策方式。他们生成可视化覆盖图,突出显示每个细胞图像中对结果影响最大的区域。这些热图显示模型关注的是医学上有意义的特征,例如在更危险的白血病阶段出现的异常细胞核形状,而良性细胞则表现出更弥散的模式。团队还研究了模型预测的置信度,发现正确答案往往具有较高置信度,尤其是在恶性阶段,这表明系统的不确定性与其可靠性之间匹配良好。
这对未来癌症诊断的意义
对非专业读者来说,关键信息是:医院现在可以在不交出患者图像的情况下协作构建更智能的癌症诊断方案。本研究表明,通过联邦学习训练的紧凑且设计得当的模型,可以在尊重隐私规则以及计算能力和网络流量的实际限制下,达到接近传统集中数据方法的准确性。随着在更好处理表现不足的细胞类型和降低通信成本方面的进一步工作,类似的隐私保护系统可以推广到其他癌症和成像检测,帮助全球临床医生在不暴露个体患者的情况下共享经验收益。
引用: Awan, M.Z., Khan, N.A., Strakos, P. et al. Privacy-preserving federated learning with light-weight attention improved CNNs for automated leukemia detection across distributed medical imaging. Sci Rep 16, 9768 (2026). https://doi.org/10.1038/s41598-026-40581-9
关键词: 联邦学习, 白血病成像, 医学人工智能隐私, 基于注意力的卷积神经网络, 数字病理学