Clear Sky Science · zh
通过深度学习注意力框架与理化特征融合进行抗糖尿病肽候选分子的从头生成与计算筛选
为何更聪明的肽设计对糖尿病至关重要
糖尿病影响全球数亿人,而现有药物并非对所有人都完全有效。许多治疗方法随时间效力下降或产生副作用。一类称为抗糖尿病肽的小型蛋白质能以较高的精度调节血糖,是一条有前景的新途径。问题在于,在实验室中发现新肽类药物既缓慢又昂贵。本研究提出了一个计算驱动的流程,能够设计并筛选大量潜在的抗糖尿病肽,帮助研究者锁定最值得在现实中验证的候选分子。
从已知糖尿病肽到干净的起始数据
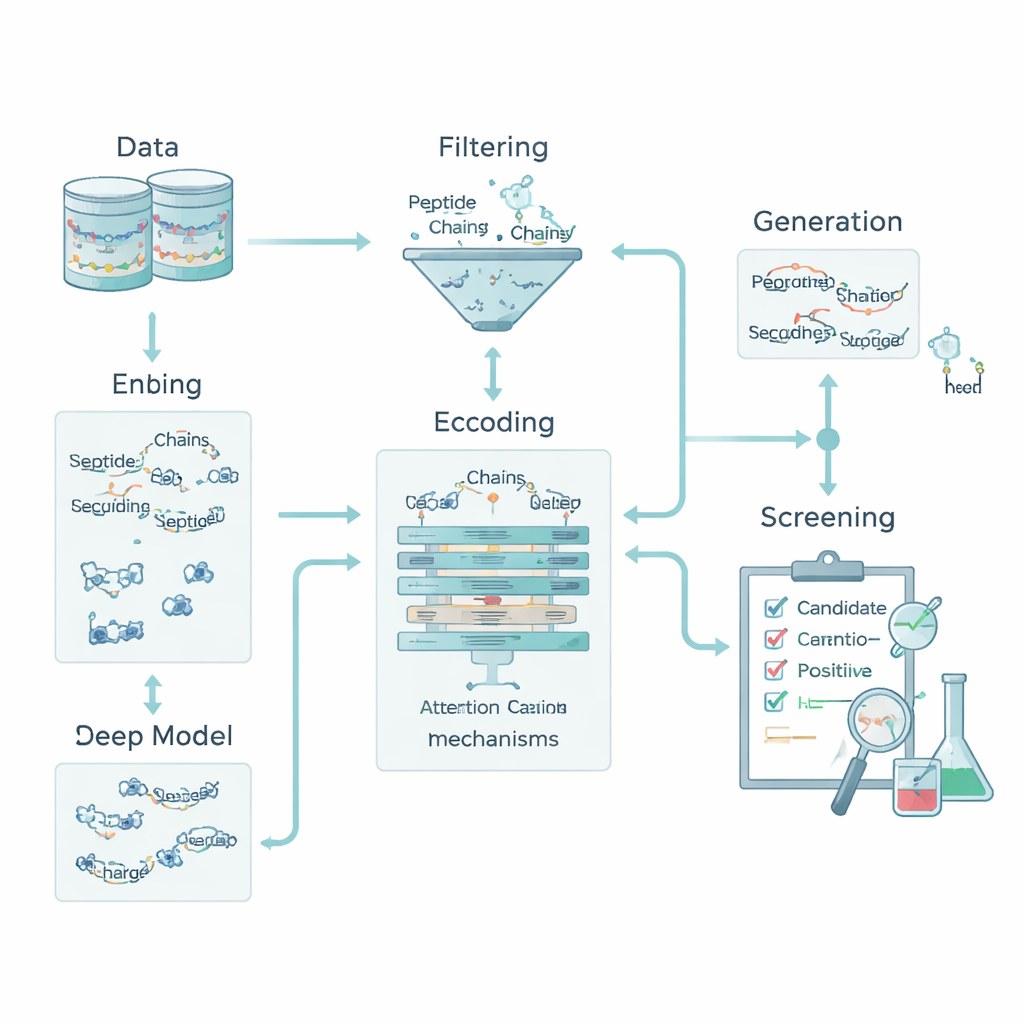
研究者首先汇集了一组高质量的肽,已被实验证明能影响血糖,主要通过调控如GLP-1之类的激素或DPP-IV等酶。这些构成了“正例”。随后,他们构建了一组匹配的“负例”,这些肽未报告具有抗糖尿病活性,且在长度、组成和基本化学性质上与正例相似。为避免模型被近似重复样本欺骗,他们使用序列相似性工具确保高度相关的肽不会同时出现在训练和测试集中。这样的同源性感知划分确保系统的评估侧重于识别真正的新模式,而不是记忆已见样本。
将化学信息编码成机器可读的形式
对计算机而言,肽只是表示氨基酸的字母序列。为将这些字母与生物学联系起来,团队为每种氨基酸编码了五个基本化学特征:疏水性(抗水性)、电荷、形成氢键的倾向、质量以及是否含有芳香环。这样每个肽就被转化为一个小“图像”,同时捕捉了顺序和化学信息。在此基础上,他们还加入了整体肽描述符,如总电荷、平均疏水性和Boman指数(与肽与其他蛋白结合倾向相关)。这些特征使模型既能识别局部模式——短氨基酸基序——也能把握影响肽在体内行为的全局属性。
能解释自身决策的深度学习引擎
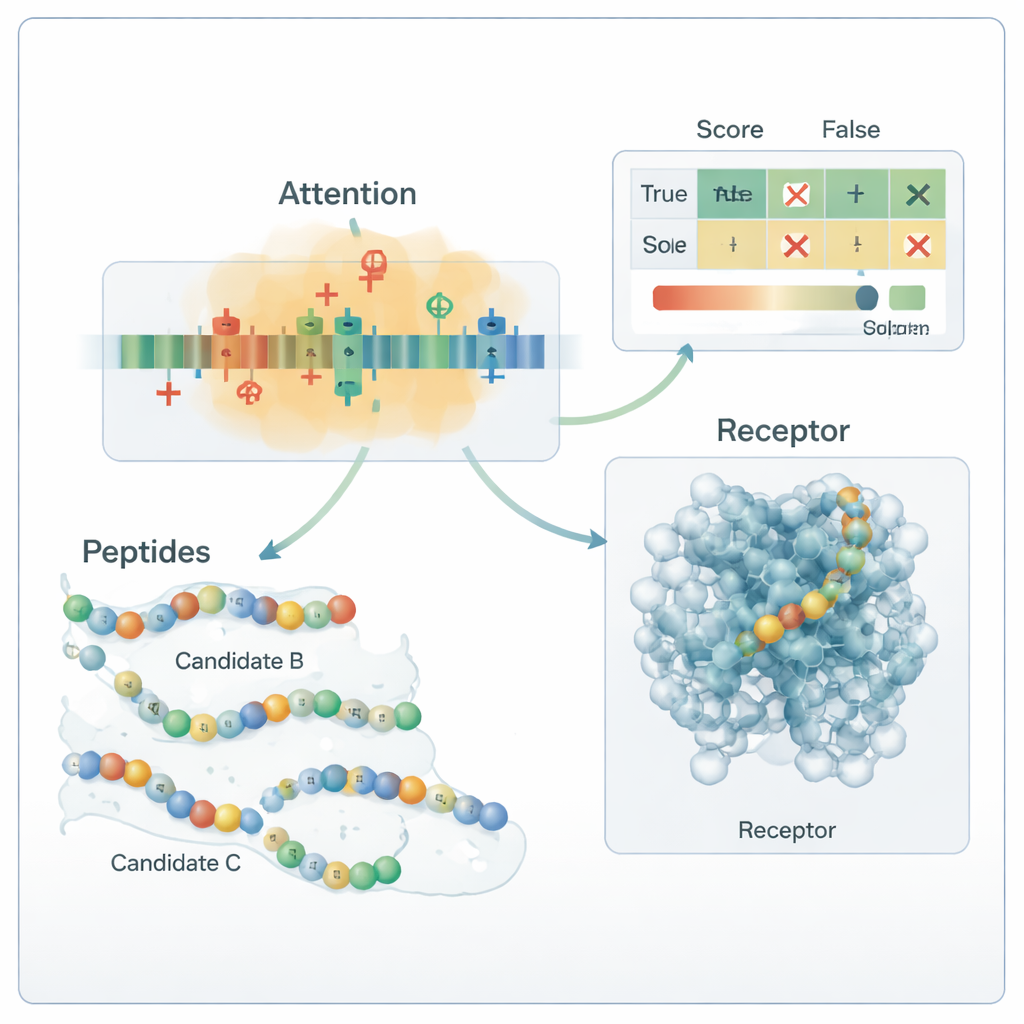
流程的核心是一个混合深度学习模型。卷积神经网络(CNN)沿肽序列扫描,寻找倾向出现在活性肽中的短基序,类似于图像识别系统中的滤波器。在此之上,注意力层学习序列中哪些位置最重要,捕捉远端残基之间的长程关系。该序列引擎的输出与全局化学描述符融合后,被送入若干常见的机器学习分类器——支持向量机、决策树、k近邻和梯度提升树。一个专门的优化方法(称为 OptimizedTPE)自动调节这些模型的参数,在准确性与过拟合风险之间取得平衡。注意力机制还生成残基级别的“重要性图”,帮助科学家看到每个肽中哪些部分驱动模型决策。
在避免数据泄漏的前提下发明新候选分子
为克服已知抗糖尿病肽数量有限的问题,团队加入了仅用于训练过程的生成阶段。他们采用多种策略——引导性突变、基序重组和变分自编码器——提出与已知活性肽相似但不复制的序列。这些候选序列随后通过严格的“描述符门控”进行筛选,强制执行现实的电荷、尺寸和结合倾向限制,并使用外部工具评估与已知生物活性肽的相似性。只有通过这些过滤并与所有测试肽保持明显不同的序列,才被保留为带弱标注的正例用于训练;这些生成序列绝不用于评估模型。该方法在扩充训练集的同时保持了干净且无偏的测试集。
系统的表现如何及其意义
在面对来自近期文献中独立收集的180条实验研究肽的完全独立测试组时,该框架大约正确标注了100条序列中的99条,精确度和召回率均接近0.99。就实际意义而言,这表明它很少漏检真正的抗糖尿病肽,也很少将无活性肽误判为有前景。对注意力图和突变测试的分析显示,模型学到了化学上合理的规则:它在很大程度上依赖于带正电荷的残基以及某些已知对结合糖尿病相关靶点重要的疏水残基。分子对接模拟进一步表明,部分新生成的肽有可能与人类GLP-1受体形成合理的接触。尽管这些预测仍需实验室确认,这项研究展示了一种可重复且有生物学依据的方法来探索广阔的肽药物空间,并优先筛选出最有可能帮助管理糖尿病的少数分子。
引用: Asl, Z.R., Rezaee, K., Ansari, M. et al. De novo generation and in silico screening of anti-diabetic peptide candidates via a deep learning–attention framework with physicochemical feature fusion. Sci Rep 16, 6580 (2026). https://doi.org/10.1038/s41598-026-39985-4
关键词: 抗糖尿病肽, 深度学习, 药物发现, 肽设计, GLP-1 受体