Clear Sky Science · zh
基于基因的解析学习模型用于准确的乳腺癌诊断
这项研究对患者与家庭的重要性
乳腺癌已成为全球女性中诊断最常见的癌症,而在纸面上看起来相同的病例,患者的结局却可能大相径庭。本研究展示了如何将成千上万基因的模式与精心设计的人工智能系统结合,帮助医生更可靠地区分谁患有癌症及其可能的严重程度——仅基于真实患者数据和一组紧凑的关键基因。
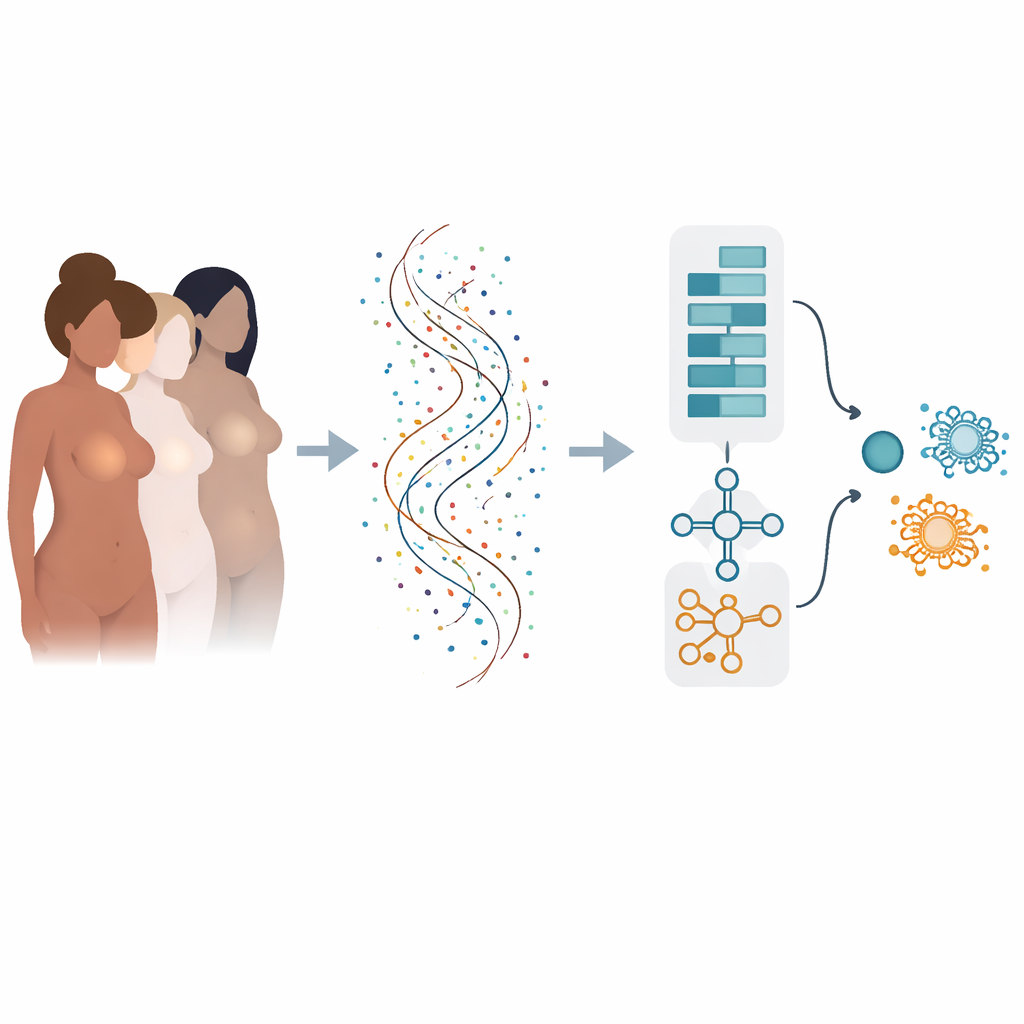
从众多风险因素到基因的语言
乳腺癌的风险受多种因素影响:遗传基因变化、激素、体重、生活方式等等。一旦癌症出现,其行为由每个肿瘤内部哪些基因被打开或关闭所驱动。现代测序技术可以同时测量数以万计的基因活性,但将这片数字海洋转化为明确的诊断和预后二元判断并不容易。传统计算方法常常逐个基因地考察,可能忽略基因群体协同作用,或仅在单一数据集上表现良好,而在外部测试时失效。
教一个“双脑”模型解读基因模式
作者构建了一个“混合”深度学习模型,有点像两个专门“大脑”协同工作。一部分受图像分析启发,扫描有序的基因列表以发现局部模式——即一组基因的联合活性指示癌症。另一部分将相同的基因视为序列,学习早期“驱动”基因与后续“下游”基因在列表中如何相互影响。通过结合这两种视角,模型既能捕捉短程也能捕捉远程的基因关联,反映肿瘤遗传指纹中的多尺度关系。
寻找稳定的核心信号基因集
研究团队没有将全部17,815个测量基因输入模型,而是设计了严格的“无泄漏”流程,仅选择最有信息量的基因。通过在重复交叉验证循环中使用标准相关性度量,他们反复按基因与癌症状态关联强度进行排序。然后仅保留在所有训练划分中持续位列前列的基因,最终得到一个稳定的236基因特征集。研究者还绘制了这些基因之间的相互作用网络,显示许多基因形成与肿瘤生长、代谢、免疫及微环境相关的紧密连接网络——这些证据表明所选基因集反映了真实生物学信号,而非随机噪声。
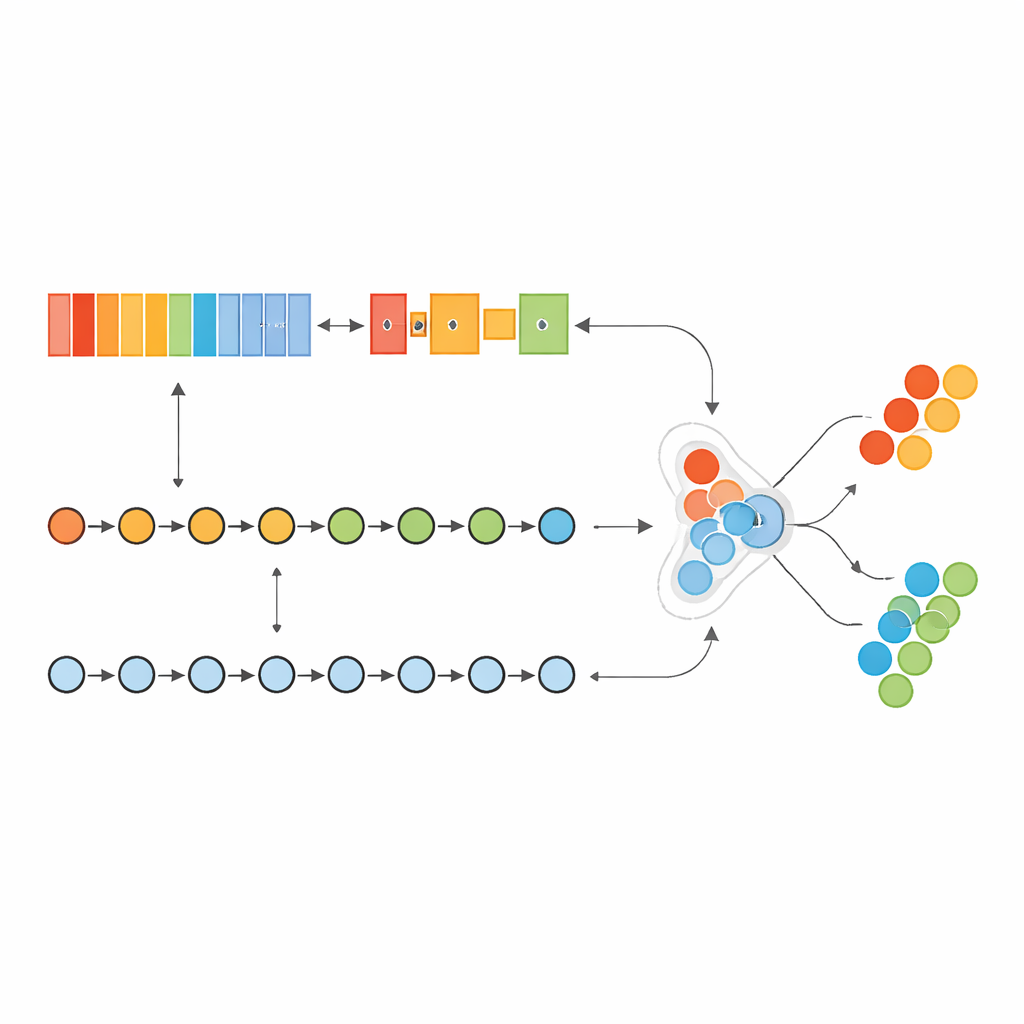
对模型进行检验
该混合系统在癌症基因组图谱(The Cancer Genome Atlas)中的乳腺癌样本上进行了训练与调参,然后用一个完全独立的数据集METABRIC进行挑战。为应对癌症样本远多于正常样本的情况,作者没有合成数据,而是调整模型对稀有类别错误的重视程度。经过自动化的超参数搜索,模型在主要数据集上达到了近乎完美的得分,几乎正确识别了所有癌症病例并几乎没有误报。重要的是,当模型应用于外部的METABRIC队列时,性能仍然保持极高且非常稳定,这表明该方法有可能超越单一研究或医院而具备泛化能力。
对未来护理的意义
简言之,这项工作提供了一个精细调校的双部分人工智能系统,它读取一个紧凑的236基因编码,以在嘈杂条件下仍能以卓越的准确性和一致性区分乳腺癌与非癌样本。尽管当前研究仅关注基因活性并使用回顾性患者数据,其方法为未来结合多种数据类型(例如组织图像和其他分子层面)并提供每次预测中哪些基因起主导作用的清晰解释奠定了基础。经过进一步的前瞻性临床验证,这样的系统有望成为精准乳腺癌诊断的通用骨干,帮助医生根据每位患者肿瘤的基因“签名”定制治疗方案。
引用: Hesham, F., Abbassy, M.M. & Abdalla, M. Gene driven analytical learning model for accurate breast cancer diagnosis. Sci Rep 16, 8155 (2026). https://doi.org/10.1038/s41598-026-39430-6
关键词: 乳腺癌诊断, 基因表达, 深度学习, CNN-BiLSTM, 精准肿瘤学