Clear Sky Science · zh
用于预测常染色体显性遗传性多囊肾病患者肾病分期的机器学习:日本全国队列研究
这对日常健康有何意义
肾脏疾病常常悄然发生,到出现症状时损害往往难以逆转。对于先天患有常染色体显性多囊肾病(ADPKD)的人——一种液囊逐渐挤占正常肾组织的疾病——了解肾功能可能衰竭的速度会影响重大的生活决策。本研究探讨现代计算技术(即机器学习)是否可以利用常规体检数据,在不依赖昂贵的基因检测或高级影像的情况下,预测个人在未来三年内肾功能的变化。
一种常见却结局不确定的疾病
ADPKD 是最常见的遗传性肾病之一,也是慢性肾脏病(CKD)的主要原因。许多患者最终需要透析或移植,但病情进展速度差异很大:有些人进展缓慢,老年仍保有较好的肾功能;另一些人则在四五十岁时即达肾衰竭。医生希望能尽早将患者分层,以便定制治疗和随访。现有的预测工具往往依赖详细的基因检测或完整的肾脏核磁共振成像,而这些在许多医疗体系(包括日本的国民保险)中并不普遍可得。正是这一缺口促使作者寻求一种更简单、可广泛应用的未来 CKD 分期评估方法。
将全国登记数据转化为预测工具
研究者利用了日本一项记录困难疾病并给予政府补助患者信息的全国登记系统。他们聚焦于 2015 至 2021 年间首次登记的 2,737 名成年 ADPKD 患者。对每位患者,团队收集了初次申请时的资料——包括血液检查结果、尿液检查、基本体征、血压和医生记录的肾脏大小——并查看该患者三年后的 CKD 分期。CKD 分期主要基于肾小球滤过率,是衡量病情严重程度的指标之一,同时在日本也是财政救助的关键标准。
计算机如何从患者数据中学习
为构建预测系统,科学家测试了三种常见的机器学习方法:随机森林、支持向量机和朴素贝叶斯。这些方法都是从实例中学习而非基于固定公式。数据集被划分为训练集(用于微调模型)和测试集(用于评估模型在未见病例上的表现)。计算机尝试预测每位患者三年后将达到的 CKD 分期。在测试中,随机森林方法表现最佳,约能正确预测 73% 的测试患者分期;支持向量机(主要假设因素与结局之间为线性关系)表现较差,朴素贝叶斯则位于二者之间。
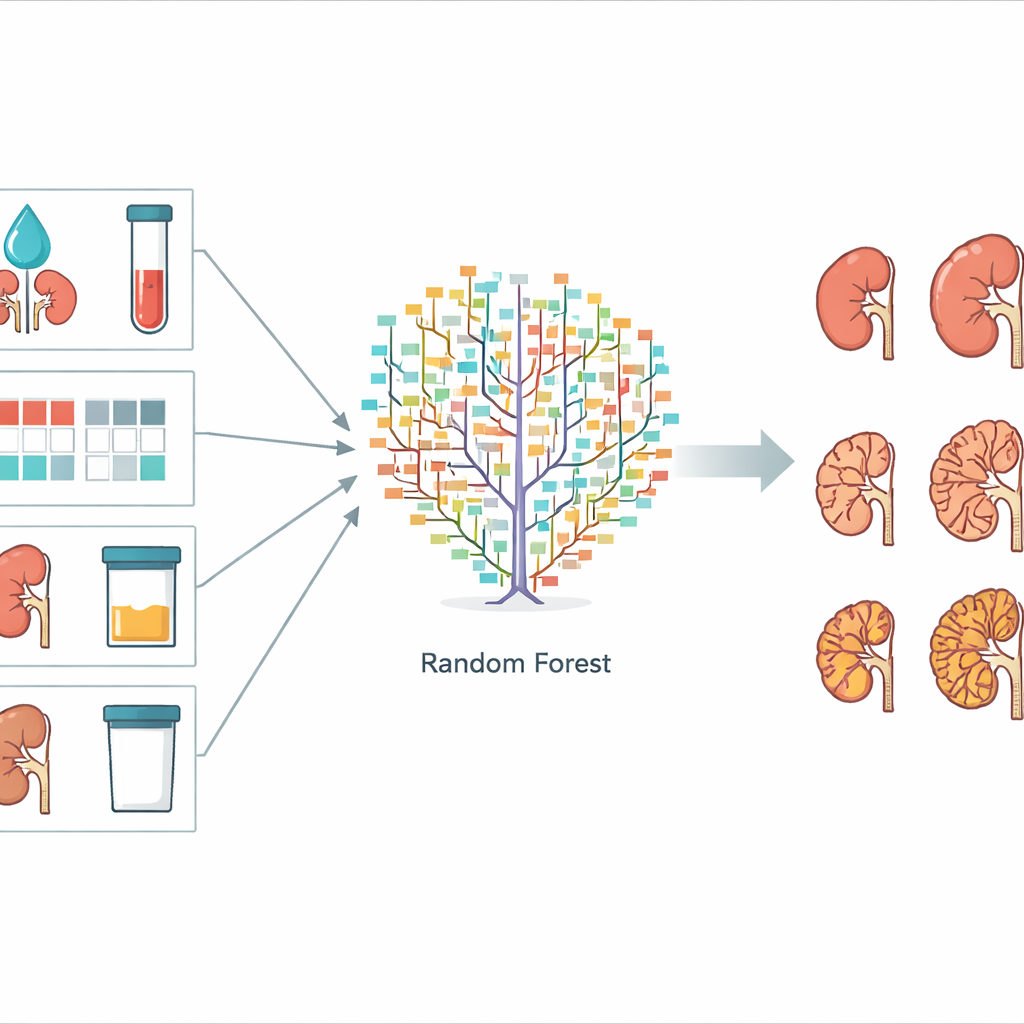
哪些因素对预测最重要
团队还评估了哪些信息对随机森林模型最有用。他们通过逐一打乱某个特征并观察预测准确性下降的幅度来衡量重要性。五个特征尤为突出:估算肾小球滤过率(eGFR)、血清肌酐水平(另一项肾功能指标)、将滤过率与尿蛋白结果结合的彩色 CKD “热图”、尿蛋白定量以及双肾总体积。这些均为普通门诊可采集的测量值,无需专门的影像文件或基因测序。相反,诸如影像上囊肿确切数量等项目的贡献较小,表明它们对实用的预测工具并非必要。
对患者与医生的意义
对 ADPKD 患者而言,研究表明用标准化验和基础影像摘要作为输入、经精心训练的计算模型可以在三年后给出相当准确的肾功能预报。由于表现最好的模型能够捕捉因素之间复杂的非线性关系,它可能比传统风险图表更适合这种终生且异质性大的疾病。尽管该研究仅限于日本患者且无法证明因果关系,但它指向了对临床友好的工具:帮助识别可能迅速恶化的人群与病程较慢的个体。简言之,文章认为机器学习——尤其是随机森林方法——可以将日常医疗数据转化为个体化的“肾脏未来”预览,从而支持更个体化的护理与更好的患者规划。
引用: Shimada, Y., Kataoka, H., Nishio, S. et al. Machine learning for predicting CKD stages in patients with autosomal dominant polycystic kidney disease: a nationwide cohort study in Japan. Sci Rep 16, 8771 (2026). https://doi.org/10.1038/s41598-026-39885-7
关键词: 多囊肾病, 慢性肾脏病, 机器学习, 风险预测, 个体化医疗