Clear Sky Science · zh
一种使用边界移动处理不平衡数据集的方法
为什么日常数据中的稀有情况很重要
从银行欺诈和医学诊断到预测客户流失,许多我们让计算机做出的决策都依赖于识别那些罕见但关键的事件。在大多数真实数据集中,这些重要案例远远少于普通样本。一个主要只看到“日常情况”的模型可能会对我们最关心的情形视而不见。本文提出了一种重新平衡此类偏斜数据的新方法,以便学习算法能适当地关注那些稀有且影响重大的案例。
偏斜数据的隐蔽陷阱
当一种类型的样本远多于另一种类型时,标准机器学习方法往往会集中关注多数类,而悄然忽视少数类。例如,一个流失预测系统可能把几乎所有人都标注为忠诚客户,仍然在准确率上表现良好,原因只是实际流失者非常少。在事故检测、欺诈监测和医学筛查等情形中也会出现类似问题:阳性病例稀少但漏检代价高。传统的修正方法大致分为两类:调整学习算法以“更重视”少数类,或通过去除部分多数样本(下采样)或创建额外少数样本(过采样)来重塑数据。流行的过采样工具如 SMOTE 会生成合成少数样本,但它们可能在两类交界的敏感区域无意中引入杂乱样本。
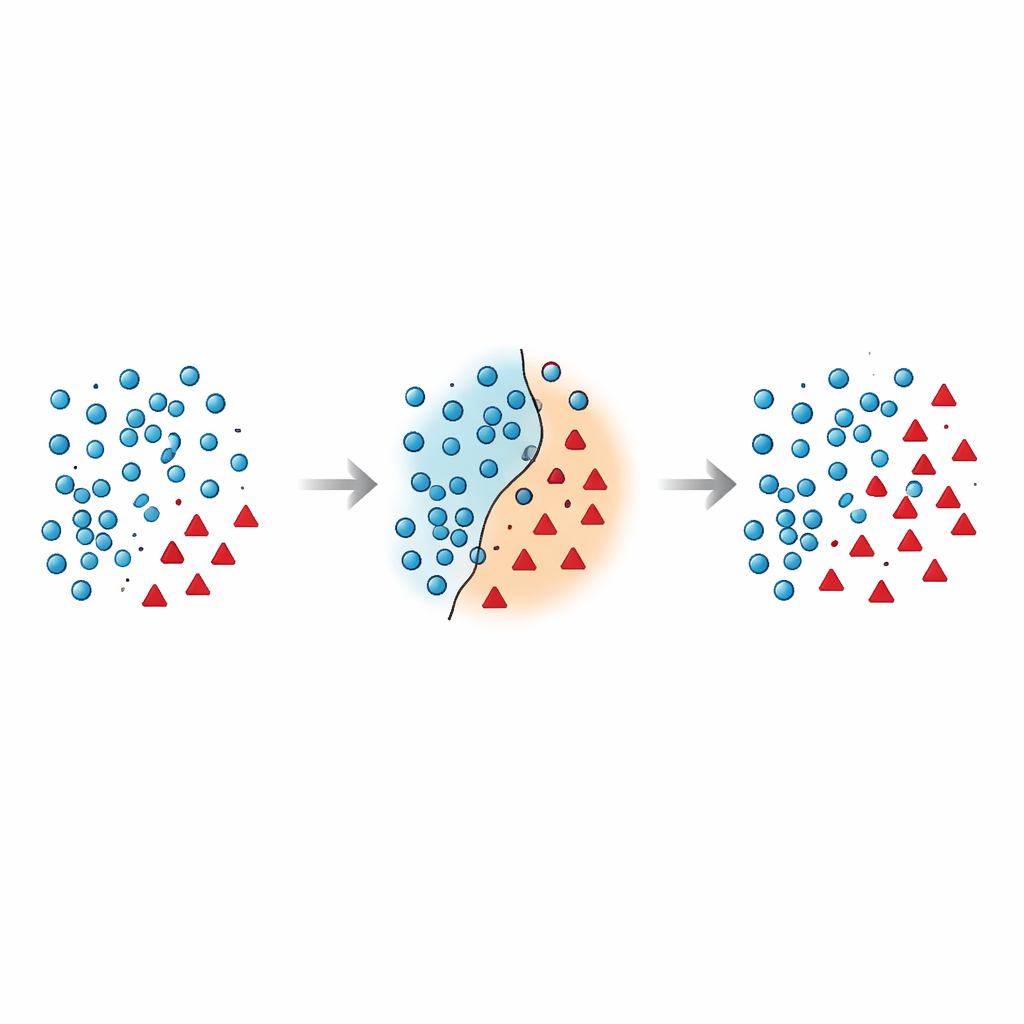
群体间边界为何如此脆弱
作者指出,最危险的错误发生在决策边界附近——这是多数类和少数类在特征空间重叠的区域。许多现有技术要么在这个高风险区域直接添加合成点而不清理,要么激进地删除数据却意外丢失有信息量的样本。近来的研究尝试用几何约束、局部密度估计或噪声滤波来缓解,但大多数方法仍旧把少数样本视为固定点,鲜少重新考虑应如何处理靠近边界的多数样本。这留下了一个长期问题:重叠和噪声样本会混淆分类器,导致预测不稳定,尤其是在新数据上表现不佳。
整理边界的两步法
本文提出了边界移动过采样(Borderline Shifting Oversampling,BSO),这是一种明确针对问题边界区域的两阶段数据重塑方法。首先,它扫描每个多数样本的邻域,以判断该样本位于安全区、边界或明显错误的位置(噪声)。被少数邻居包围的多数点要么被重新归类到少数一侧,要么被标记为噪声并移除,从而有效地清理并移动边界,使其更好地反映底层模式。在第二阶段,该方法使用类似 SMOTE 的插值在精炼后的边界附近为少数样本生成新的合成点。但只在靠近边界的少数样本周围生成新样本,并避开明显的噪声点。通过在最具信息量的位置集中新增数据并避免嘈杂区域,BSO 构建了既在规模上更平衡、又在结构上更清洁的训练集。
将方法付诸检验
为评估该方法在实践中的表现,研究者在 30 个具有不同不平衡和重叠程度的基准数据集上测试了 BSO。他们将其与七种广泛使用的替代方法进行了比较,包括随机过采样与下采样、SMOTE、Borderline‑SMOTE、NearMiss,以及两种将过采样与噪声清理相结合的混合方法(SMOTE‑Tomek 和 SMOTE‑ENN)。三种常见分类器——支持向量机、朴素贝叶斯和随机森林——在每个重采样后的数据集上进行训练。研究没有依赖原始准确率,而是使用在不平衡情形下更为信息化的指标,如 F1 分数、G‑mean、召回率、精确率以及 ROC 曲线下面积(AUC)。在几乎所有数据集和分类器上,BSO 都提供了更高或相当的评分,同时表现出更小的波动,意味着其优点是稳健的,而非依赖于特定模型或设置。
对现实决策的意义
用通俗的话说,边界移动方法像是对混乱数据的细致编辑:它清理位于类别分界线附近的令人困惑的样本,然后在合适的位置恰到好处地添加逼真的少数样本。其结果是学习算法能更好地识别那些稀有但重要的事件,而不被嘈杂的重叠误导。对于欺诈检测、事故预测或医疗分诊等场景——遗漏少数样本代价高昂——该方法提供了一种实用方式,使模型更公平、更敏感、更可靠,同时仅增加适度的计算开销。
引用: Malhat, M.G., Elsobky, A.M., Keshk, A.E. et al. An approach for handling imbalanced datasets using borderline shifting. Sci Rep 16, 8264 (2026). https://doi.org/10.1038/s41598-026-39118-x
关键词: 类别不平衡, 过采样, 决策边界, 异常检测, 机器学习鲁棒性