Clear Sky Science · zh
量子特征映射在基于量子核的机器学习中的比较性能分析
为何这超出实验室也很重要
随着数据和问题日益复杂,即便是当今最好的机器学习工具也可能难以发现清晰的模式。量子计算机承诺提供解决此类问题的新途径,但何时以及如何真正发挥作用仍不明朗。本文探讨了这一难题中的一个实用层面:如何设计和调优基于量子的分类器,使其能够在玩具问题和真实医学数据集上与成熟的经典方法竞争,甚至在某些情况下超越它们。
把相似性转化为量子优势
许多成功的学习方法(如支持向量机)依赖于“核”,它衡量在隐含映射到更丰富特征空间后两个数据点的相似程度。量子计算机可以通过将数据编码为量子态并比较两态的重叠来自然地实现这种映射。作者聚焦于这些量子核以及告诉量子电路如何把普通数值转换为量子态的“特征映射”。良好的特征映射能让纠缠的数据更易分离;糟糕的映射则浪费量子硬件资源。该工作提出两个关键问题:哪些特征映射效果最好,以及细致的调优能带来多少提升?
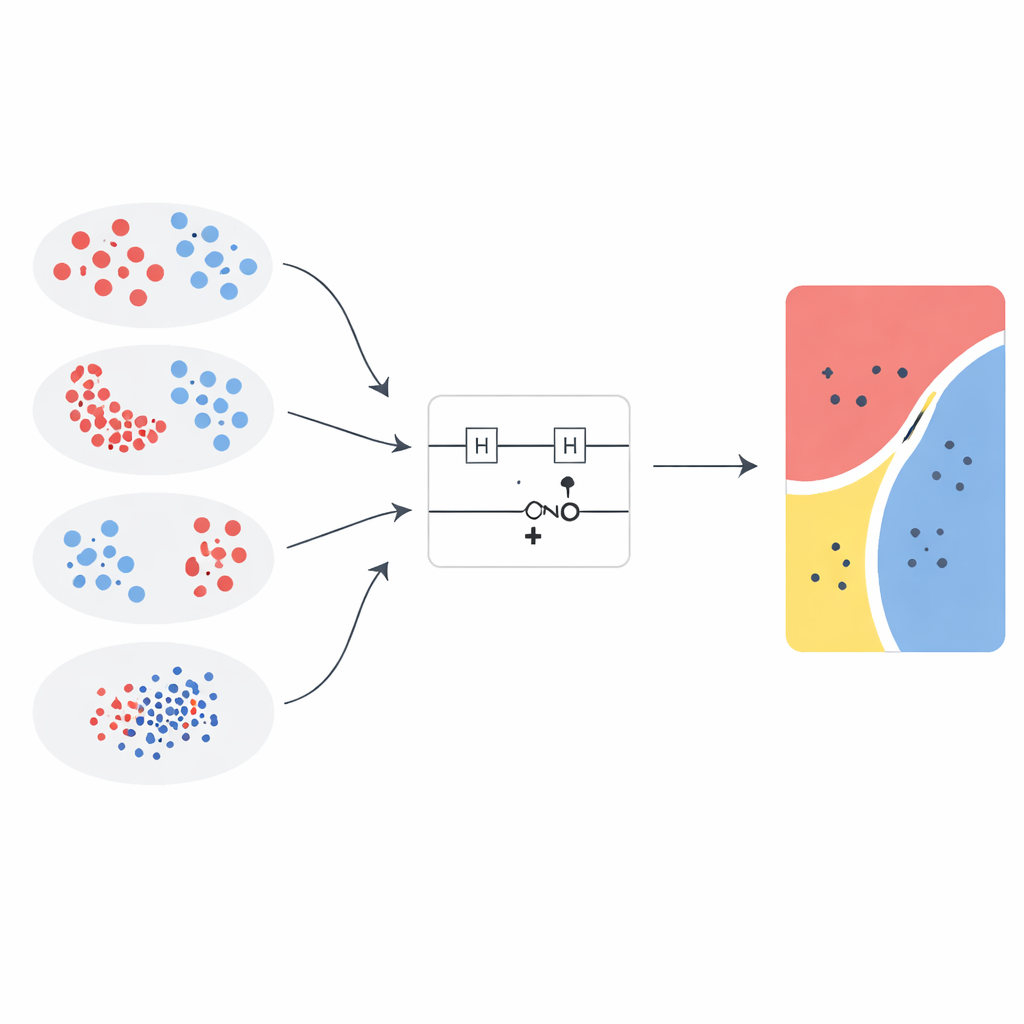
测试多种量子配方
研究者提出了一种新的高阶特征映射,并将其与此前工作的五种先进设计进行了比较。每种映射都使用一个简单的两量子比特电路,包含单量子比特旋转和纠缠门,但驱动这些旋转的数学公式各不相同。为保持研究的聚焦性,量子电路结构、支持向量机设置和评估流程均保持不变,仅在特征映射及其内部的“旋转强度”上做变动。这样便可以将性能提升直接归因于数据如何被编码进量子态,而非对周边经典学习算法的额外微调。
从玩具模式到癌症诊断
团队在三个经典的二维测试问题(同心圆、月牙形和异或模式)以及简化版的威斯康星乳腺癌诊断数据集上评估了量子核。对于医学数据,使用标准的特征选择方法挑选出两个最有信息量的影像特征。所有输入随后被重新缩放到相同范围并送入浅层的两量子比特电路,使实验对当今有噪声的中等规模量子设备仍具现实意义。性能与广泛的经典模型进行了比较,包括线性和径向基函数支持向量机、决策树、随机森林、提升方法、朴素贝叶斯、线性判别分析和多层感知器,并使用准确率和Matthews相关系数来同时衡量准确性与类别平衡。
比较结果揭示了什么
在较简单的基准数据集上,增强型量子核——尤其是由新特征映射和其中两种现有映射构建的——实现了近乎完美的分类,能够匹配或超越大多数经典竞争者。在更具挑战性的乳腺癌数据上,表现最好的量子特征映射仍然能与强劲的经典基线(如径向基函数核和神经网络)保持竞争力。一个关键参数是旋转因子,它刻度化输入值对量子旋转的影响强度。通过在多个值上扫描该因子,作者表明恰当选择该参数能显著提升性能,且最佳值依赖于数据集。对特征空间和决策边界的可视化清楚地显示出:有些映射刻画出精细且对齐良好的分隔区域,而另一些则留下扭曲或位置不佳的边界,这解释了性能差异的来源。
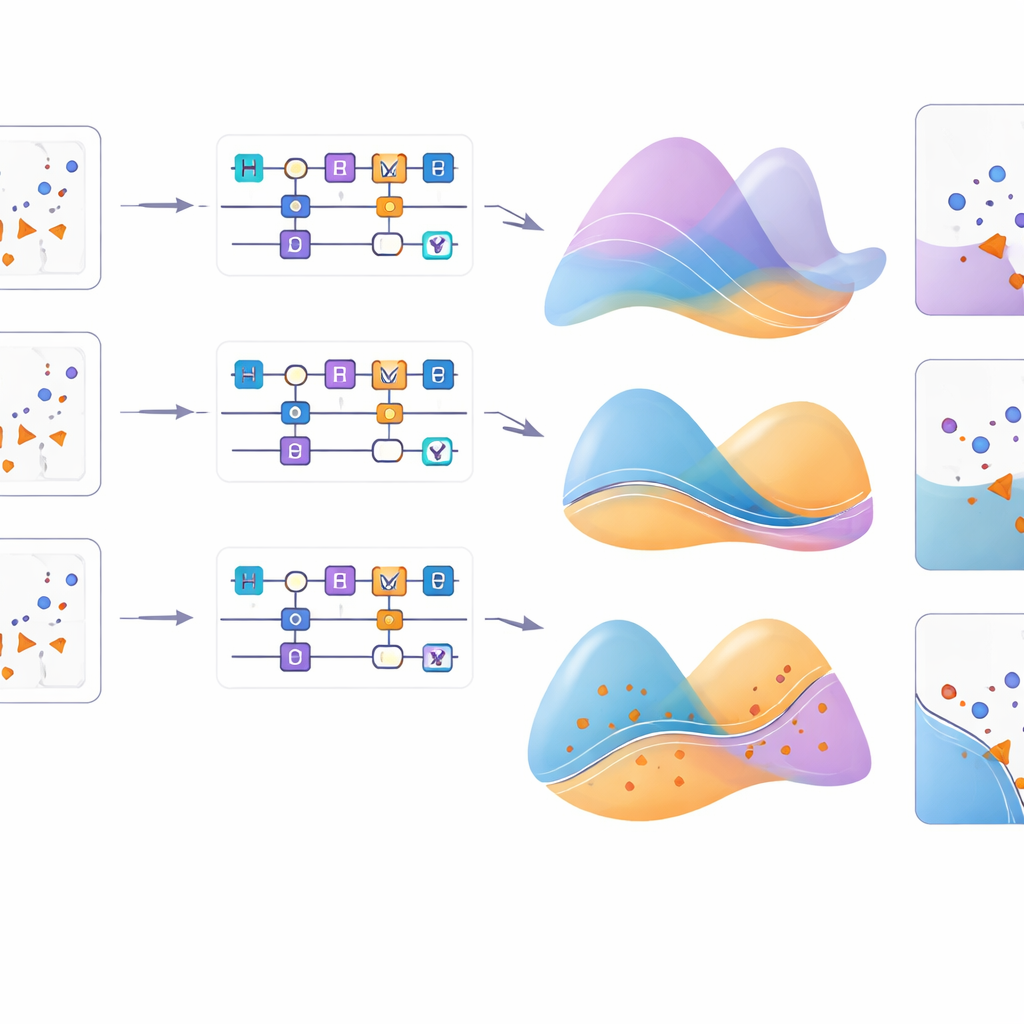
深入了解其工作机制
为更好理解这些效应,研究可视化了每种特征映射在不同问题上如何重塑输入点网格。对于圆形模式,大多数映射能成功重现底层结构,但对于月牙形和真实的癌症数据,只有部分映射能与真实分布良好对齐。附加实验改变了所用单量子比特旋转的类型,确认对于像异或这样的某些模式,旋转轴的选择可能与编码公式的细节同样重要。总体而言,新特征映射在配合合适旋转因子时始终名列前茅,突显了量子门、编码公式与超参数设置之间细腻的相互作用。
对未来的意义
对非专业读者而言,主要信息是:在机器学习中获得量子优势并不会“白白”到来——仅将标准模型放到量子硬件上运行并不足以保证成功。成功取决于为量子电路设计恰当的数据输入方式,以及调优若干关键设置,使量子态能够捕捉问题的结构。本文为使用量子核方法做到这一点提供了路线图,表明经过精心设计和调优的量子特征映射即便在非常小的电路中也能带来强劲、甚至优越的表现。与此同时,作者指出他们的结果基于无噪声的仿真和相对适中的数据集,因此在真实量子机器和更大规模上完全实现这些优势仍是未来工作的关键挑战。
引用: Jha, R.K., Kasabov, N., Bhattacharyya, S. et al. Comparative performance analysis of quantum feature maps for quantum kernel-based machine learning. Sci Rep 16, 8142 (2026). https://doi.org/10.1038/s41598-026-39392-9
关键词: 量子机器学习, 量子核, 特征映射, 超参数调优, 分类