Clear Sky Science · zh
只用2D编码器的数据高效3D医学视觉-语言模型
来自3D扫描的更聪明帮助
当医生阅览CT或MRI扫描时,他们并不只是看单张图片——而是将数百张切片在脑中拼接起来,以三维方式理解病变。教会计算机做同样的事可以支持更快、更一致的诊断并为患者生成更清晰的报告。但当前处理3D扫描的人工智能系统极为“需数据”,需要大量、精心标注的数据集,而许多医院根本没有这样的数据。本文提出了一种方法,能用现有的2D图像技术获得3D级别的理解,承诺构建和部署更强大且成本更低的工具。
为何3D扫描对AI来说困难
现代的“视觉—语言”系统已经可以查看2D医学图像并回答问题或撰写通俗的报告。将这种能力扩展到3D体积可以让AI对完整器官和仅在多张切片联合查看时才明显的细微病变进行推理。问题在于,大多数现有的3D系统依赖于从零训练的特殊3D图像编码器,这些编码器需要在海量标注扫描上训练。这类数据集稀缺、标注昂贵,且通常集中在资金充足的中心,从而限制了受益者。同时,仅把每张切片当作单独2D图像处理会丢失切片间的自然连续性,并使模型面对大量重复信息。
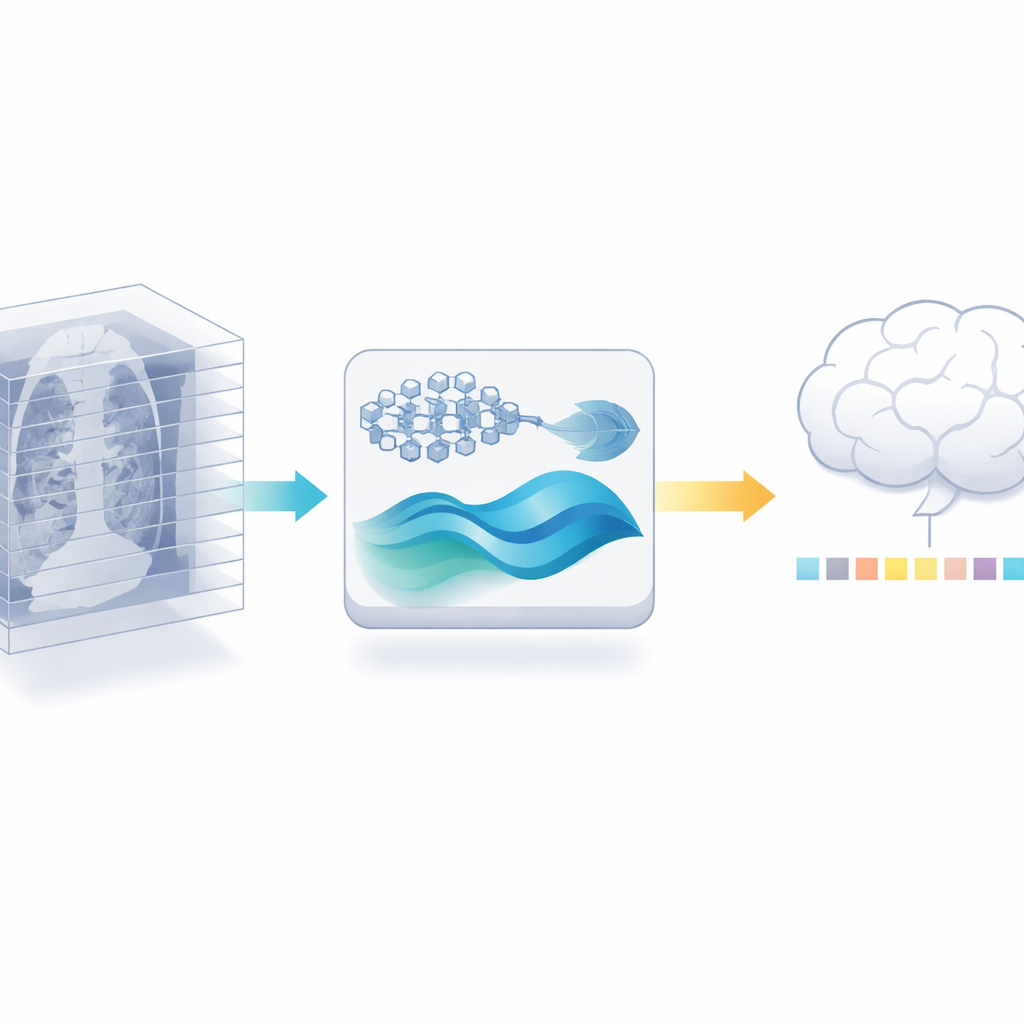
把2D专家“回收”用于3D任务
作者提出了一条不同路径:不是训练新的3D编码器,而是重用已经在医学文献上数百万张标注图像上训练好的强大2D医学图像模型。首先将每个3D扫描切成独立切片,让该2D模型对每张切片提取详细特征。然后谨慎地去除冗余:由于相邻切片往往非常相似,一种相似性检测可以丢弃许多近重复图像,同时保留信息量最大的视图。仅此一步就减少了后续阶段必须处理的数据量,而无需更多标注扫描。
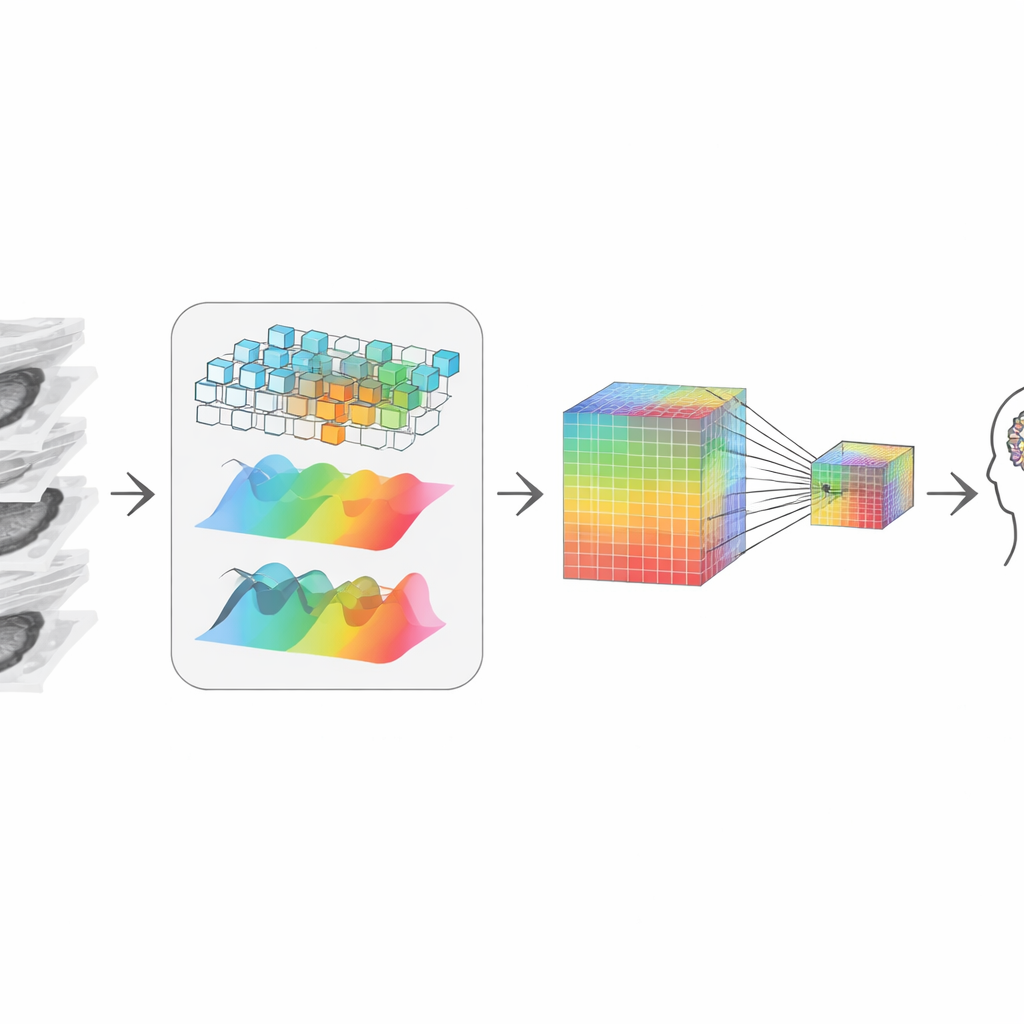
从碎片重建3D全貌
在裁剪之后,系统需要将剩余切片“重新缝合”成一致的3D图像。作者通过结合两种互补的数据视角来实现这一点。一条路径关注局部形状和边缘,像在体积中移动的放大镜,敏感于清晰的边界和纹理。另一条路径将数据转换为频域视角,更擅长捕捉跨切片的宏观模式和长程结构——例如肿瘤如何延伸或器官的整体形状。一个自适应融合步骤学习在每一点上应信任哪种视角,从而得到既尊重细节又兼顾全局语境的表示,尽管起点只是2D切片。
在压缩中保留微小线索
要与大型语言模型对话——即回答问题与生成报告的部分——视觉信息必须压缩成适量的token或“视觉词”。简单缩小会抹去微小但关键的信号,比如对诊断重要的小钙化点或细微纹理变化。为避免这一点,作者构建了双轨表示:一路保留高分辨率、细节丰富的版本,另一路是更小更廉价的版本。注意力机制使得较小版本中的每个点可以选择性地“回看”较大版本并提取最清晰的细节。其结果是兼具压缩性与保留放射科医生关心线索的紧凑视觉摘要,随后传给语言模型进行推理。
在真实医学任务上的验证
为检验其设计,研究人员在公开的3D基准上进行了评估,这些基准关注两件事:系统能否撰写准确的放射学风格的3D扫描描述,以及能否就扫描中可见内容回答问题。尽管从未训练专门的3D编码器,他们的方法在这两项任务上都超过了若干优秀的基于3D的模型。它生成了更精确、临床信息更丰富的报告,并更准确地回答问题,包括关于具体器官、异常或位置的难题。此外其运行更快、所需3D训练数据远少,并能很好地泛化到MRI和PET等不同扫描类型。
对未来医疗的意义
用通俗的话说,这项工作表明我们不必从头开始建立数据饥渴的3D模型,就能在体积扫描上获得高质量的AI帮助。通过巧妙回收强大的2D专家、精心选择信息性切片,并在重构3D图像时保留微小细节,作者以更少的数据和计算实现了最先进的性能。如果被广泛采纳,这类方法可以让先进的AI辅助——例如更好的报告、更清晰的解释和更可靠的分诊——对缺乏大规模数据资源的医院和诊所可用,将复杂成像分析更接近常规临床实践。
引用: Lian, Y., Xie, Y., Jiang, Y. et al. A data-efficient 3D medical vision-language model using only a 2D encoder. Sci Rep 16, 8809 (2026). https://doi.org/10.1038/s41598-026-39526-z
关键词: 3D医学成像, 视觉-语言模型, 放射学人工智能, 数据高效学习, CT与MRI分析