Clear Sky Science · zh
用于光子液态机计算的级联干涉仪-微谐振器结构
把光变为超高速的问题解决器
现代生活依赖数据:从流媒体视频到高速互联网骨干网,我们不断推动电子设备更快地传输信息。但传统芯片在不发热或不浪费大量能量的情况下难以跟上。本文探讨了一种不同的思路——在芯片上用光来承担部分计算。作者展示了如何通过巧妙组合微小光学电路来处理复杂的时变信号,达到数十亿次每秒的运算速度,同时比先前设计更简单、更实用。
把物理技巧变成会“思考”的机器
这项研究的核心思想是一种称为“液态机计算”的方法。与其构建一个大型、精心连线的神经网络,不如把输入信号送入一个固定且复杂的系统——在这里,是芯片上的微小光学元件网络。由于光波在网络内的干涉和混叠,系统会自发地把输入转化为丰富的内部态模式。输出处的一个简单电子电路学会如何组合这些状态,以进行预测或分类,例如机器学习基准中的复杂时间序列或光纤链路中失真的数据流。
为什么此前的光子方案遇到速度瓶颈
早期的光学液态机常依赖硅微环谐振器的固有非线性效应——这些显微级的环形轨道能够束缚并延迟光。在这些器件中,强光会改变材料性质,从而改变谐振器的行为。虽然这提供了计算所需的非线性,但关键效应与缓慢的物理过程相关,例如载流子移动和热流,这些过程在十亿分之一到百亿分之一秒量级展开。为配合这些缓慢时间尺度,工程师必须在芯片上加入长延迟线,这些延迟线制造困难、损耗大,并最终限制整体处理速度。
更简单、更快的方法:保持光学线性,把非线性放到边缘
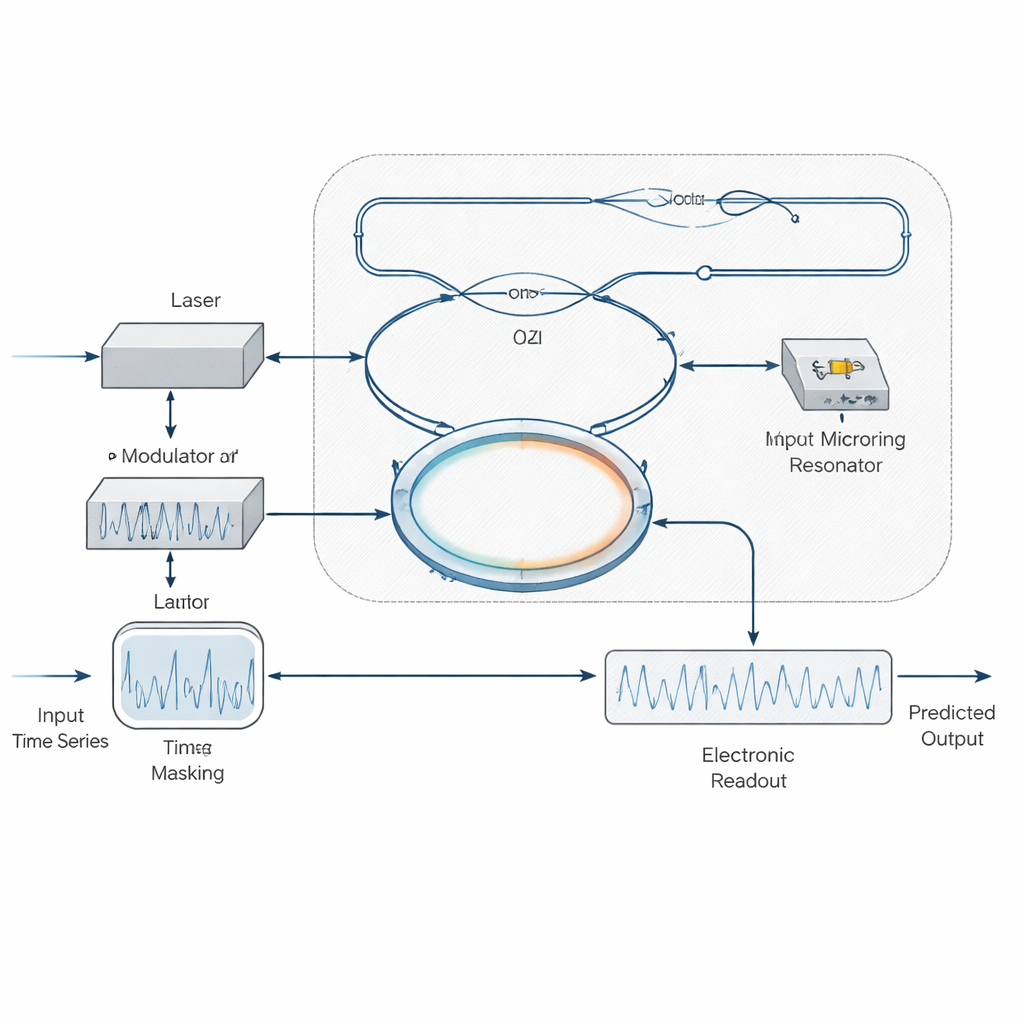
作者提出了不同的策略:在纯线性工作区运行微环谐振器,使用极低光功率以避免那些缓慢的材料变化触发。不是让谐振器本身表现出非线性,而是把非线性放在调制和探测阶段。一束连续波激光首先被加上掩码化的输入信号——通过改变光的强度或相位——然后送入片上干涉仪(马赫–曾德结构),随后经过微环。这些线性元件产生多份延迟和滤波的信号副本并相互干涉。当这种复杂的光学模式到达光电探测器时,探测器自然将场强转换为强度,从而“免费”地产生所需的非线性。随后一个电子读出层学习如何混合当前与过去的探测样本,有效地在光学和电子之间分担记忆职责。
构建紧凑的光学“短期记忆”
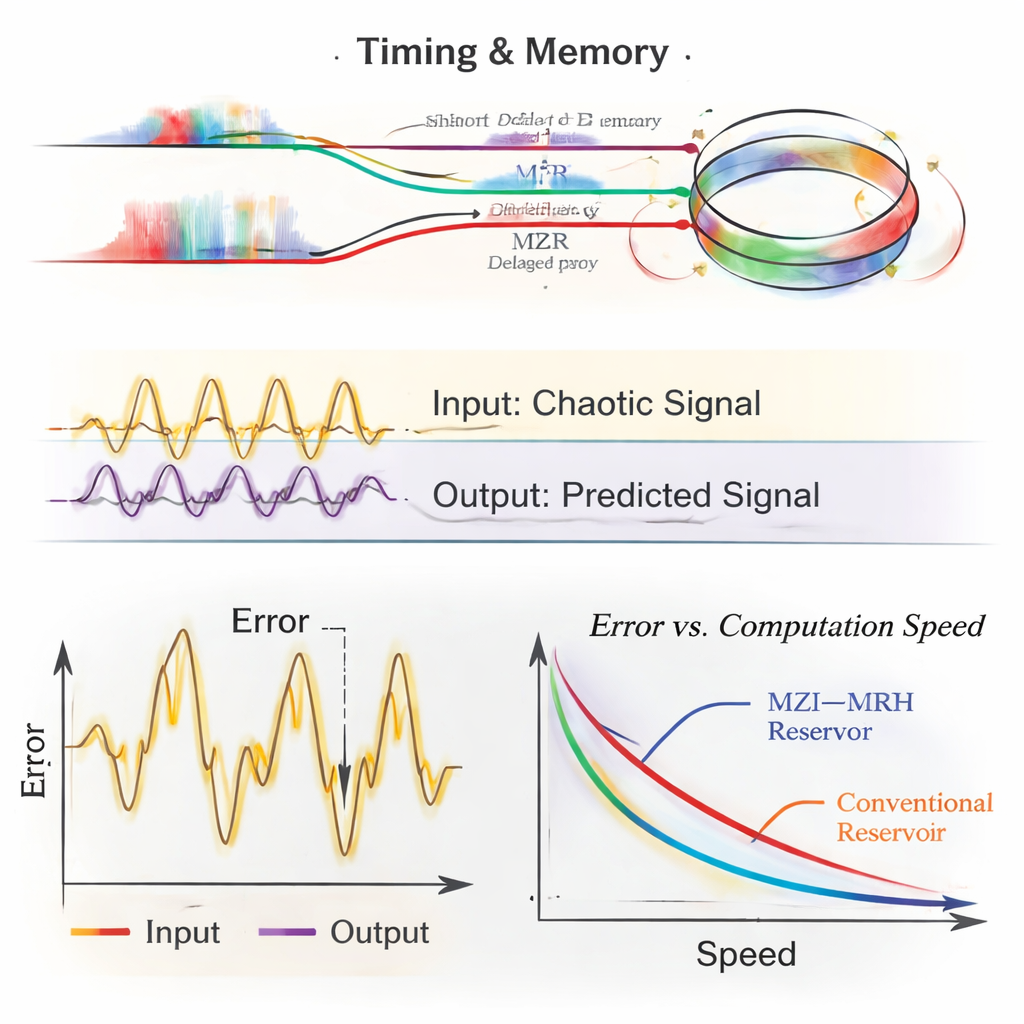
为展示其设计能力,研究者模拟了由不平衡马赫–曾德干涉仪与微环谐振器级联而成的液态机。通过仔细选择一臂相对于另一臂的长度差,以及谐振器与总线波导的耦合强度,他们调节输入不同“时刻”之间能相互作用的程度。他们还研究了数字掩码长度和电子读出中样本数量如何影响性能。使用短掩码和相对适中的电子记忆,他们的系统准确地解决了标准预测挑战,例如 NARMA-10、Mackey–Glass 和 Santa Fe 时间序列任务,在约 8 到 25 吉赫兹的有效计算速度下实现低误差——比许多早期的硅基光学液态机快多达一个数量级。
清理真实世界的光通信信号
除了抽象基准外,团队将他们的液态机应用于现实的光纤通信场景:一个 112-Gbaud、四电平脉冲振幅调制(PAM-4)的 O 波段链路,类似于为 800-Gigabit 以太网标准化的系统。这类链路受光纤色散和发射激光器引入失真的影响。在仿真中,新型光子液态机相比复杂度相当的传统数字前馈均衡器大幅降低比特误码率。它还能容忍更多累计色散——相当于将传输距离大约延长 15 公里而不越过常见的纠错阈值——同时将繁重的处理留在光学域中。
这对未来超高速计算意味着什么
通俗地说,这项研究展示了如何将简单的光学构件变成一个强大的高速“模拟预处理器”。通过避免缓慢的材料效应与长光学延迟,并依赖快速调制器、探测器以及智能的数字后处理,所提出的设计原则上可以用现有技术扩展到数十甚至上百吉赫兹。这可能使未来的数据中心和通信系统更快、更节能,紧凑的光子芯片作为前端协处理器,在数字电子学接管之前处理复杂的信号动态。
引用: Mataji-Kojouri, A., Kühl, S., Seifi Laleh, M. et al. A cascaded interferometer-microresonator structure for photonic reservoir computing. Sci Rep 16, 6492 (2026). https://doi.org/10.1038/s41598-026-39410-w
关键词: 光子液态机计算, 硅光子学, 微环谐振器, 光学信号处理, 高速通信