Clear Sky Science · zh
CMT-Unet:利用分阶段混合框架提升医学图像分割的精度与效率
看清体内结构的更锐利视角
现代医学在很大程度上依赖 CT 和 MRI 等扫描来观察体内,但将这些模糊的灰度图像转换为器官与组织的清晰轮廓仍然具有挑战性。医生需要精确的边界以便规划手术、跟踪心脏功能或评估肿瘤对治疗的反应。本文介绍了一种新的计算机视觉方法,称为 CMT-Unet,旨在更准确、更高效地绘制这些边界,使自动化图像分析更接近日常临床应用。
为什么图像轮廓很重要
在手术或复杂治疗之前,临床医生通常需要对扫描中的器官或结构进行像素级标注——这一过程称为分割。传统上,专家会手工勾画这些区域,这既耗时又容易疲劳,并且不同观察者之间存在差异。过去十年中,基于深度学习的方法接管了大量此类工作,尤其是基于卷积神经网络和类 Transformer 注意力机制的模型。卷积模型擅长捕捉局部细节如边缘,而 Transformer 则在把握整张图像的全局语境方面表现尤为出色。然而,两者各有权衡:卷积可能忽略远距离关系,而 Transformer 往往需要大量计算资源和内存。
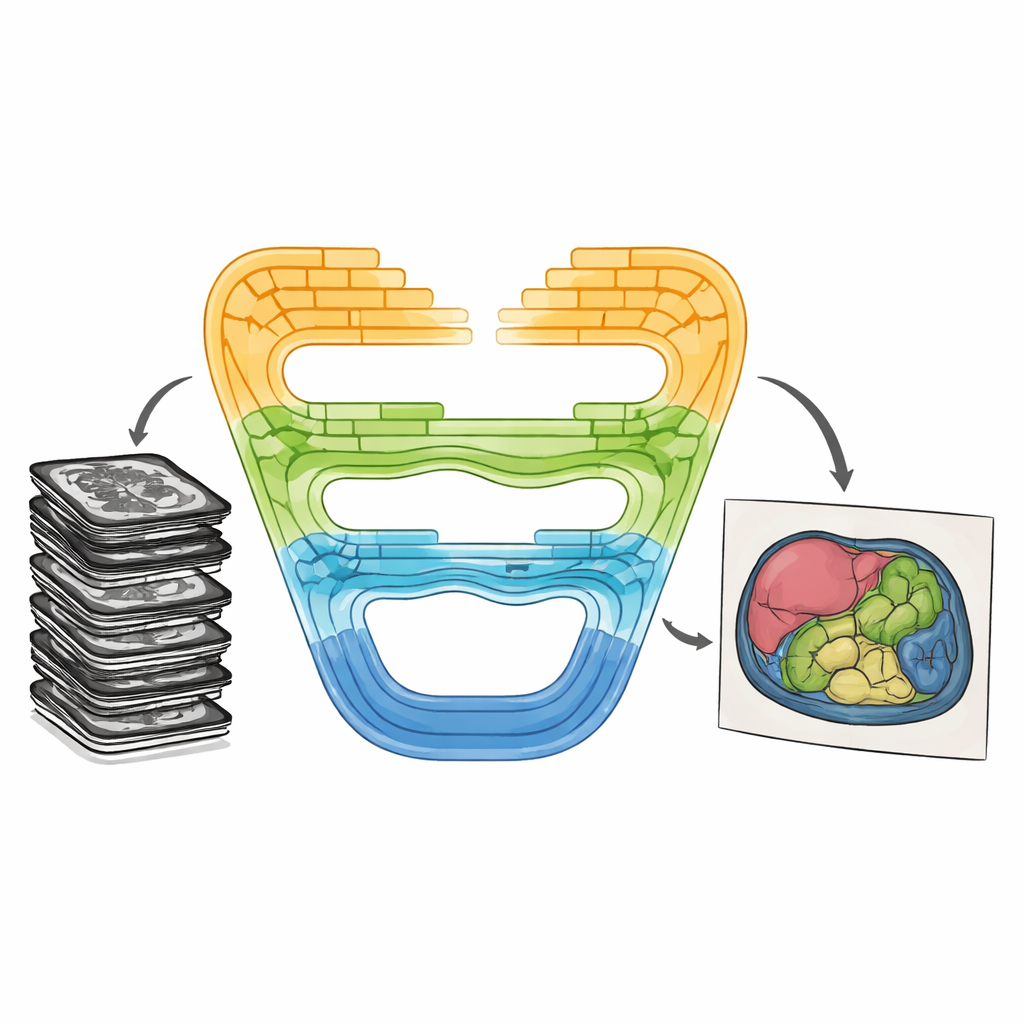
以新方式结合优势
CMT-Unet 通过在分阶段结构中交织三种构建模块来应对这些权衡,而不是在整个网络中只使用单一类型。在系统的前端,倒残差卷积单元快速学习局部模式——诸如有助于区分相邻组织的清晰边界和纹理。在中间阶段,基于所谓状态空间模型的模块(改编自最近的一种称为 Mamba 的架构)以既考虑上下文又计算开销低的方式在图像特征序列之间传递信息。在网络的更深处,采用 HiLo 注意力增强的 Transformer 区块将信息分解为高频和低频分量,使模型在重新组合之前既能捕捉微小细节又能把握宏观器官形状。这种分层设计类似于图像处理从原始像素到抽象语义的自然进化过程。
新模型的实现细节
在实践中,CMT-Unet 遵循医学影像中常见的 U 型布局:编码器将信息压缩为更丰富的特征,解码器重建全尺寸预测,跳跃连接传递空间细节。关键区别在于各深度使用的模块类型。早期的卷积单元处理那些 Mamba 和 Transformer 组件可能模糊的细粒结构。修改后的 MambaVision 模块通过专门设计的二维操作混合空间信息,提高中程上下文感知,同时避免全注意力带来的高昂代价。Transformer 阶段的 HiLo 注意力将清晰边缘与平滑背景模式显式分离,并以保留边界的方式将二者结合。最后,解码器中的双重上采样模块有助于重建干净、连续的轮廓,同时减少诸如棋盘格状伪影等常见问题。
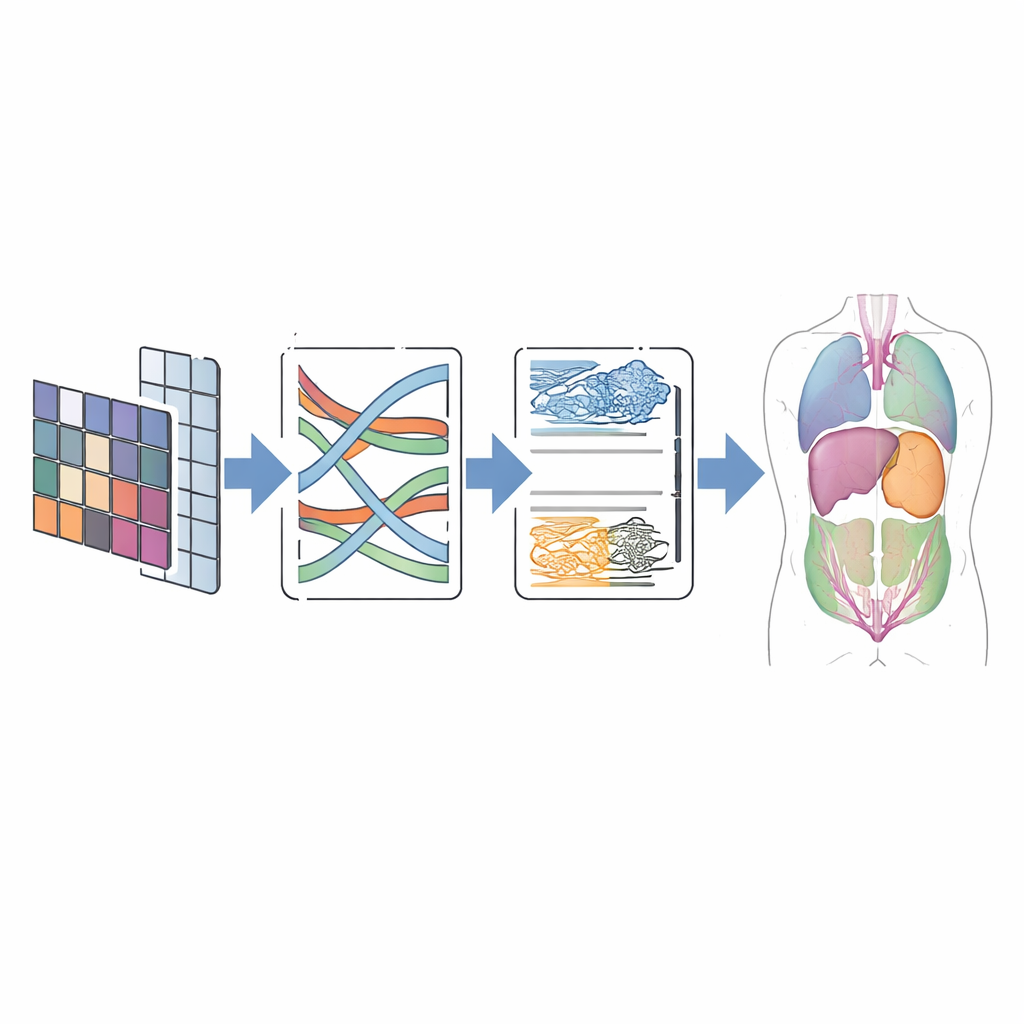
在真实扫描上的测试
为评估该设计的效果,作者在两个广泛使用的公开数据集上测试了 CMT-Unet。第一个名为 Synapse,包含带有八个标注器官(包括肝、肾和胃)的腹部 CT 扫描。第二个 ACDC 包含带心室与心肌壁标签的心脏 MRI 图像。在这些基准上,CMT-Unet 在分割评分上达到了与领先的卷积、Transformer 及混合模型相当或更优的表现,同时使用了适中的参数量和可管理的计算开销。视觉对比显示出更平滑且解剖学一致性更高的边界,特别是在诸如心腔这类对测量功能和干预规划至关重要的挑战区域。
这对患者与医院意味着什么
对非专业读者而言,主要结论是 CMT-Unet 通过在处理各阶段匹配合适工具,提供了一种更智能的医学图像结构描绘方式。通过平衡局部细节与全局上下文,模型可以在不依赖超级计算资源的情况下生成准确、干净的器官轮廓。尽管当前工作集中于二维扫描和有限的公开数据集,但该方法在扩展到三维成像和更广泛的临床环境方面具有良好前景。如果进一步验证,这类轻量而精确的分割技术可支持更快速的诊断、更可靠的治疗规划以及在繁忙医院中提供实时指导。
引用: Wang, R., Liu, H. & Wang, G. CMT-Unet: leveraging stage-wise hybrid framework for enhanced accuracy and efficiency in medical image segmentation. Sci Rep 16, 10079 (2026). https://doi.org/10.1038/s41598-026-40572-w
关键词: 医学图像分割, 深度学习, 混合神经网络, 状态空间模型, 医学影像