Clear Sky Science · zh
骨架运动拓扑掩码预测与对比学习用于自监督人体动作识别
教计算机读懂肢体语言
从视频门铃到智能康复工具,许多现代系统只凭观察人的运动就需要理解他们在做什么。但训练计算机识别人类动作通常需要大规模、精心标注的数据集,其中每一次挥手、踢腿或握手都由人工注释。该研究提出了一种仅从原始运动数据中学习的方法,只使用人体的运动骨架——不需要标签、面部或彩色视频——使动作识别更准确、更隐私友好,并且大大降低对昂贵人工标注的依赖。
为什么骨架就足够了
该方法不是分析完整视频帧,而是使用 3D 骨架数据:随时间变化的关键关节坐标,例如肩膀、肘部、髋部和膝盖。这种精简的身体视图有若干优势。它在很大程度上避开了隐私问题,因为面部和服装信息被剥离,而且数据足够紧凑,即使是长时间录制也能高效处理。骨架对杂乱背景和光照变化也更鲁棒,而这些常会干扰传统基于视频的方法。然而,大多数现有的基于骨架的方法仍然高度依赖标注样本,并且难以充分捕捉关节在复杂协调动作中的协同运动。
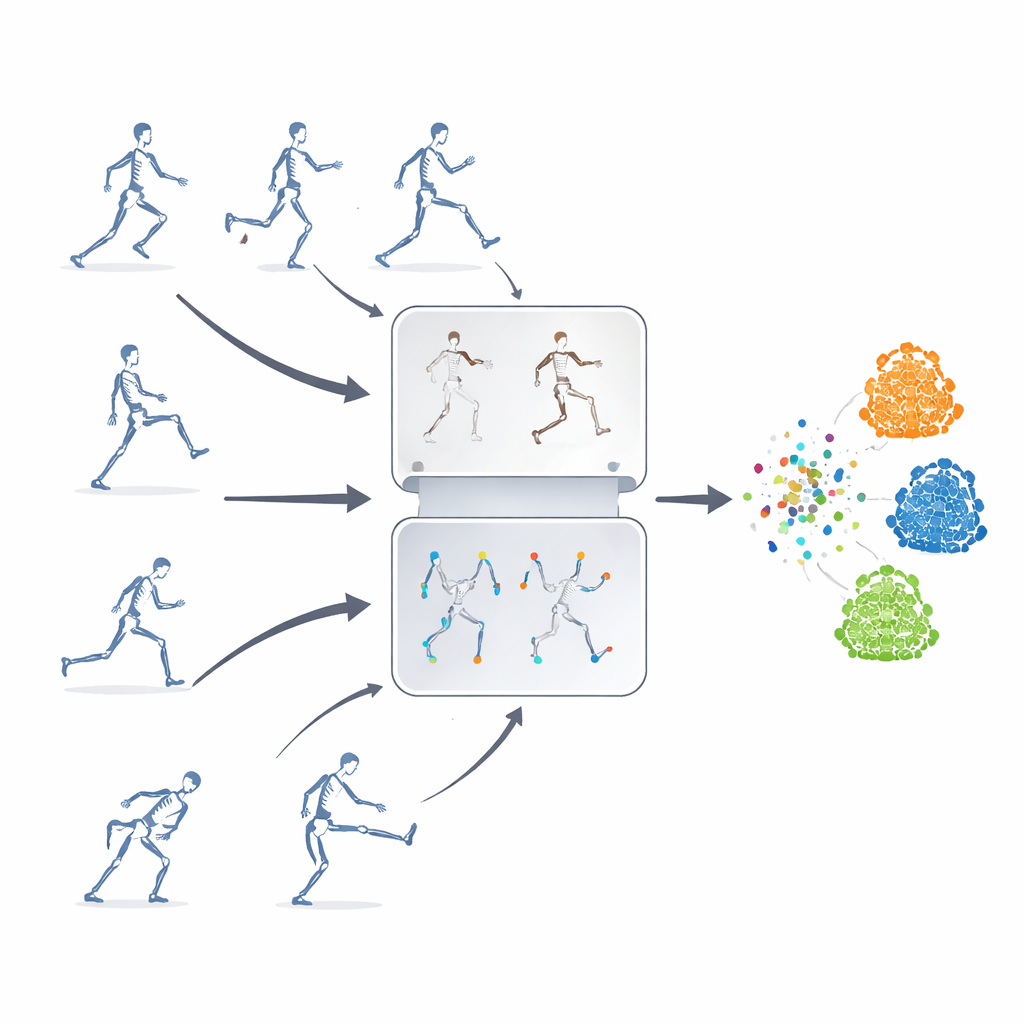
在无标签下学习
作者提出了一个自监督学习框架,意味着系统从未标注的骨架序列中自我学习。他们的关键思想是结合两种通常单独使用的强大策略。一是“掩码预测”,即有意隐藏部分骨架数据,使模型必须根据剩余上下文去推测缺失的运动。另一种是“对比学习”,向模型展示同一动作的多个变体,并训练它识别这些变体仍然代表同一个潜在动作。通过融合这两种方法,系统既学会了关节运动的细节,也掌握了动作的整体含义。
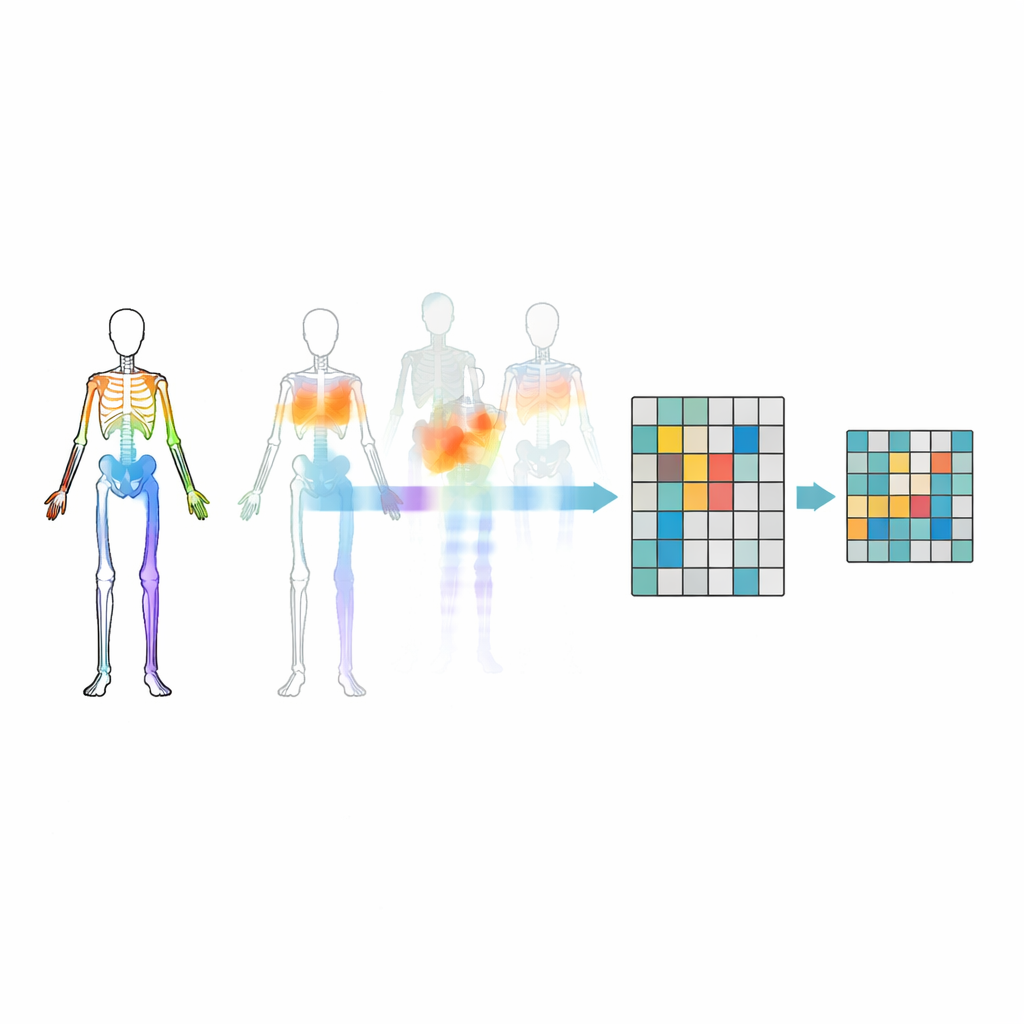
隐藏恰当的关节
简单地随机掩码关节并不够——模型可能忽视身体部位之间的重要关系或只关注最明显的运动。为避免这种情况,研究人员引入了一种运动—拓扑掩码策略。他们将关节分组为有意义的身体区域,如手臂、腿部和躯干,然后衡量每个区域随时间的运动强度。掩码决策由身体结构和各区域的运动程度共同指导,因此有时会隐藏高度活动的部分,迫使模型从身体的其余部分推断它们。这种有针对性的隐藏有助于系统学习关节在动作中如何协作,而不是仅仅记住几个显眼的动作片段。
以多种方式拉伸动作
为训练对比学习部分,同一原始骨架序列被转换为多个不同的“视图”。有些变换较为温和,例如裁剪时间窗口或轻微扭曲轨迹,而另一些则更极端,包括翻转、旋转和更强的噪声。这些多层次的数据增强向模型展示了丰富的运动模式,鼓励它关注动作的核心结构而非表面细节。与此同时,一个基于轨迹的特征丢弃模块会跟踪模型最依赖的运动特征,并在训练时有意抑制它们。通过暂时移除其“偏好”线索,系统被推动去发现备用线索并学习更通用、可迁移的表示。
效果如何?
该框架在三个大型公开的 3D 人体动作基准上进行了测试,覆盖日常行为、医疗相关动作和人际交互。尽管它仅使用骨骼关节数据和相对轻量的循环神经网络,该方法与许多依赖更复杂输入或架构的最先进系统相匹配或超越。它在标注稀缺或部分身体部位被遮挡的情况下表现尤为出色——这些情况在现实环境中常常出现。尽管其在非常不同数据集之间迁移知识的能力仍有改进空间,但该方法显著缩小了有标注与无标注训练在动作识别上的差距。
对现实系统的意义
对非专业读者而言,结论是:这项工作展示了计算机如何在不明确告知每个动作含义的情况下,大幅提升解读人体肢体语言的能力。通过在训练时智能地隐藏和扭曲骨架数据,模型学习到在光线差、视觉混乱或关节缺失等不利条件下仍然稳健的运动模式,并且需用的人为标注大大减少。这为从家庭监控和运动训练到医疗康复与人机交互的更私密、可扩展且更具适应性的动作识别系统开辟了道路。
引用: Hui, Y., Li, F., Hu, X. et al. Skeleton motion topology-masked prediction and contrastive learning for self-supervised human action recognition. Sci Rep 16, 8100 (2026). https://doi.org/10.1038/s41598-026-39330-9
关键词: 人体动作识别, 3D 骨架数据, 自监督学习, 对比学习, 运动分析