Clear Sky Science · zh
R-GAT:在数据有限情境下利用基于图的残差网络进行癌症文档分类
为何对癌症论文进行分类很重要
每天都有数以百计关于癌症的新研究发表,涵盖从早期检测到有前景的药物等各个方面。这些工作大多首先以摘要的形式出现。医生、研究人员和决策者不可能全部阅读这些摘要,而错过重要论文可能会拖慢进展。本研究着眼于一个简单但有力的问题:是否可以构建一个快速、轻量的计算系统,在标注数据和计算资源有限的情况下,自动将与癌症相关的摘要按癌症类型进行分类?
一种更智能的阅读癌症研究的方法
作者关注PubMed数据库中四类摘要:甲状腺癌、结肠癌、肺癌以及更广泛的生物医学主题。他们构建了一个经过仔细校验的包含1,875篇近期摘要的语料库,这四类在数量上大致均衡。这种平衡有助于避免偏向某一癌症类型。在建模之前,对文本进行了清洗:将词拆分为标记、校验拼写、合并相关词形并去除无信息的术语。清洗后的摘要通过若干标准方法转换为数值形式,以便对不同模型进行公平比较。
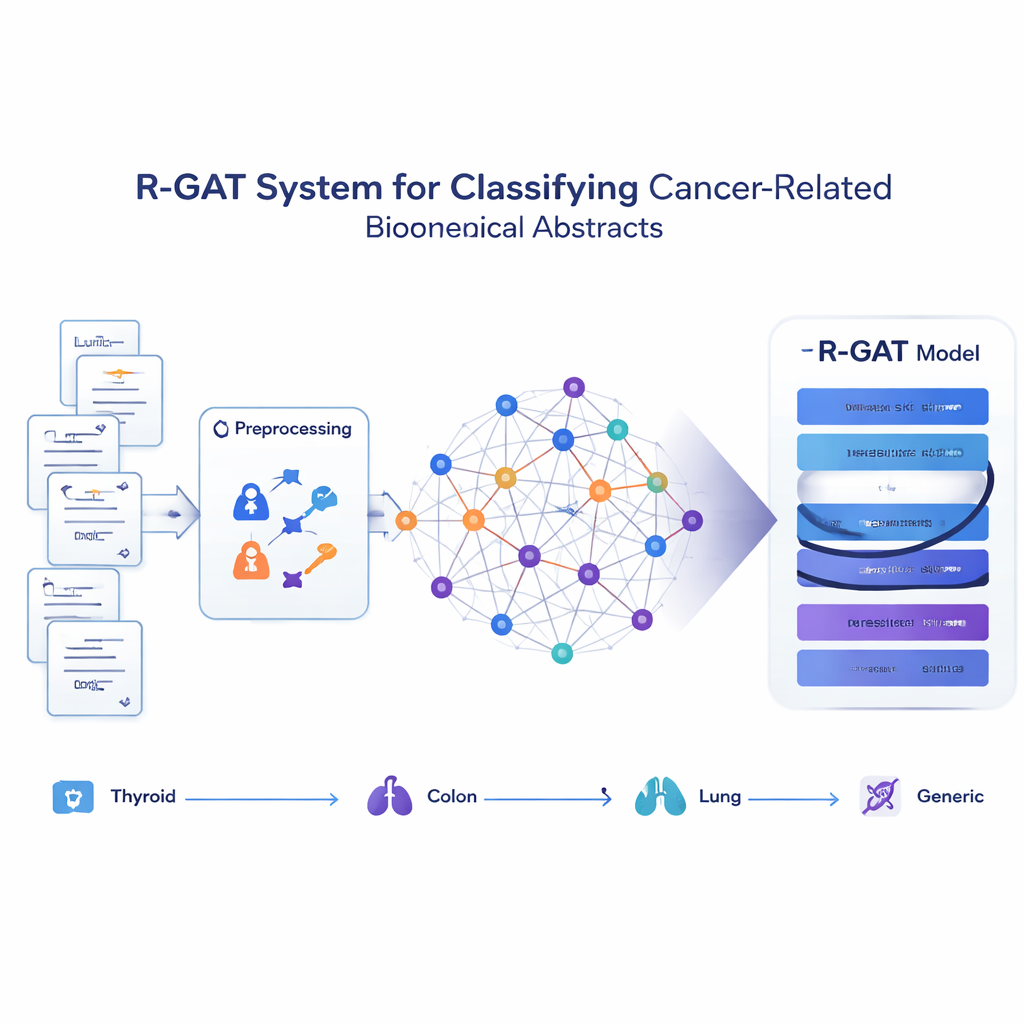
把论文变成一个思想网络
与其把每个摘要视为孤立的词串,所提出的方法R-GAT(残差图注意力网络)将整个集合视作一个网络。在该网络中,每篇摘要是一个节点,连接则表示两篇摘要在内容上的相似度。如果两篇论文讨论的主题密切相关,它们之间的链接就很强;否则链接就弱或不存在。这样模型可以在邻居的语境中考察某篇摘要,类似于人类读者通过了解相关工作来更好地理解一项研究。
新模型如何从邻居中学习
R-GAT基于现代人工智能的两个关键思想:注意力和残差连接。注意力机制使模型能够更关注图中最相关的邻居摘要,而非将所有邻居一视同仁。多个注意力“头”同时寻找不同类型的模式。残差连接则像捷径一样在网络更深的层之间传递信息,帮助模型在学习过程中避免丢失重要信号。经过若干注意力层和这些捷径路径处理图后,系统将整个网络的信息浓缩为一个紧凑的表征,并将其输入到最终的分类器中,以预测每篇摘要所属的四类之一。
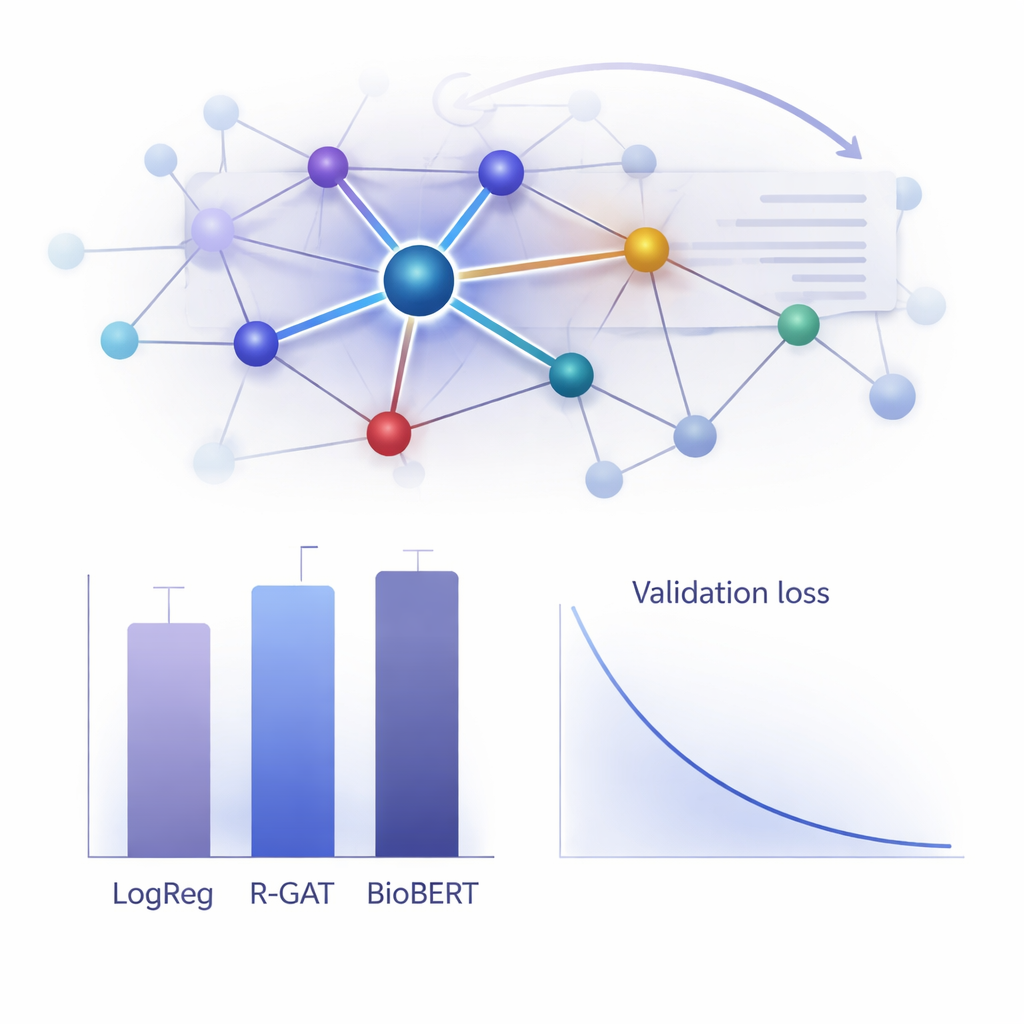
在实践中效果如何?
为了评估R-GAT的价值,作者将其与多种替代方法进行了比较,从经典的线性模型到像BioBERT这样的最先进变换器系统——后者虽受欢迎但计算开销大。令人惊讶的是,在该数据集上,使用词频特征的简单逻辑回归模型取得了最高的原始得分,BioBERT的表现也非常优秀——但两者都有缺点,包括对特定特征选择的依赖或对大量计算资源的需求。R-GAT取得了约0.96的宏F1分数,接近最佳模型,同时在不同的训练—测试划分上表现非常稳定。通过去掉注意力或残差连接的消融实验显示性能明显下降,证实这两种成分对于在数据有限时模型的鲁棒性至关重要。
这对未来癌症研究意味着什么
对普通读者来说,结论很明确:R-GAT是一个实用工具,能够在不依赖巨大数据集或昂贵硬件的情况下,以高且稳定的准确率按癌症类型对研究论文进行分类。它并不取代市场上最强大的语言模型,但提供了一个可靠的中间方案——特别适合在数据和预算受限的医院、研究团队或公共卫生机构,满足对可重复、可信结果的需求。作者还公开发布了他们的模型和经过策划的数据集,为他人构建和测试改进系统提供了共同基准。从长远看,这类工具可帮助专家更容易跟踪癌症文献并将新发现转化为更好的临床实践。
引用: Hossain, E., Nuzhat, T., Masum, S. et al. R-GAT: cancer document classification leveraging graph-based residual network for scenarios with limited data. Sci Rep 16, 6582 (2026). https://doi.org/10.1038/s41598-026-39894-6
关键词: 癌症信息学, 生物医学文本挖掘, 文档分类, 图神经网络, 有限数据学习