Clear Sky Science · zh
一种基于kNN的机器学习方法用于不良事件因果关系评估的自动化
这对用药者为何重要
当一种新药进入市场时,它的故事才刚刚开始。数以百万计的人会在真实世界中使用它,其中一些人会出现可能与药物相关也可能无关的健康问题。识别哪些反应确实与药物有关对患者安全至关重要,但目前这项工作缓慢、复杂且主要依赖人工。本研究探讨了一种简单但强大的人工智能形式如何帮助专家更快、更一致地审查这些安全报告,同时不取代最终保护患者的人类判断。
安全事件如何转化为数据
制药公司和监管机构依赖个案安全报告,这些报告是对真实患者用药经历的结构化总结。每份报告可能包括发生了什么(例如头痛或肝功能异常)、严重程度、同时使用的其他药物与合并疾病,以及原始审阅者对药物关联的看法。在来自六种已上市药物的超过80万份此类报告中,该公司的医疗审阅者已对每个不良事件判断为与药物相关、不相关或因信息缺失/冲突而无法评估。研究者将这份丰富的历史记录用作训练材料,让计算模型学习在新病例中模仿这些人工判断。

教计算机识别相似病例
团队没有构建黑箱系统,而是选择了一种特别透明的方法,称为“近邻法”。其思路直观:如果两个病例非常相似,它们很可能在是否由药物引发这一结论上相同。为量化相似性,研究者将每个不良事件表示为包含七个部分的档案,包括事件的医学术语、停药重启后的情况、该药是否可能出现该问题、报告者意见、同时服用的其他药物、既往病史以及事件的严重性。然后在这个七维空间中测量任意两例的距离,并对对因果关系最重要的特征(例如具体事件和治疗变化时的反应)赋予更高权重。
从相似性到三类决策
当一份新报告到来时,模型会在历史数据中寻找十个最相似的病例,检查这些邻居如何被分类,并让它们就三种广泛结果“投票”:可能与药物相关、不相关或不太可能相关,以及无法评估。这种三分法在临床细微差别与可依赖的表现之间取得平衡。在超过25万条先前未见过的事件上测试时,模型在被认为相关和被判定为无法评估的事件上与人工审阅者高度一致,错误率低,兼顾准确性和覆盖率的评分良好。模型对数量较少的明确不相关事件表现较差,反映出当某一类别样本相对稀少时,机器学习系统面临的挑战。
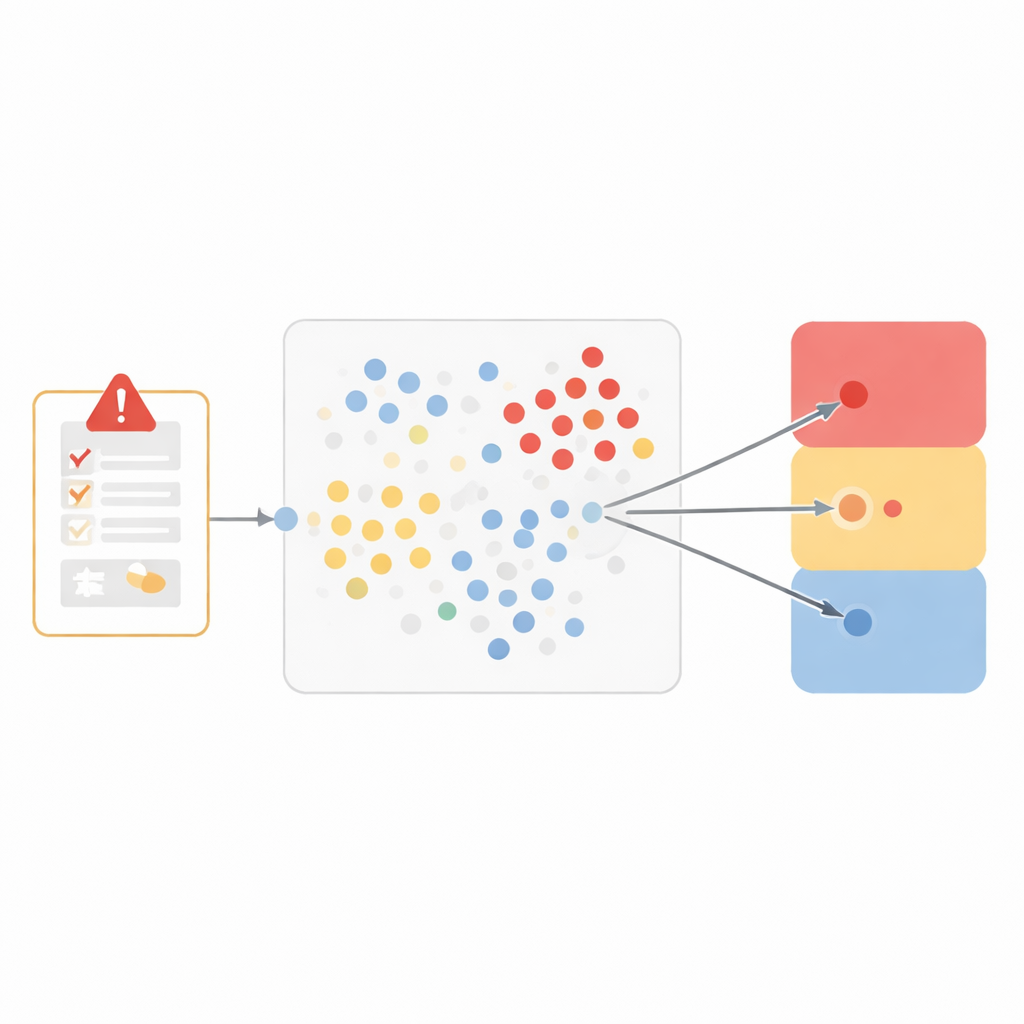
减少“不确定”的迷雾
现实世界安全工作中的一个实际问题是,“无法评估”标签容易成为信息稀少或模糊时的收纳箱,从而掩盖真实的安全模式。研究者增加了一个可调节工具,使模型在分配该标签时更为谨慎。模型不再在类似病例中简单多数支持时就选择“无法评估”,而是要求更高比例的邻居支持该选项。通过提高这一阈值,团队显著减少了模型将病例判为无法评估的频率,并改善了另外两类的性能,代价是对最难判断的病例出现更多分歧。一个基于网络的仪表盘允许医疗审阅者按产品调整此阈值,即时查看结果分布如何变化,并将注意力集中在模型与人类意见不一致的病例上。
这对未来药物安全意味着什么
在一批被人工审阅者标记为无法评估的近期病例样本中,系统标出数百例结论不同的情形。当资深审阅者重新审查这些病例时,他们超过三分之二的情况下与模型达成一致,表明此类工具可以标记被忽视的模式并支持质量监督,而不是取代专家。该研究表明,一种清晰、基于相似性的策略可以以可解释、可调节且符合医疗实践的方式将人工智能引入药物安全。随着更多数据的积累以及使用现代语言技术加入文本叙述,类似系统有望帮助更早发现新兴风险,同时让临床医生保持对最终判断的主导地位。
引用: Ren, J., Carroll, H., McCarthy, K. et al. A kNN based machine learning approach to automating causality assessment of adverse events. Sci Rep 16, 9140 (2026). https://doi.org/10.1038/s41598-026-40267-2
关键词: 药物警戒, 药物不良事件, 因果关系评估, 机器学习, k近邻