Clear Sky Science · zh
DeCon-Net:用于足球目标检测的解耦层次对比方法
为什么识别球员和球比看起来更难
现代足球转播充斥着图形、统计和慢动作回放,这些都依赖于计算机系统先回答一个看似简单的问题:每一帧中球员和球的位置在哪里?本文探讨了为什么当前领先的人工智能工具在真实比赛中依然难以完成这一基本任务——并提出了一种新方法 DeCon‑Net,使得在复杂、拥挤场景中自动检测球员和球更可靠。
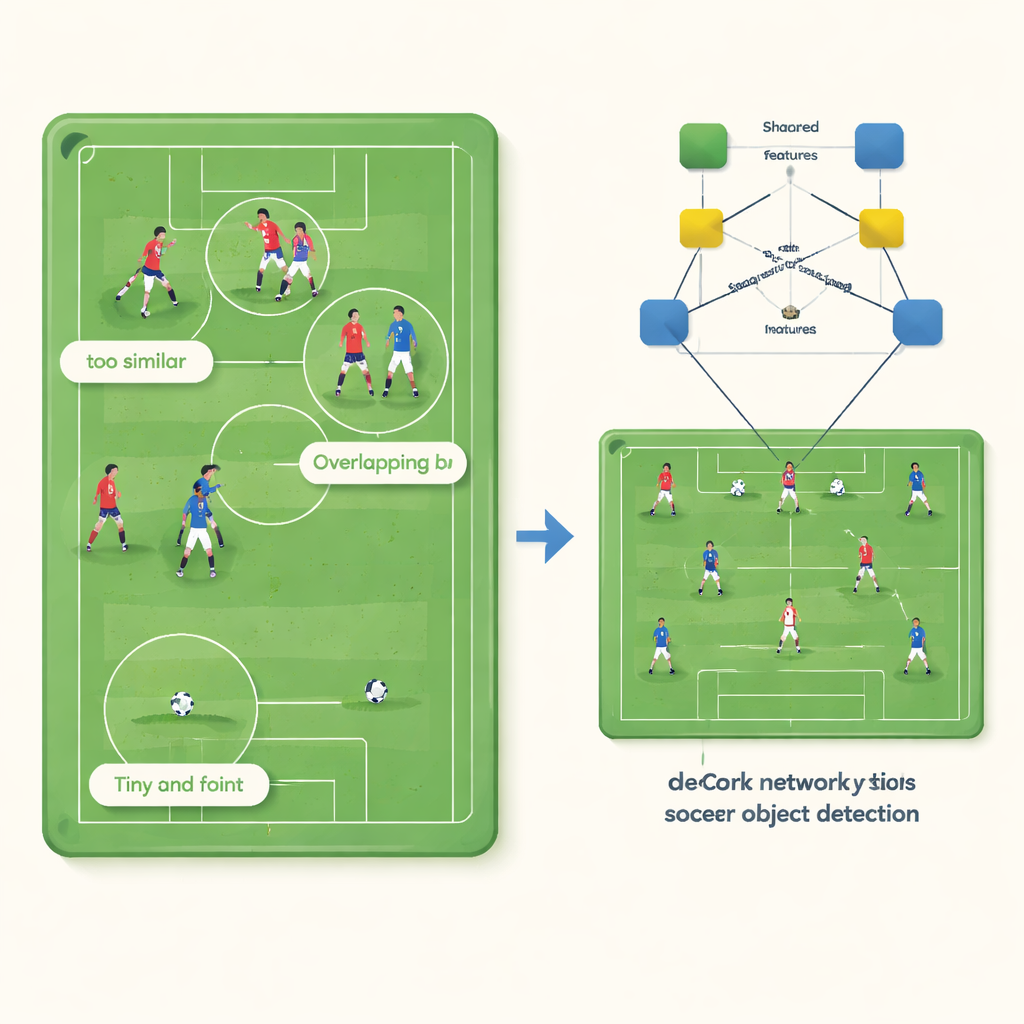
足球视频中的三个隐性问题
乍看之下,检测球员和球似乎很直接:它们会移动、形状明确,并且能从草皮中区分出来。但作者表明,标准计算机视觉系统存在三个相互交织的问题。首先,穿着相同队服的队友对算法几乎不可区分,算法内部对它们的“特征”描述会塌缩为几乎相同的点。其次,在拥挤缠斗中,球员相互重叠严重,检测器常常对几个人画出一个大边界框,而不是分别框出每个人。第三,球很小——有时只有几十个像素——其视觉信号很弱,容易被草地纹理和球员运动淹没,导致系统完全漏检。
将网络学到的内容拆分开来
DeCon‑Net 通过改变神经网络对帧中所见事物的表示来应对这些问题。作者不是让模型为每个对象学习一个混合的描述,而是将该描述拆分为两个互补的部分。一个通道捕捉队友之间共享的特征——例如球衣颜色,另一个通道则关注使每个个体独特的特征,如身体姿态或精确位置。一个特殊的训练技巧在网络试图在“个体”通道使用队伍信息时翻转梯度,有效地教会它忽略球衣颜色,专注于个体特征。随后这两个通道会被自适应地重组合,使得在简单场景中系统更多依赖共有特征,而在球员拥挤时则更多依赖个体特征。
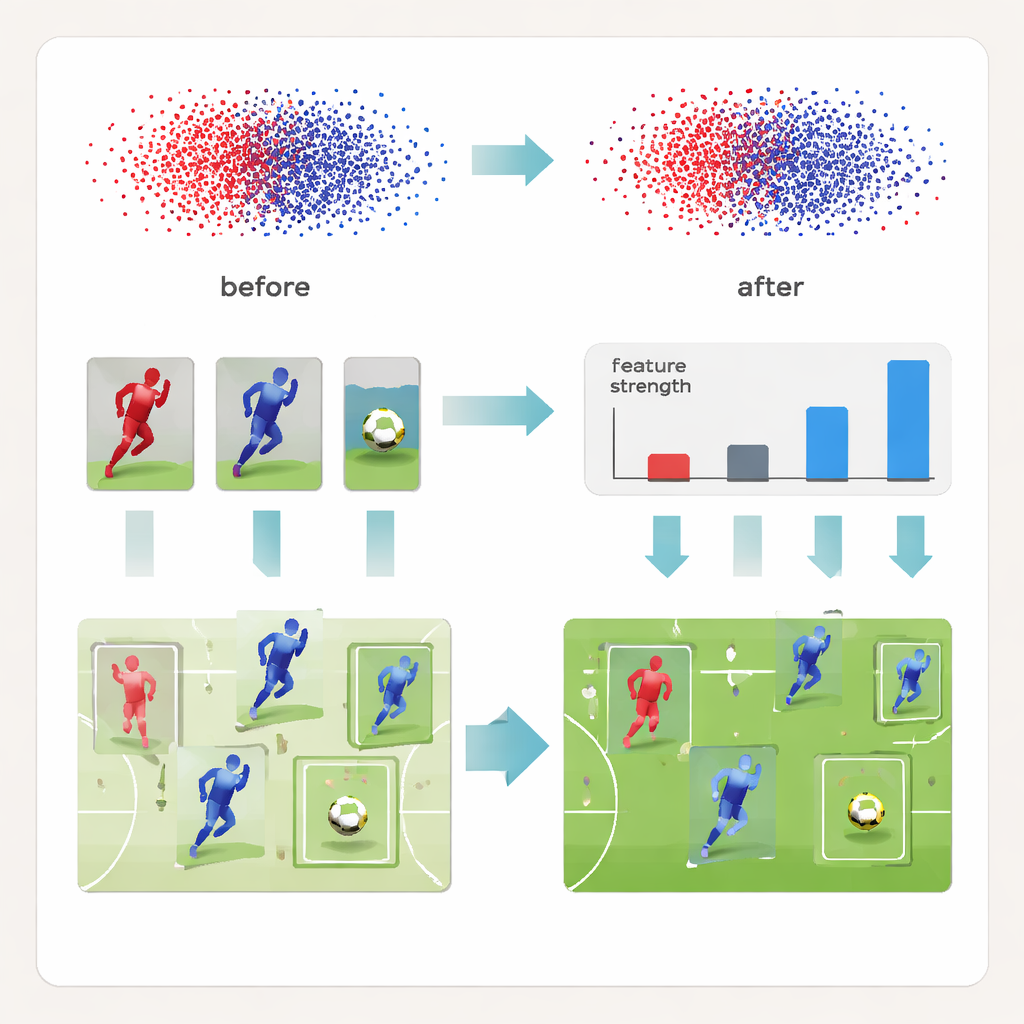
用比较来教模型,而不仅是标签
除了这种拆分表示外,DeCon‑Net 还重塑了学习方式。该方法增加了一个层次化的“对比”训练步骤,持续比较检测到的对象对。那些已经明显不同的对只需轻微矫正,而那些看起来混淆的对——例如并肩站立的两名队友——则被更积极地训练以在网络的内部空间中拉开距离。这种三级策略先从简单的区分开始,随后过渡到队内更细微的差异,最后处理不同比赛和转播条件下的变化。为了挽救容易被忽视的小球,该方法还在训练中增强了非常小的目标的影响,使球的信号突显出来而不是融入背景噪声中。
从实验室基准到真实体育转播
研究者在两个苛刻的数据集上测试了 DeCon‑Net:包含足球、篮球和排球的 SportsMOT,以及从真实电视转播构建、包括变焦、运动模糊和频繁遮挡的 SoccerNet‑Tracking。总体来看,DeCon‑Net 在检测球员和球方面均优于基于 Faster R‑CNN、DETR 以及近期面向跟踪的方法的广泛使用系统。对球的提升尤为显著,相较于强基线,准确率提升超过 40%。该系统在应用于与训练集不同的数据集时表现也更稳健,表明其拆分特征设计捕捉到了更通用、可重用的体育场景线索。
这对体育分析未来意味着什么
通俗地说,本文表明许多现有的 AI 系统以过于简化的方式“看待”足球:它们把同队球员混为一谈,在动作混乱时几乎忽略球。DeCon‑Net 通过强制网络分别学习队伍归属和个体身份,并对微小、易被忽视的物体给予额外关注来应对这一问题。其结果是对场上每位球员和球的更精确、更可靠的逐帧映射。这一基础可以为教练提供更好的战术分析,为转播方带来更丰富的图形展示,并为球迷提供更准确的统计数据,使我们更接近真正智能化的自动比赛理解。
引用: Ouyang, Q., Du, T. & Li, Q. DeCon-Net: decoupled hierarchical contrast for soccer object detection. Sci Rep 16, 7571 (2026). https://doi.org/10.1038/s41598-026-39084-4
关键词: 足球视频分析, 目标检测, 体育分析, 计算机视觉, 球跟踪