Clear Sky Science · zh
基于大模型的动态策略:一种稳健的自然语言到 SQL 的生成框架
将日常问题转换为数据库答案
现代组织数据充沛,但大多数人不会使用查询这些数据所需的专业语言。本文提出了 TriSQL——一个允许用户用自然语言提问并自动将其转换为精确数据库命令的系统。通过谨慎管理大型语言模型应对复杂性的方式,该框架旨在使数据访问更加准确和可靠,即使面对最困难的问题亦然。
为什么与数据库对话如此困难
当有人输入诸如“哪些客户上个月购买了超过五件商品?”之类的问题时,计算机必须将其翻译为 SQL——这是大多数数据库使用的专用语言。这个任务称为 text-to-SQL,看似简单却出乎意料地困难。系统必须理解用户的意图,在有时庞大且混乱的数据库中找到正确的表和列,然后构建既语法有效又忠实于原始意图的查询。包括基于大型语言模型的先前系统在内,当问题涉及多表、嵌套逻辑或微妙条件时,常常会失效。它们可能生成看似接近正确但在执行时无法运行或返回错误结果的查询。
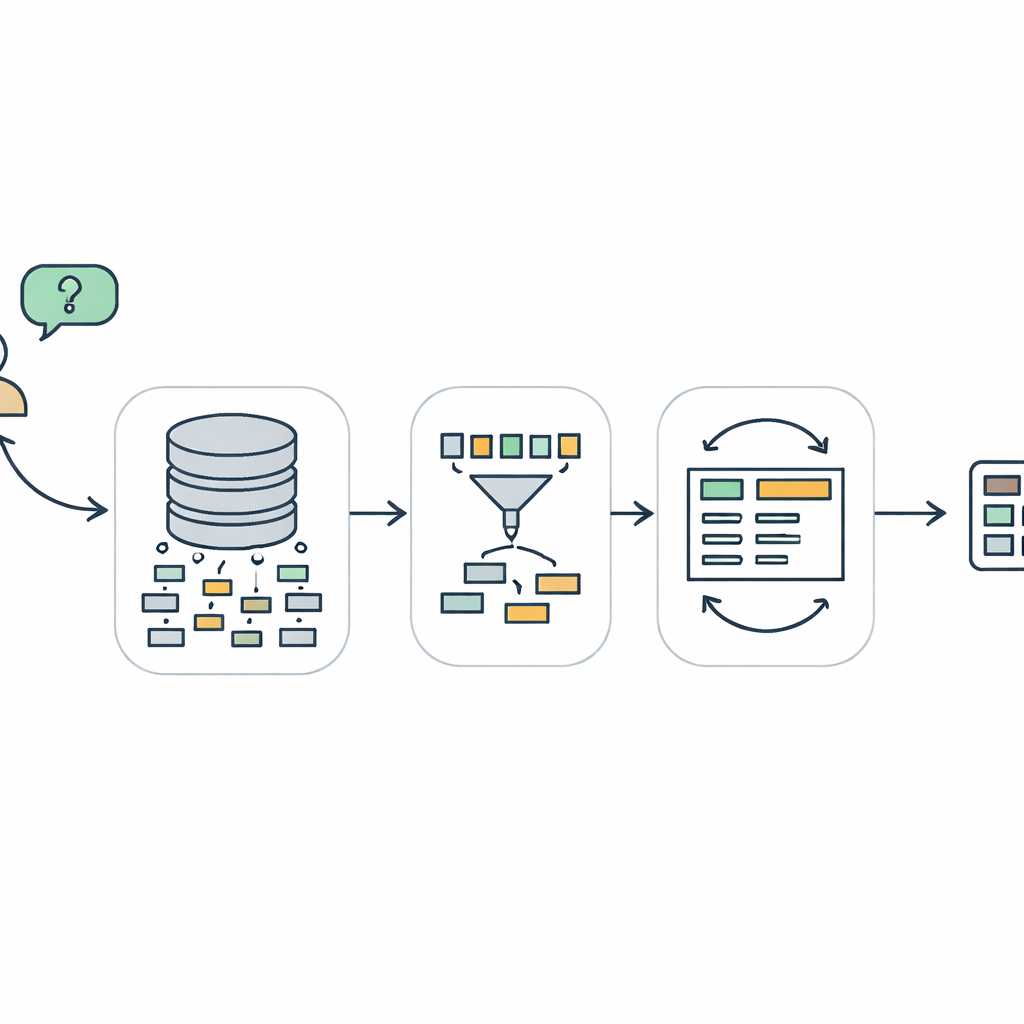
从问题到查询的三步路径
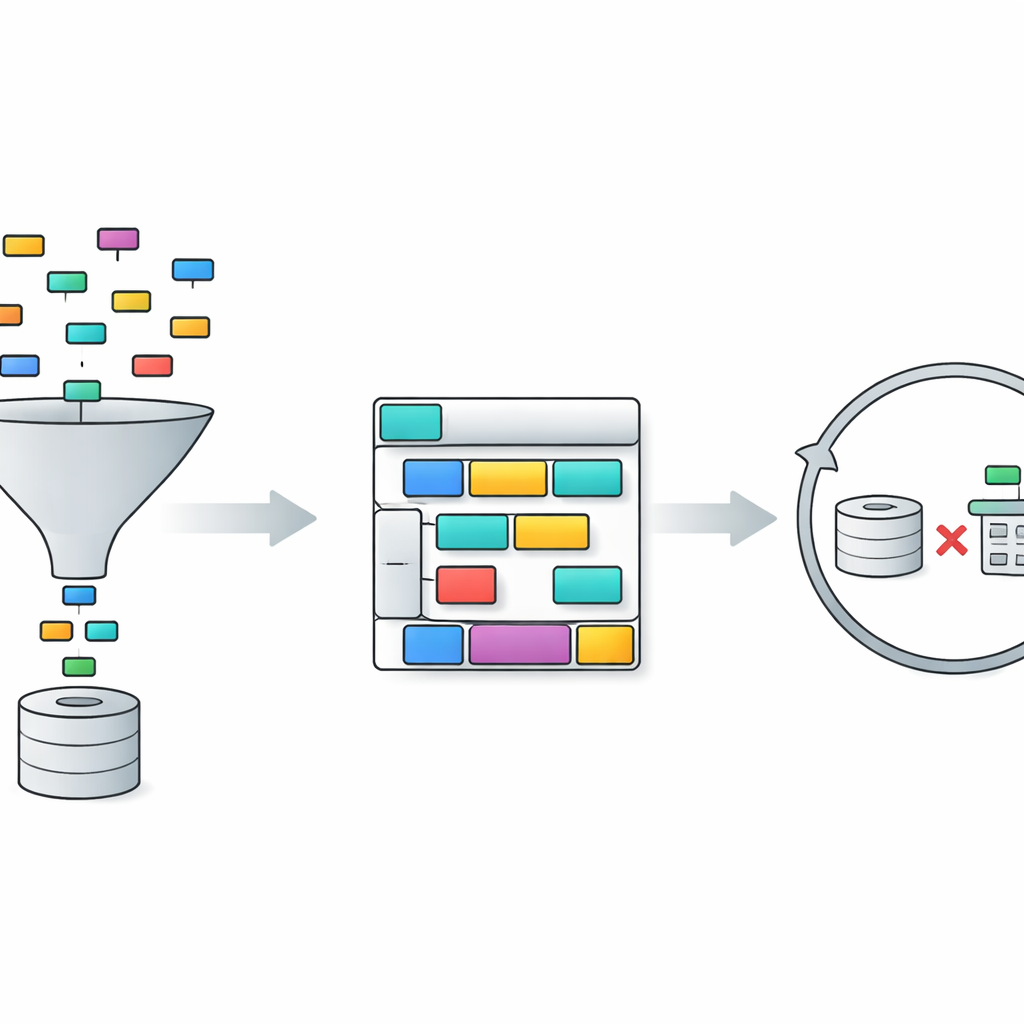
TriSQL 通过三阶段流水线应对这些问题。首先,一个以问题为导向的选择器会检查用户的话语和完整的数据库结构,决定哪些表和列是真正相关的。它不会盲目将整个模式暴露给语言模型,而是将视野缩小到仅相关的部分。其次,一个结构感知的生成器在填充细节之前先规划 SQL 查询的形状。它先勾勒出高层骨架——需要哪些子句以及它们如何组合——然后再插入具体的表、连接和条件。这种“先结构、后内容”的方法有助于保持 SQL 的严格语法,尤其适用于冗长而复杂的查询。最后,一个复杂度感知的精炼器会检查并改进初始查询,根据问题的难度采用不同策略。
将精力与问题难度相匹配
精炼阶段是 TriSQL 尤其新颖地利用大型语言模型的地方。系统为每个问题和草稿查询评分,考虑的因素包括连接了多少表、嵌套有多深以及使用了哪些约束。对于简单情况,它只做轻微修正,例如修复小的语法错误。对于中等情况,它会重组子句并确保查询与所选模式一致。对于最复杂的问题,它会调用语言模型进行更深入的推理,有时将问题分解为子任务并运行替代查询。关键是,TriSQL 会将原始查询和改进后的查询都提交到数据库执行,并根据它们的行为——是否能运行、耗时以及返回结果——来决定保留哪个版本或是否尝试另一次精炼。
对系统进行测试
为了评估 TriSQL 的效果,作者在广泛使用的基准 Spider 上进行了测试,并添加了若干更具挑战性的变体,这些变体引入了领域知识、非常规句式和更接近现实的查询结构。他们衡量两项指标:精确匹配(exact match),检查生成的 SQL 字符串是否与人工参考完全相同;以及执行准确率(execution accuracy),检查其在运行时是否实际产生正确答案。在这些数据集上,TriSQL 在执行准确率上达到了迄今报告的最高水平,同时在精确匹配上与最好的先前系统保持竞争力。它也更具鲁棒性:随着问题从简单到极其困难,TriSQL 的性能下降比竞争方法要平缓得多。在一个真实的电网管理数据集上的额外实验表明,同一框架不仅能处理数据检索,还能处理插入、更新、删除和建表命令。对图数据库(Cypher)和 MongoDB 管道的初步适配表明,这种三阶段设计可以扩展到经典 SQL 之外。
这对日常数据使用意味着什么
简单来说,这项工作使我们更接近于一个世界:人们可以像与搜索引擎聊天一样轻松地与复杂数据库对话。通过精心选择要考虑的数据库部分、在填充细节前规划查询结构、并根据每个问题的难度调整对大型语言模型的使用,TriSQL 生成的查询更有可能正确运行并返回预期结果。尽管仍有挑战——例如处理含糊的问题和未见过的数据库——该研究表明,经过深思熟虑的分阶段设计可以让面向数据的自然语言接口对日常用户既更强大又更可预测。
引用: Su, X., Gu, Y., Wang, P. et al. A robust natural language text-to-SQL generation framework with dynamic strategies based on LLMs. Sci Rep 16, 7892 (2026). https://doi.org/10.1038/s41598-026-39128-9
关键词: text-to-SQL, 自然语言接口, 数据库查询, 大型语言模型, 查询稳健性