Clear Sky Science · zh
用于实时交通风险预测的自适应数据重平衡框架
为何对交通数据进行平衡对安全至关重要
与大量普通、无事故的行驶相比,高速公路碰撞是罕见事件。这对安全来说是好事,但对试图实时预测何时何地可能发生碰撞的计算机来说,这就产生了一个隐性问题。当数据以安全情形为主时,算法可能会变得非常擅长预测“不会发生任何事”,并在纸面上看起来很准确——但实际却悄悄错过真正危险的时刻。本研究正面应对这种不平衡,提出一种自适应的“重平衡”交通数据的方法,使警报系统能够更好地识别罕见但关键的风险情形,同时保持对真实世界使用的响应速度。
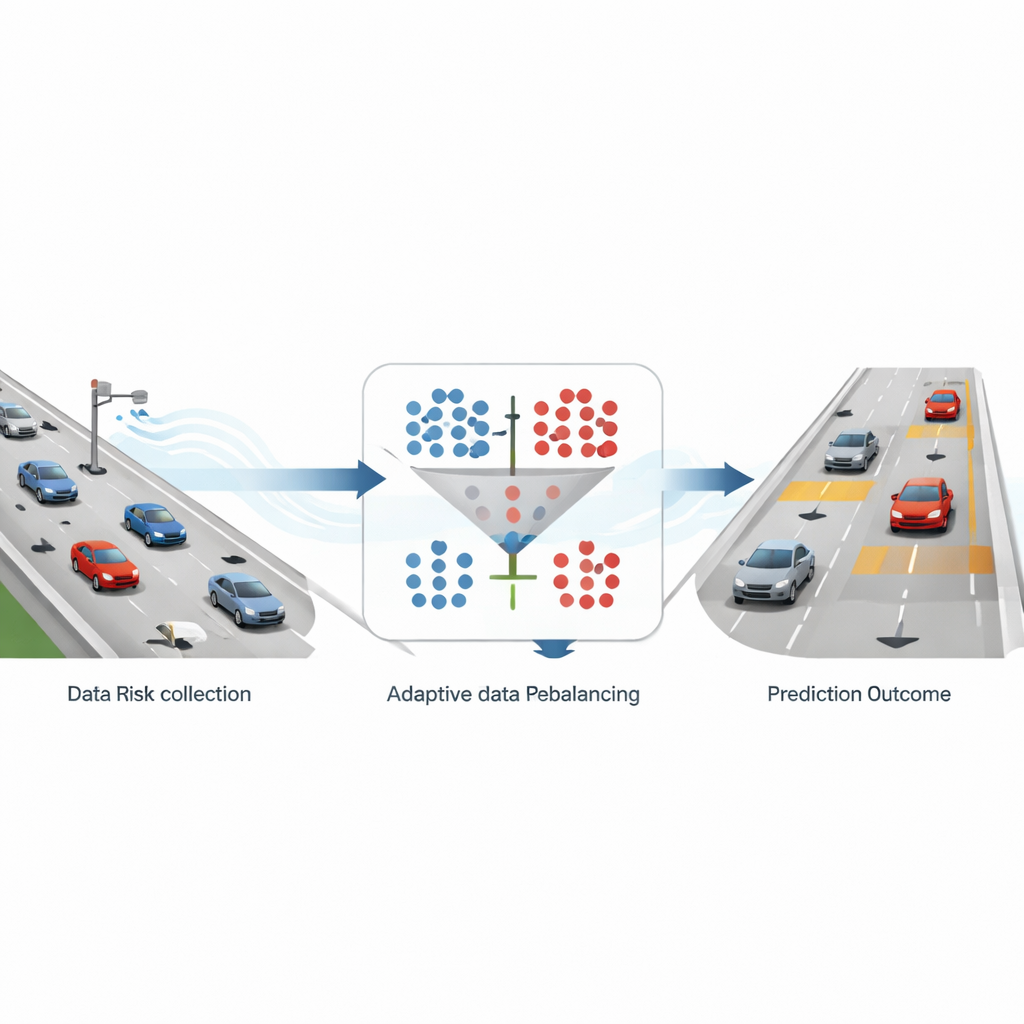
如何将真实交通转化为警报信号
研究人员基于来自德国高速公路的大型无人机轨迹数据集构建了他们的框架。每辆车的位置和速度以每秒多次的频率沿六车道路段被跟踪。基于这一丰富的运动记录,团队计算了一种广泛使用的安全指标——碰撞时间(time-to-collision),它估算若跟车与前车保持当前状态,发生碰撞还需要多长时间。当该时间低于三秒时,该情形被标记为“高风险”;否则视为“非风险”。在将这些度量按10秒片段汇总并聚焦于六车道道路后,他们得到的样本大约是每个高风险样本对应约九个安全样本,这一强烈偏斜的数据集反映了真实高速公路的状况。
在不丢失重要信息的前提下修正偏斜
为了解决这种偏斜,研究比较了两种常见策略。一种称为过采样,它通过生成与真实高风险案例相似的合成样本来增加稀有高风险情形的数量。另一种是欠采样,通过随机丢弃部分大量的安全样本来缩减安全类。作者使用了一种流行的过采样方法(SMOTE)和一种简单的随机欠采样方法,在安全与风险样本比为1:1、2:1、3:1和4:1的若干固定比例上应用它们。然后他们将原始数据和被调整的数据分别输入四种预测模型:两种传统的机器学习方法和两种擅长处理时间序列的深度学习模型。通过测试所有这些组合,可以观察不同数据平衡方式如何在提高系统识别风险能力的同时保持对安全情形的识别。
让算法为最佳平衡进行搜索
研究者没有假定完全相等的安全与风险样本数量就是最佳,而是让一种受进化启发的搜索方法——遗传算法——去寻找最有效的平衡。该优化器在1:1到4:1的现实范围内调整安全对风险的比例,反复生成候选比例、评估并在数百次迭代中加以改进。关键是,它不仅仅看预测准确度:还考虑模型训练和预测所需的时间,以反映交通控制中心的实时需求。为确保准确度与计算时间可公平地合并,所有衡量指标在被融合成单一“适应度”分数前都进行了归一化,算法尝试最小化该分数。
模型从道路风险中学到的东西
在众多实验中,一个模式格外突出。与保持原始偏斜相比,平衡数据可以改善风险预测,而通过生成合成高风险样本的过采样通常比丢弃安全样本的欠采样效果更好。在固定设置中,安全与风险样本比为2:1时表现最佳,优于常用的1:1选择。当允许遗传算法微调该比例时,它收敛到略有不均但更优的值——过采样约为2.3:1,欠采样约为2.7:1。在预测模型中,一种称为门控循环单元(GRU)的循环神经网络在多个组合下持续提供最强的结果,尤其在与过采样和优化配合时表现突出。模型还揭示了,高速公路某点上下游的平均车速比单纯的车辆计数对风险更具信息量。
检查稳定性并为现实部署做准备
由于优化方法有时可能陷入误导性的解,作者检查了他们的搜索随时间的行为。他们展示了适应度分数稳定下降并最终趋于平缓,这表明算法正在收敛到稳定、高质量的比例,而不是在解空间中来回跳动。随后他们将选定比例上下微调几个百分点以观察性能是否崩溃。实际上,准确度在小幅变化下仅轻微下降,表明系统具有鲁棒性,不会过度依赖单一脆弱的设置。然而,当用于测试的数据比例非常大时,模型变得更敏感,这凸显了丰富训练数据的必要性。
这对更安全、更智能的高速公路意味着什么
通俗来说,这项研究表明,让计算机识别道路危险不仅仅关乎巧妙的模型设计,还关乎为模型提供对罕见但关键事件的公正视角。通过谨慎调整训练中安全与风险样本的数量——并让自适应算法在准确性与速度之间找到最佳折衷——所提出的框架使实时高速公路风险预测更可靠也更实用。交通管理机构可以将这一方法嵌入监测交通检测器数据并对潜在追尾碰撞发出早期警报的系统中,从而辅助驾驶员提示、巡逻部署或自动制动策略。尽管该工作在德国高速公路的良好天气条件下进行演示,但自适应数据平衡的基本思路为在危险事件罕见但又不容错过的任何场景中改进安全预测提供了通用方案。
引用: Chen, S., Cui, B. & Chang, A. An adaptive data rebalancing framework for real-time traffic risk prediction. Sci Rep 16, 8882 (2026). https://doi.org/10.1038/s41598-026-39539-8
关键词: 交通安全, 碰撞风险预测, 不平衡数据, 机器学习, 高速公路轨迹