Clear Sky Science · zh
KM-DBSCAN:一种用于数据缩减以实现绿色人工智能的增强型基于密度与质心的边界检测框架
为何把人工智能做小反而更环保
人工智能有一项隐性成本:电力消耗。训练现代机器学习模型通常需要在高功耗硬件上处理数百万条数据点,从而产生大量碳排放。本文提出了 KM-DBSCAN,这是一种在训练前缩减数据集的新方法,同时不丢弃模型实际需要的信息。通过仅保留最具信息量的数据,该方法加快学习速度、减少能耗,并在从手写数字识别到皮肤癌早期检测的多种任务中仍能提供准确的预测。
数据太多,能耗太高
多年来,AI领域的主流观点是“数据越多越好”,更多的数据通常能带来更好的模型。虽然这能提升准确性,但也意味着更长的训练时间、更大的计算设备以及更高的电费。研究者开始区分“红色 AI”(不惜一切代价追求准确性)与“绿色 AI”(在性能与环境影响之间寻求平衡)。实现更绿色 AI 的一个有前景的途径是数据缩减:不是把每个可用样本都喂给模型,而是识别一小部分仍能很好定义问题的样本,尤其是那些决定分类器判断的棘手边界样本。
将两个简单思路合并为一个智能滤器
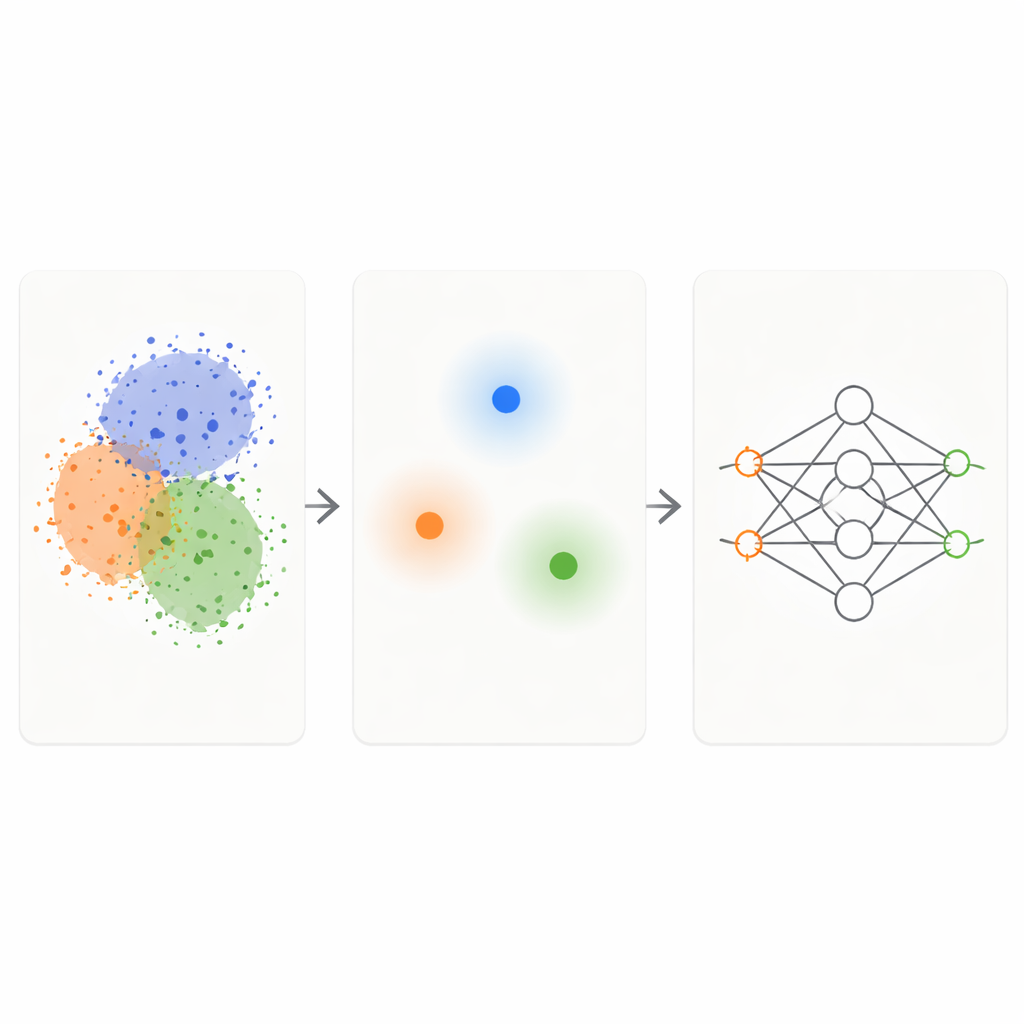
KM-DBSCAN 框架结合了两种知名的聚类技术,对原始数据进行智能过滤。首先,使用一种称为 K-Means 的快速方法将点分成紧凑的簇,并用每个簇的代表中心(质心)替代该簇的点。这将问题从数千或数百万个点缩减到几百个代表点。接着,在这些质心上运行基于密度的方法(DBSCAN),以识别哪些区域处于簇的边界、哪些是密集且同质的内部区域或孤立噪声。通过在质心级别上工作,DBSCAN 变得更快且对参数调整不那么敏感,而不是直接作用于所有数据点时那样棘手。

只保留难点与信息量大的样本
一旦 KM-DBSCAN 识别出不同群组接触或重叠的位置,它只保留位于这些边界附近的数据点,并丢弃深处的内部点与明显的离群点。内部点大多是冗余的:它们彼此相似,向模型传递相同的类别信息。相比之下,边界点能确切告诉模型一个类别在哪里结束、另一个类别从何处开始。在合成的玩具数据集上,这一策略即便在移除大多数点的情况下也能再现与完整数据训练所得相同的决策边界。在真实世界数据集(如 Banana、USPS 手写数字、Adult 收入数据集、交通事故数据、干豆类样本和黑色素瘤皮肤图像)上,缩减后的集合在保持问题关键结构的同时规模小了一个数量级。
速度提升、碳排放节省与实际应用
作者将 KM-DBSCAN 作为若干流行模型的前端进行测试,包括支持向量机、多层感知器和卷积神经网络。在许多情况下,对缩减数据的训练比原始数据快数十到数千倍,同时几乎保持相同的准确率——有时甚至略有提高。例如,在手写数字识别任务上,该方法将训练集缩减到仅原始规模的 1.4%,仍使准确率略有提升,并使训练速度提高了 284 倍。在一个类别不平衡的收入预测任务中,使用大约 3% 的数据实现了 6907 倍的加速,准确率损失极小。在一项黑色素瘤检测实验中,深度神经网络在不到三分之一的原始皮肤图像数据上训练就达到了超过 90% 的准确率,碳排放减少了超过 70%。
这对日常 AI 意味着什么
对非专业读者来说,关键讯息是:更聪明的样本选择能胜过单纯堆量。KM-DBSCAN 表明,谨慎选择模型看到的样本——聚焦于最具信息量的边界样本——可以大幅削减计算时间与能耗,同时保持预测可靠性。这一方法与推动绿色 AI 的更广泛努力相契合:数据质量与训练流程的周到设计与模型规模本身同等重要。如果被广泛采用,这类以数据为中心的过滤可以让医疗影像分析到交通安全系统等领域变得更可持续,使缺乏大规模计算资源的组织也能负担得起强大的 AI 工具。
引用: AboElsaad, M.Y., Farouk, M. & Khater, H.A. KM-DBSCAN: an enhanced density and centroid based border detection framework for data reduction towards green AI. Sci Rep 16, 10349 (2026). https://doi.org/10.1038/s41598-026-40062-z
关键词: 绿色人工智能, 数据缩减, 聚类, 机器学习效率, 黑色素瘤检测