Clear Sky Science · zh
一种用于基于视频的行人再识别的带多层聚合的 CNN-RNN 孪生框架
为何跨摄像头跟踪人员很重要
现代城市布满了摄像头,但这些摄像头很少“互通”。当一个人从街角走到地铁站时,不同摄像头会从新的角度、不同光照条件下并常常在人群中拍到同一人。自动识别不同时段视频片段中是否为同一人——称为基于视频的行人再识别——能帮助调查人员在事件后追踪行踪、支持失踪人员搜寻,或为繁忙公共场所提供分析。然而,要在有限硬件上做到既准确又高效是一个重大技术挑战。
用于匹配移动中行人的更简明“头脑”
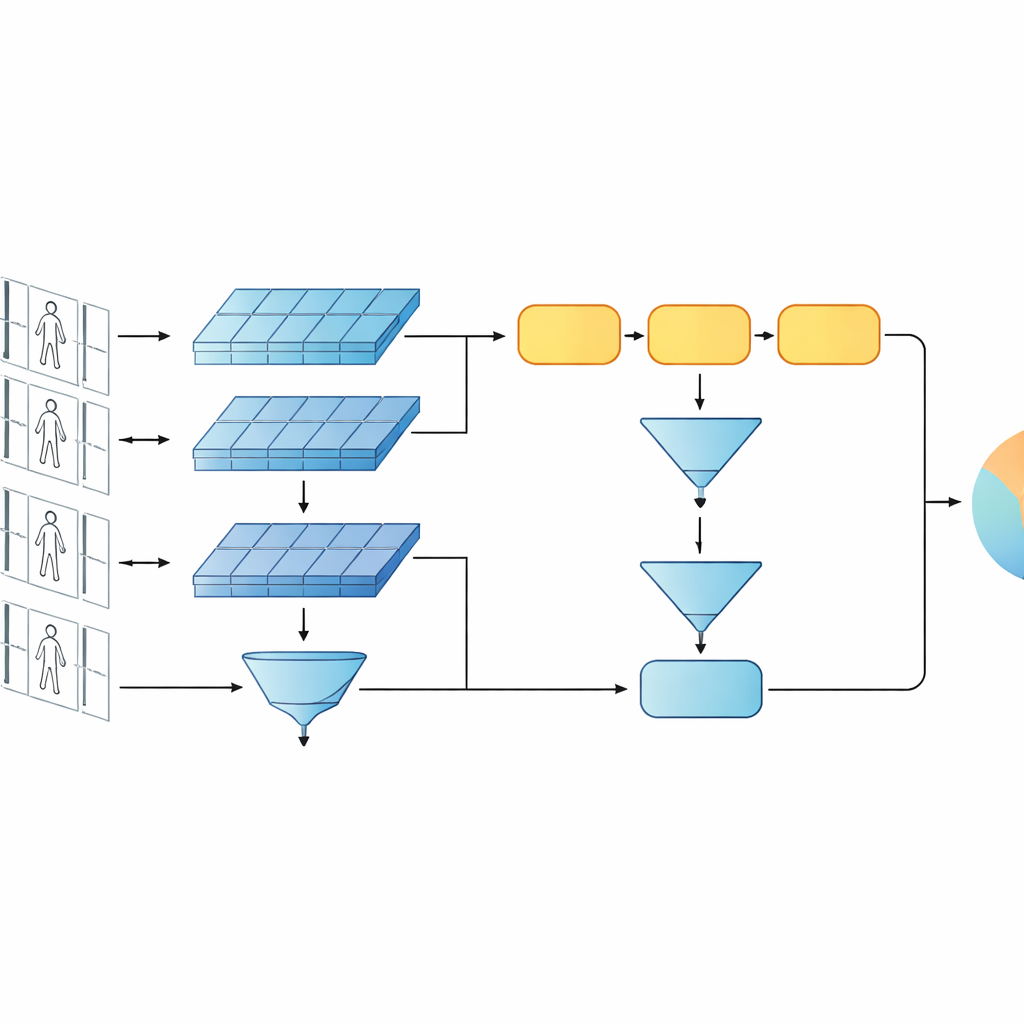
本研究提出了一个紧凑的人工智能系统,用于判定两段短视频是否属于同一人。作者没有采用当下非常深或基于变换器的网络,而是基于更精简的设计,结合两种经典组成:一个用于分析每帧图像的卷积网络和一个用于跟踪外观随时间变化的门控循环单元(GRU)。这两条分支以孪生结构排列——即两份网络的副本共享所有内部参数。每个孪生网络处理一个视频序列,系统学习为同一人的片段生成相似的内部表征,而为不同人的片段生成明显不同的表征。
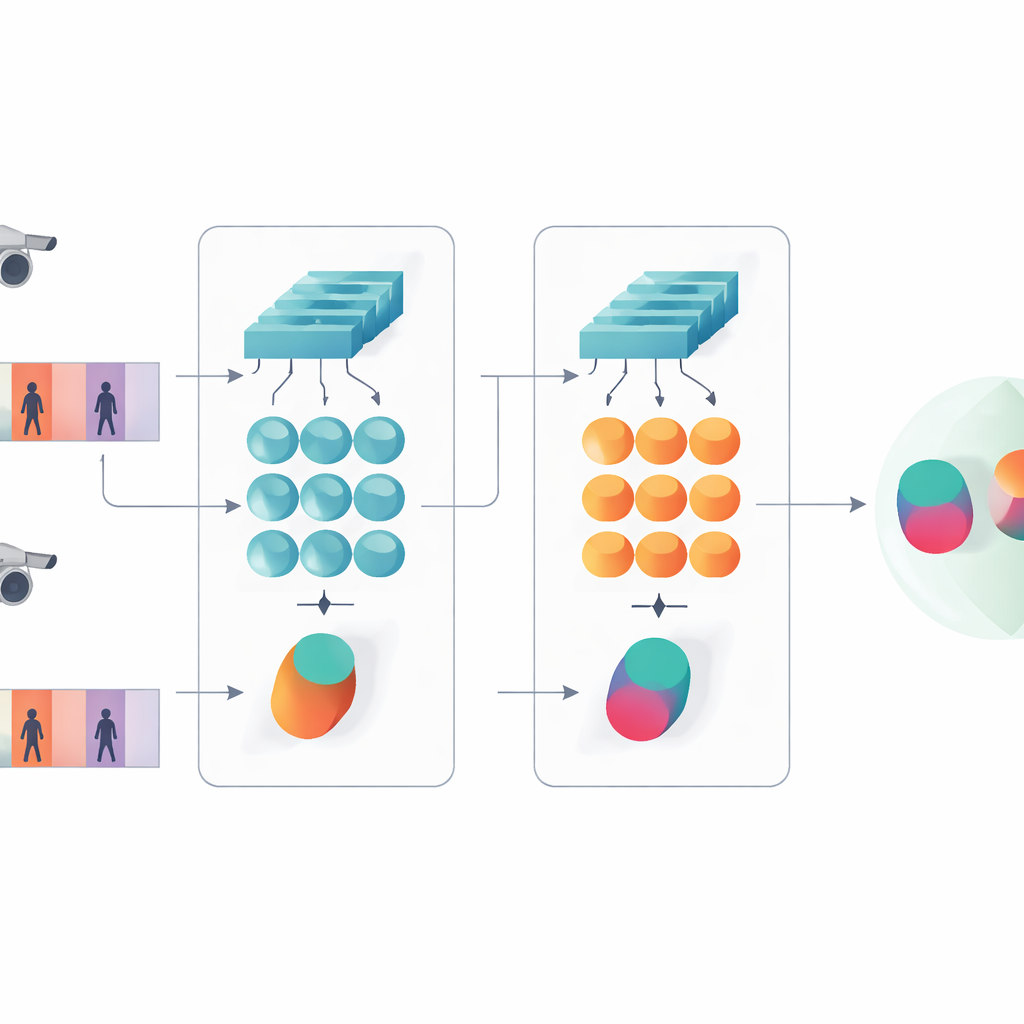
同时看到细节与时间模式
工作的关键观点是识别不应仅依赖网络中最深、最抽象的特征。早期层仍保留清晰的视觉细节,例如夹克的织纹、裤子的条纹或背包的轮廓——这些线索通常能在摄像角度变化时保存下来。因此,所提模型保留两级描述。一条分支在所有帧上对早期层特征进行池化,以汇总细粒度纹理和局部模式;另一条分支将后期特征输入 GRU,逐帧跟踪序列,然后对其内部状态在时间上求平均。该平均步骤避免过度强调末尾几帧,而是捕获对整段视频中人物外观与动作的共识性描述。
训练孪生网络以达成一致并进行分类
为教会系统何为重要,作者结合了两类训练目标。首先,验证目标促使孪生分支为同一人的视频生成相近的表征、为不同人的视频生成相异的表征。其次,分类目标要求网络将每个训练片段分配到具体身份。通过同时优化这两者,并在低层与高层特征上都施行,模型学到的内部描述不仅在人物之间具有辨别性,还对噪声、遮挡和偶发的低质量帧具有鲁棒性。该设计在层数和参数上保持浅显,有助于在相对较小的视频数据集上避免过拟合。
在真实监控风格视频上的测试
该框架在两个广泛使用的视频基准上进行了评估:PRID-2011 和 iLIDS-VID,这些数据集包含由不相交摄像机对拍摄的数百名个体的短步行序列。研究详尽考察了不同设计选择的影响:用其他循环单元替换 GRU、改变循环层数、调整特征在时间上的池化方式以及开启或关闭低层/高层分支。在这些测试中,单层 GRU 加上均值池化与完整的多层设置持续带来最佳精度。该模型在匹配或超越许多更复杂的循环和孪生系统的同时,在一些基于注意力的设计上也有竞争力,并且使用的参数和计算远少于那些方法。
面向实际部署的高效性
除了精度外,本文强调了实用性。整个网络只有约一到两百万个可训练参数——相比流行的深度残差或变换器主干少了好几个数量级——并且每帧需要的计算量只是它们的一小部分。这使得它更适合部署在内存和计算受限的设备上,例如靠近摄像头的边缘服务器。实验还显示,更长的图库序列(即系统看到每个已存人员更多帧)会显著提升识别率,但处理成本呈线性增加。作者认为,这类紧凑且经过精心设计的架构能在不需使用当今最大模型高昂代价的情况下,提供可靠的行人再识别。
这对日常监控系统意味着什么
简单来说,本文表明精巧的设计可以胜过单纯的规模:通过结合浅层图像分析、轻量序列建模和双层视觉相似性视角,可以在保持模型小巧快速的同时高可靠地跨摄像头辨认人物。对于必须在大量摄像头上运行且常常受限于硬件与能耗预算的未来系统,这种高效的多层方法有助于把更强大且更负责任的视频分析带入现实应用中。
引用: Wang, YK., Pan, TM. & Sun, CP. A CNN-RNN Siamese framework with multi-level aggregation for video-based person re-identification. Sci Rep 16, 8224 (2026). https://doi.org/10.1038/s41598-026-39277-x
关键词: 行人再识别, 视频监控, 孪生神经网络, 时间建模, 高效深度学习