Clear Sky Science · zh
MedicalPatchNet:一种基于补丁的自解释 AI 架构用于胸片分类
为什么更“聪明”的胸片很重要
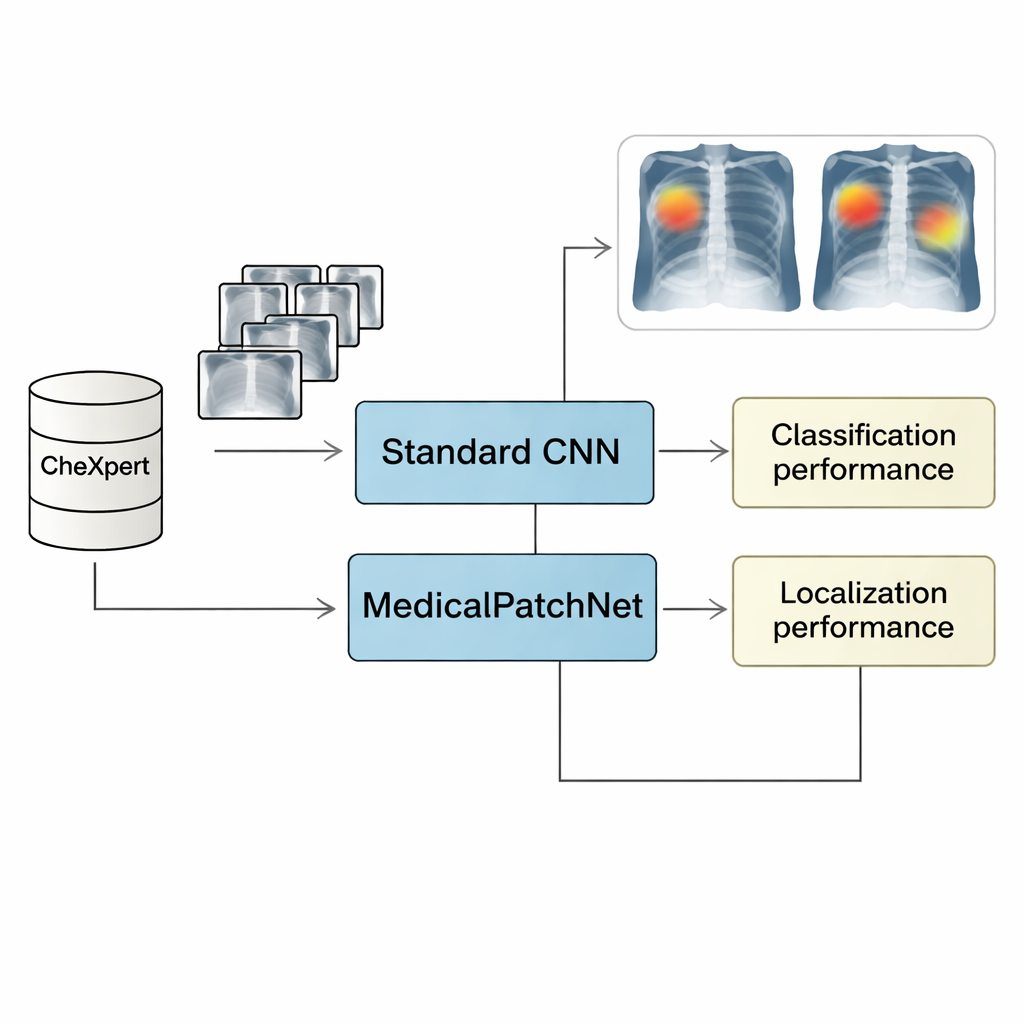
胸片是全球使用最广泛的医学检查之一,人工智能(AI)系统正越来越多地辅助医生解读。但当今许多表现最好的 AI 模型如同“黑箱”:它们可能很准确,但即便是专家也难以看出为何得到某一特定诊断。这种透明度的缺失使临床人员难以信任并在真实医疗环境中安全使用 AI。研究提出了 MedicalPatchNet,这是一种新的 AI 方法,旨在在保持较高准确性的同时,使其推理过程可见且易于理解,即便对没有机器学习背景的人也是如此。
把图像拆成小而有意义的区域
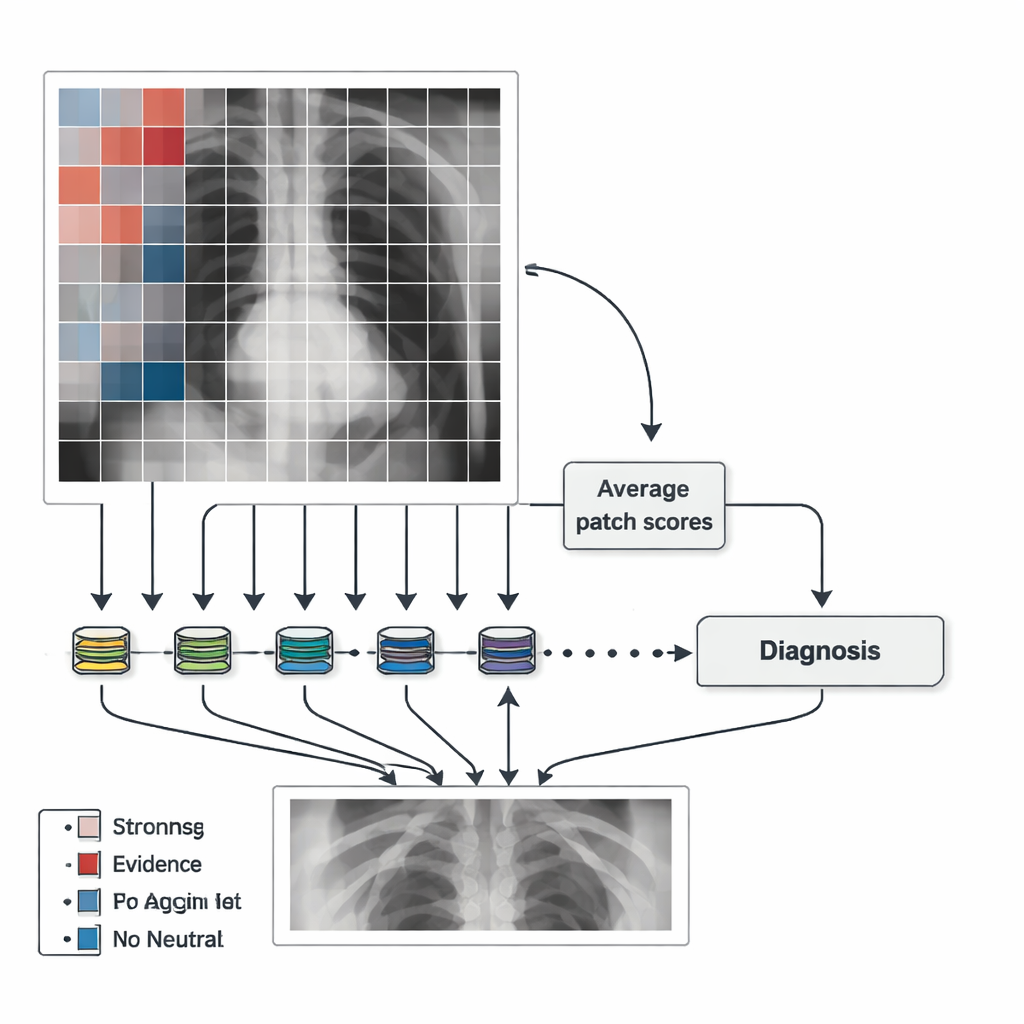
MedicalPatchNet 并不是把胸片当成一个大而神秘的整体来分析,而是将图像分割成许多小的、不重叠的方块或“补丁”。每个补丁都通过相同的神经网络处理,网络会为若干可能的发现(例如肺部实变、肺炎或胸腔积液)给出评分。然后把这些补丁级别的得分简单平均,得到整张图像的总体判定。由于最终答案只是许多局部投票的总和,因此可以直观地展示每个补丁对诊断的贡献。关键在于,这里没有隐藏的注意力机制或复杂的内部加权方案,因此每个区域的影响是明确定义的,而非以不透明的方式被学习。
将模型决策转为清晰的可视化图
作者利用这些补丁得分生成“显著性图”,以突出 AI 在何处发现支持或反对某种疾病的证据。强烈支持某项发现的补丁用暖色(例如红色)显示,反对证据用冷色(如蓝色)表示,中性区域则为灰色。这样可以很容易看出模型是否关注肺部、心脏,或令人担忧地关注到诸如边界伪影或文字标签等无关特征。为了让图更平滑、不那么方块状,团队还通过对图像进行多次小幅平移并平均结果来生成地图。虽然这会增加一定的计算成本,但生成的热图更贴合解剖结构,同时仍保留每个区域与最终决策贡献之间的明确联系。
在提高信任的同时匹配黑箱模型的性能
为了测试 MedicalPatchNet,研究人员在 CheXpert 上训练了该模型——这是一个包含超过 22 万张胸片、针对 14 种常见发现标注的大型公开数据集。他们将其性能与使用相同主干网络(EfficientNetV2-S)的强大常规模型进行了比较。平均而言,二者在受试者工作特征曲线下面积(AUROC)、敏感性、特异性和准确率等诊断指标上几乎相同。换句话说,强制模型逐补丁推理并平均结果并未显著削弱其识别疾病的能力。这表明对于许多胸片任务而言,局部图像信息已足够,模型无需依赖复杂的全局模式也能表现良好。
观察模型“注视”疾病的位置
除了总体准确性,关键问题是 MedicalPatchNet 是否比流行的“事后”工具(如 Grad-CAM 及其变体)更可靠地解释自身。为此,团队使用了第二个数据集 CheXlocalize,该数据集提供放射科医师绘制的实际病变区域轮廓。他们测量了方法最突出点落在真实异常区域内的频率(“命中率”),以及突出区域与专家标注的重叠程度(平均交并比,mIoU)。MedicalPatchNet 的补丁式地图在十种情况中有九种达到了比 Grad-CAM 风格解释更高的命中率,并在计算正确与错误预测的总体重叠时取得了最佳整体重合率。这种更广泛的评估很重要,因为它会惩罚那些只有在模型正确时才看起来不错但在模型错误时未能揭示误导性行为的解释方法。
从不透明的猜测走向透明的合作伙伴
对非专业读者而言,主要结论是 MedicalPatchNet 表明可以在胸片诊断上保持接近最先进的性能的同时,使 AI 的推理过程更加透明。与那些可能并不反映实际驱动决策的神秘热图不同,这种方法将每个高亮区域直接关联到模型计算中的局部投票。临床人员不仅能看到 AI 是否认为存在某种疾病,还能确切知道图像的哪个位置提供了支持或反对的证据。尽管该方法仍有局限——例如对于需要将图像中相距较远区域一同考虑的情况存在困难——它为开发不再像黑箱而更像清晰、可问责的医学影像合作工具提供了切实可行的路径。
引用: Wienholt, P., Kuhl, C., Kather, J.N. et al. MedicalPatchNet: a patch-based self-explainable AI architecture for chest X-ray classification. Sci Rep 16, 7467 (2026). https://doi.org/10.1038/s41598-026-40358-0
关键词: 胸片 AI, 可解释深度学习, MedicalPatchNet, 医学图像显著性图, 放射学决策支持