Clear Sky Science · zh
基于面部皮肤标记的同卵双胞胎生物识别差异化:动态特征增强
为何细小的皮肤细节很重要
我们大多数人都认为同卵双胞胎就是“完全相同”——相似到连高端相机和 DNA 检测都难以区分。这种相似性在现实情境中带来严重问题,从破案到边境安检都会受到影响。研究表明,解决办法可能就在我们很少注意到的地方:分布在面部的小而稳定的痕迹与斑点。研究人员将这些痣、斑点和毛孔视为一种“皮肤地图”,据此构建了一个自动化系统,能够可靠地区分同卵双胞胎,这为更精确且可解释的生物识别工具指明了方向。
从混淆的面容到清晰的皮肤地图
传统的人脸识别系统侧重于整体面部结构——眼间距、鼻型、下颌轮廓等。对于同卵双胞胎来说,这些特征几乎如出一辙,这也是为何即便是先进算法和 DNA 分析也常常无法断定哪位是哪个双胞胎。作者转而关注面部皮肤上那些微小且大致恒定的细节:痤疮疤痕、色斑、毛孔和皱纹。这些标记随着个人一生形成独特的分布模式,即便在基因几乎相同的人之间亦是如此。核心思想既简单又有力:双胞胎的面容乍看相同,但他们的皮肤标记星座并不相同。
系统如何看到我们忽略的细节
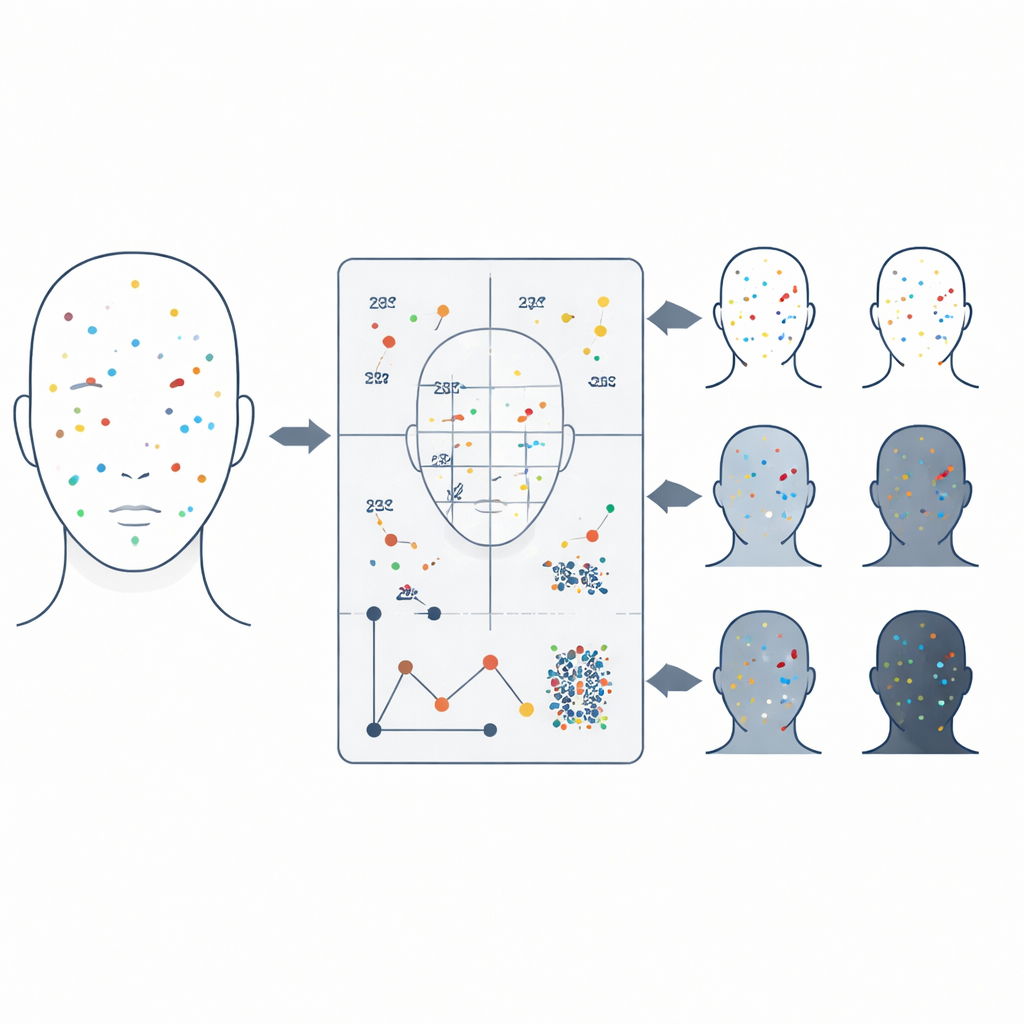
研究团队使用来自一个知名研究集的 74 对双胞胎的 319 张面部照片。首先,他们用预训练的计算机视觉模型扫描每张面孔,检测不同类型的皮肤特征——例如痤疮、黑眼圈或毛孔——并在每个特征周围绘制隐形边界框。关键在于,他们将检测器设置得非常灵敏,愿意捕捉到即便微弱的标记,尽管这也会带来一些噪声。研究并不单独信任每一次检测结果,而是将所有标记汇总为每个人的丰富档案:每类标记的数量、它们的聚集程度、在面部的分布以及平均大小等。
将皮肤模式转化为双胞胎判断
接下来,研究者在成对图像之间比较这些皮肤档案——有时是同卵双胞胎的照片,有时是无关人员的照片——以测量它们有多相似或不同。他们结合了若干直观的比较步骤:标记类型的组合匹配程度、标记总体大小的相似性、标记在左右或上下脸部之间的分布差异,以及标记在空间上的排列方式,包括它们与面部中心的距离和聚集强度。将这些相似性分数输入到一个机器学习模型中,模型学习回答一个是/否问题:这两张脸是否属于同一对双胞胎?
聪明的调参而非浪费时间
构建这样的分类器不仅关乎提供给它的信息,也关乎如何调整其众多内部“旋钮”,比如允许模型变得多复杂。研究系统性地比较了四种不同的策略来搜索最佳设置,范围从穷尽性的网格搜索到受随机采样和自然界群体行为启发的更具探索性的算法。尽管一种基于群体的算法在测试时在原始准确率上略占优势,但更简单的随机搜索在用时仅为很小一部分的情况下达到了几乎相同的性能。该平衡在实践中至关重要:既准确又高效的系统更有可能在警方实验室、边检点或医学研究中得到应用。
皮肤如何揭示身份
总体而言,该框架在交叉验证中达到约 96.6% 的准确率,并在衡量其将双胞胎与非双胞胎区分开来的测试中取得了强劲成绩,且几乎没有过拟合迹象。最具决定性的信号并不是人们拥有哪些类型的标记,而是这些标记出现在面部的位置——空间模式像是独特的签名。标记类型的计数、面部区域之间的差异以及微妙的聚集模式为判断增加了额外可靠性。重要的是,系统的决策可以被可视化和解释,让调查人员看到是哪部分皮肤地图促成了匹配或不匹配。对普通读者而言,这一信息发人深省:即便是在我们所知最相似的人类中,皮肤也在悄然记录足够的个体细节,让机器能将他们区分开来,这为更公正的法庭审理、更安全的生物识别以及研究环境如何随时间塑造我们外貌的新方法打开了大门。
引用: Brahmbhatt, K.J., Prakasha, K. & Sanil, G. Facial mark based biometric differentiation of identical twins using dynamic feature enhancement. Sci Rep 16, 9249 (2026). https://doi.org/10.1038/s41598-026-39470-y
关键词: 同卵双胞胎, 面部生物识别, 皮肤标记, 法医识别, 机器学习