Clear Sky Science · zh
CGDFNet:一种具有上下文引导细节融合的双分支实时语义分割网络
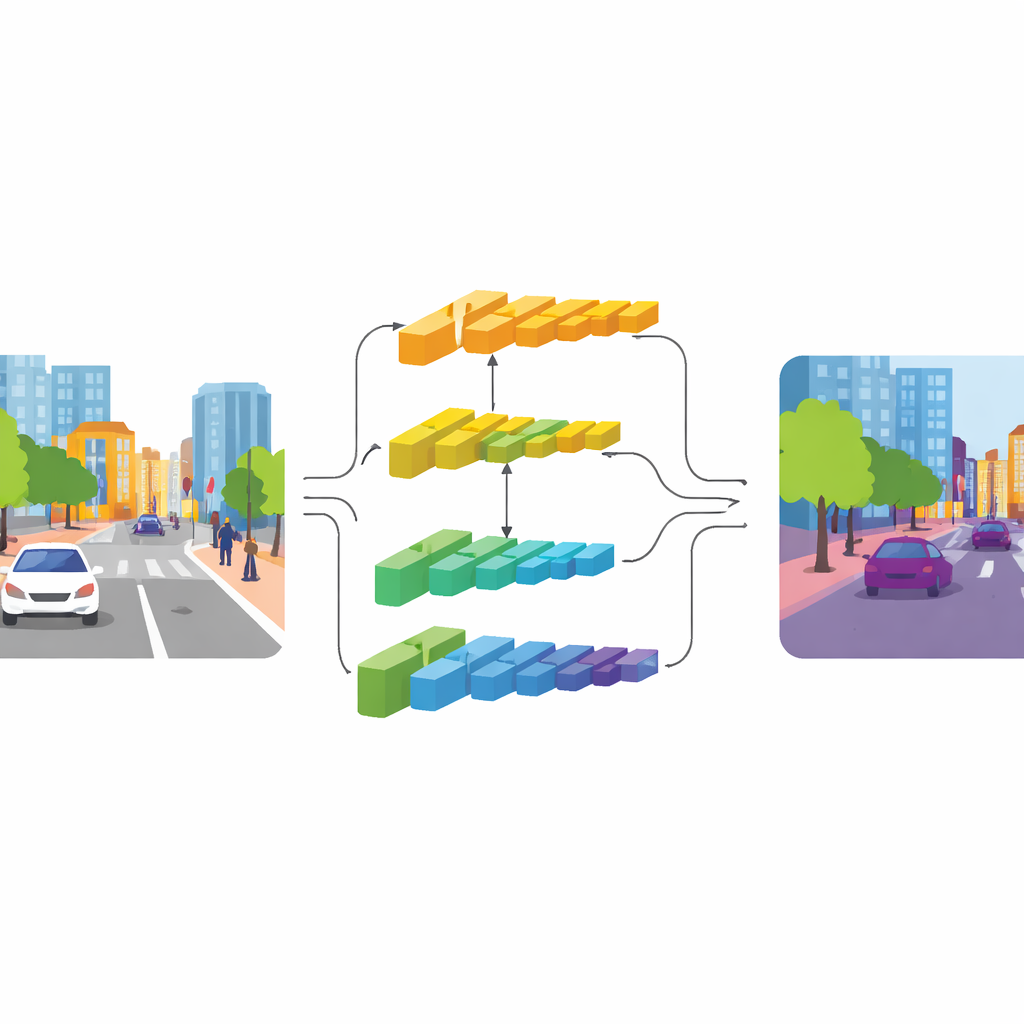
教会汽车“看见”整条街道
现代汽车和机器人越来越依赖摄像头来理解周围的环境——实时识别道路、人行道、行人、车辆和标志等。本论文提出了CGDFNet,一种旨在更快速、更准确地执行此类“场景理解”的计算机视觉系统,尤其适用于繁忙的城市街道。通过学习同时保留微小细节(如交通灯杆或自行车轮)与大尺度布局(如道路和建筑)两类信息,CGDFNet旨在使自动驾驶及其他实时视觉任务更安全、更可靠。
为什么像素级视觉如此苛刻
在语义分割中,计算机会为图像中的每个像素分配一个类别:道路、汽车、行人、天空等等。这远比简单地用一个框圈出一辆车要困难得多,因为系统必须以高精度描绘物体边界和小型形状。尽管存在许多高精度的方法,但它们往往速度慢且耗能大,这与汽车、无人机或可穿戴设备中的实时系统不相符。另一方面,运行快速的轻量级方法常常牺牲细节或丢失整体场景信息,在小物体、细长结构或拥挤的城市环境中难以表现良好。
两条路径:一条负责细节,一条负责语境
CGDFNet通过双分支设计来解决这一矛盾:一条分支专注于清晰细节,另一条捕捉宏观语境。基于高效的骨干网络,较浅的层为“细节分支”提供输入,保持较高分辨率以保留边缘和纹理;较深的层为“语境分支”提供更压缩的视野,有利于理解整体结构和对象间的关系。不同于早期主要将两条流分开处理再粗糙相加的双分支设计,CGDFNet鼓励它们在整个处理过程中相互交流,使得细节不断与网络对整体场景的理解相互校验。
用语义引导细节
两个关键组件强化了这种交互。在语境分支中,语义精炼模块(Semantic Refinement Module)学习突出其特征图中最具信息量的区域与通道。它通过结合局部线索(场景中哪些部分在彼此附近活跃)与全局线索(网络在整张图像中看到的内容),使得表征同时包含邻域细节与场景级意义。在细节分支中,语境引导细节模块(Context-Guided Detail Module)利用这些语义信息将注意力引向重要的边缘和细小结构,例如公交车轮廓或自行车车架。该模块依赖一种对相邻像素变化更敏感的特殊卷积,从而天然强调轮廓和小物体,且无需引入大量额外参数。
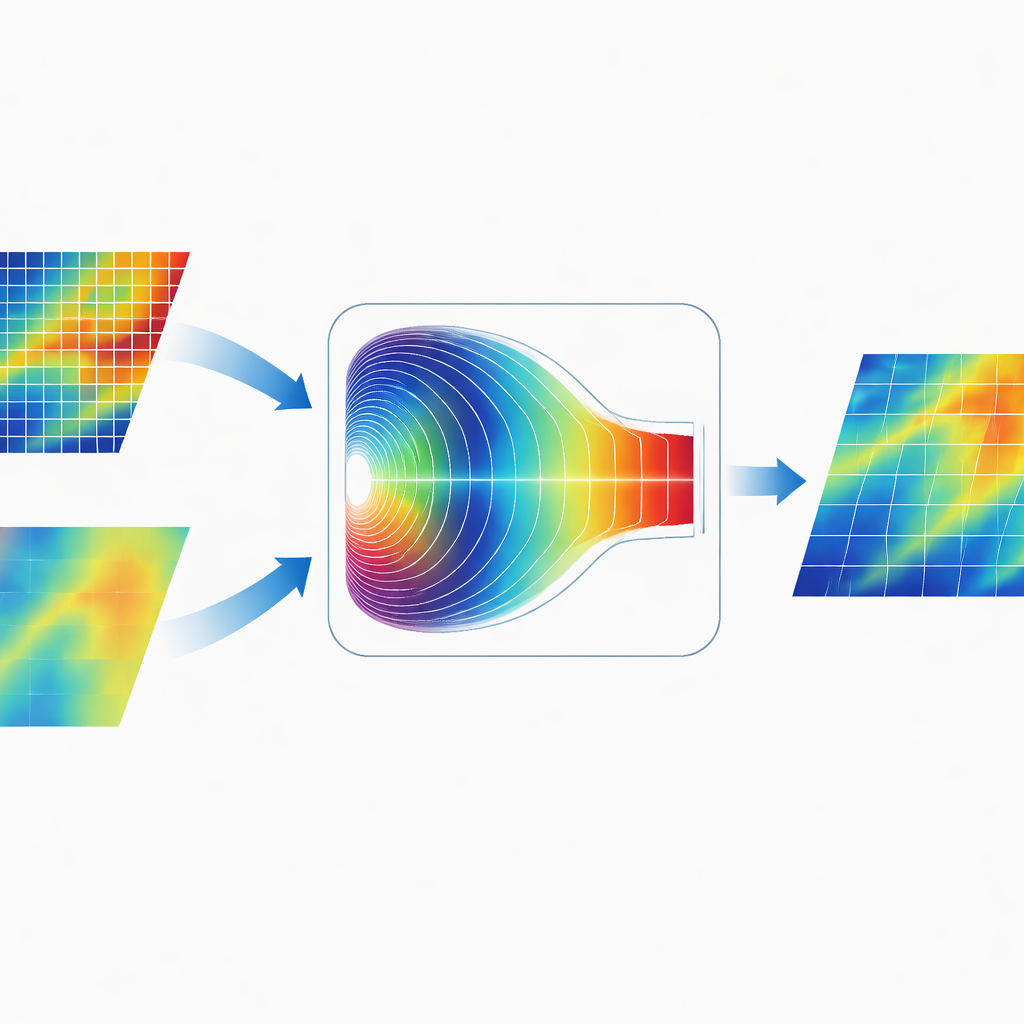
在频域中融合信息
CGDFNet的一个显著特点是其合并两条分支的方式。与简单在图像空间将它们的特征图相加不同,作者设计了傅里叶域自适应融合模块(Fourier-Domain Adaptive Fusion Module)。该模块将组合后的特征暂时转换到频域,在那里模式以缓慢、宽泛的变化和快速、尖锐的变化来表示。一个自适应门控机制随后学习应从细节分支强调哪些频率分量、从语境分支强调哪些分量。经过加权后,再将特征变换回时域,得到的表征比传统仅在空间上融合的方法更有效地统一了清晰边缘与连贯的全局结构。
在真实街道上的结果
团队在两个广泛使用的城市驾驶场景基准上测试了CGDFNet:从欧洲城市收集的Cityscapes,以及从司机视角采集的英国CamVid。CGDFNet以实时速度处理大尺寸图像——在Cityscapes上约88帧/秒,在CamVid上约129帧/秒——同时取得了可与许多最先进系统媲美或超越的分割精度。它在通常难以分割的类别上表现尤为出色,如栅栏、交通标志、公交车和自行车,这些类别对精确边界和小结构的保留至关重要。
这对日常技术意味着什么
从实用角度看,CGDFNet表明有可能构建既足够快以满足实时使用,又足够细致以在复杂城市场景中保留小而关乎安全的细节的视觉系统。通过结合侧重细节的分支、侧重语境的分支以及在频域中的智能融合步骤,该网络保持了对街道的均衡视野:既知道各物体的位置,也知道每个物体的起止边界。尽管仍面临挑战——例如密集人群或恶劣天气——该方法为未来的设备端视觉(从自动驾驶汽车到智能交通摄像头与辅助机器人)提供了有希望的蓝图。
引用: Zhao, S., Fu, W., Gao, J. et al. CGDFNet: a dual-branch real-time semantic segmentation network with context-guided detail fusion. Sci Rep 16, 9191 (2026). https://doi.org/10.1038/s41598-026-39370-1
关键词: 实时语义分割, 自动驾驶视觉, 双分支神经网络, 基于傅里叶的特征融合, 城市场景理解