Clear Sky Science · zh
大型语言模型在多语种事实核查中表现出类邓宁—克鲁格效应
为什么智能事实核查关系到每个人
错误信息传播速度比以往更快,影响人们对健康、政治、科学和日常生活的信念。许多平台和新闻机构开始依赖人工智能——尤其是大型语言模型(LLM)——来帮助判断病毒性言论的真假。本研究提出了一个看似简单但至关重要的问题:当我们让这些系统来评判事实时,它们有多常正确、表现出多大把握感,以及这种表现是否在不同语言和世界各地发生变化?
研究者如何用真实谣言测试 AI
作者没有编造人工示例,而是从已经由全球专业事实核查组织调查过的 5,000 条真实声明中构建测试集。这些声明覆盖 47 种语言,来自全球北方与全球南方,反映出网络谣言的复杂与多元现实。仅纳入由多方事实核查者一致判断为“真”或“假”的明确陈述,从而建立了坚实的真实标签供比较。
随后,他们让九个广泛使用的语言模型(从较小的开源系统到先进的商业模型)对每一条声明进行判断。为模拟人们与聊天机器人实际交流的方式,大多数提示是诸如“这是真的吗?”或“这是假的吗?”之类的简单问题,且与声明使用相同的语言。第四种、更专业的设置则使用英文的详细指令,将模型转为虚拟事实核查员并要求输出结构化结果。人工标注员仔细阅读模型回答,并将其标为认为声明为真、为假或拒绝给出明确判定。
不仅衡量对错,还衡量何时说“我不知道”
研究团队不只是统计命中与失误。他们使用了三项关键度量来捕捉模型行为。首先,“选择性准确率”衡量模型在明确表态认为某声明为真或假的情况下有多常正确。其次,“容忍弃权的准确率”把承认不确定而非猜测视为可接受甚至可取——这在医学或选举等敏感领域至关重要。第三,“确定率”跟踪模型给出明确答案的频率,作为其行为自信程度的粗略替代指标。
带有分步指导的专业风格提示在所有模型中一致提升了准确率。但它也暴露了一个权衡:较小的模型往往变得更果断却并未更可靠,而更大的模型则利用该结构给出更少但更好的答案。日常对话式提示促使模型表现得更为谨慎,尤其是较弱的模型,但也在一定程度上降低了它们的准确性。
能力较弱的系统为何更自信
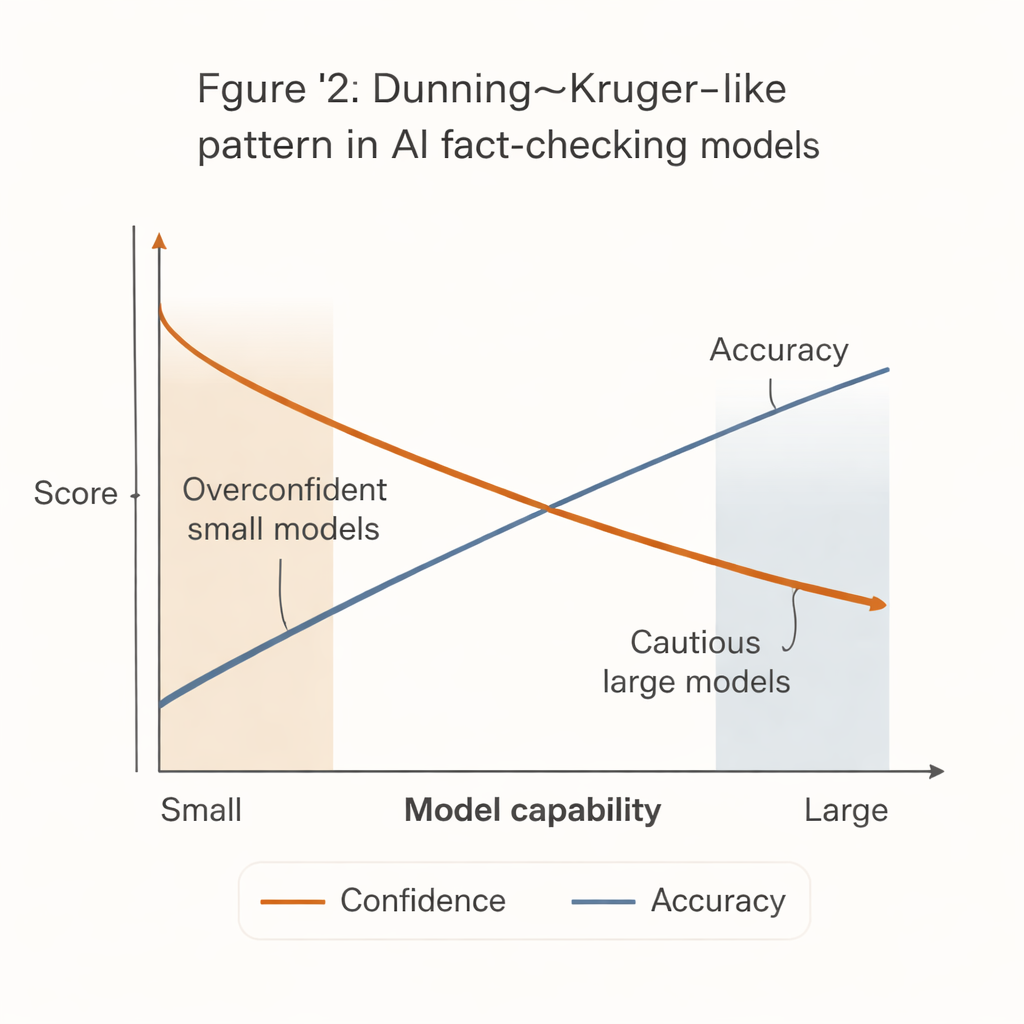
出现了一个明显模式,类似人类心理学中著名的邓宁—克鲁格效应:最不可靠的系统却表现出最高的自信。体积小、成本低的模型倾向于对绝大多数声明给出确定判决,但其准确率明显偏低。相比之下,最强的模型(例如先进的 GPT 版本)在确立立场时准确度远高,但更可能选择弃权,尤其是在面对困难或模糊的陈述时。
这种“自信—能力差距”带来真实世界的后果。许多资金短缺的新闻室、民间社会组织和地方事实核查机构负担不起最强大的 AI 系统。它们更可能采用看起来果断但错误率更高的较小模型。如果在工作流程或社区管理系统中未经充分保护地接入这些工具,反而可能通过生成自信但不正确的事实核查结果来放大错误信息。
不同语言与地区之间的不平等表现
研究还显示,这些系统并非对所有人表现同样良好。在几种主要语言中,模型通常在英文声明上表现最佳,在葡萄牙语和印地语上稍差。较大的模型在非英语语言中往往更为谨慎,但在准确性上仍优于较小模型。当作者比较与全球北方和全球南方相关的声明时,大多数模型在后者上表现更差。较小的系统在准确性下降的同时仍常表现自信,而大型模型显示出更大的确定率下降但更小的正确率下降,表明它们能感知到自身的不确定性并选择后退。
这对可信赖 AI 工具的未来意味着什么
对非专业读者来说,核心信息很清楚:当下的 AI 事实核查工具远非同质,且最易获得的那些可能最具误导性。强大的模型可以既谨慎又准确,但代价高昂且有时过于犹豫。较弱的模型大胆但更容易出错,尤其是在非英语环境和来自全球南方的报道中。作者主张 AI 应当支持而非替代人工事实核查员,政策与设计选择必须推动更好的校准——教会系统何时保持沉默——并促进对优质工具的更公平获取。否则,本意用来对抗错误信息的同一技术,可能会加深它试图解决的信息不平等问题。
引用: Qazi, I.A., Khan, Z., Ghani, A. et al. Large language models show Dunning-Kruger-like effects in multilingual fact-checking. Sci Rep 16, 7594 (2026). https://doi.org/10.1038/s41598-026-39046-w
关键词: 错误信息, 事实核查, 大型语言模型, AI 置信度, 多语种偏差