Clear Sky Science · zh
基于深度强化学习的人形控制策略以提高下肢康复机器人舒适性
帮助人们重获行走能力的机器人
当中风或脊髓损伤后有人行走困难时,治疗往往既缓慢又疲惫,且伴随不适。下肢康复机器人旨在在训练中支撑并引导患者的腿部,但现有机器通常感觉僵硬、像“机器”。本研究探讨通过赋予这些机器人更类人的“大脑”——使用先进的学习算法——如何使训练更温和、更自然,并最终更有效地帮助患者。
为什么行走训练需要感觉自然
随着人口老龄化,更多人面临严重的行走问题,许多人转向机器人辅助康复。传统机器人遵循预设的腿部轨迹并使用简单的控制规则来驱动关节。虽然可靠,但这些方法难以应对人的动作中的复杂性:每个人的步态都有所不同,僵化的机器人可能以令人尴尬甚至疼痛的方式拉扯或推挤。作者认为,要使康复取得良好效果,机器人不仅必须保持患者直立并移动,还应适应自然的行走模式并尽量减少其施加在身体上的力。
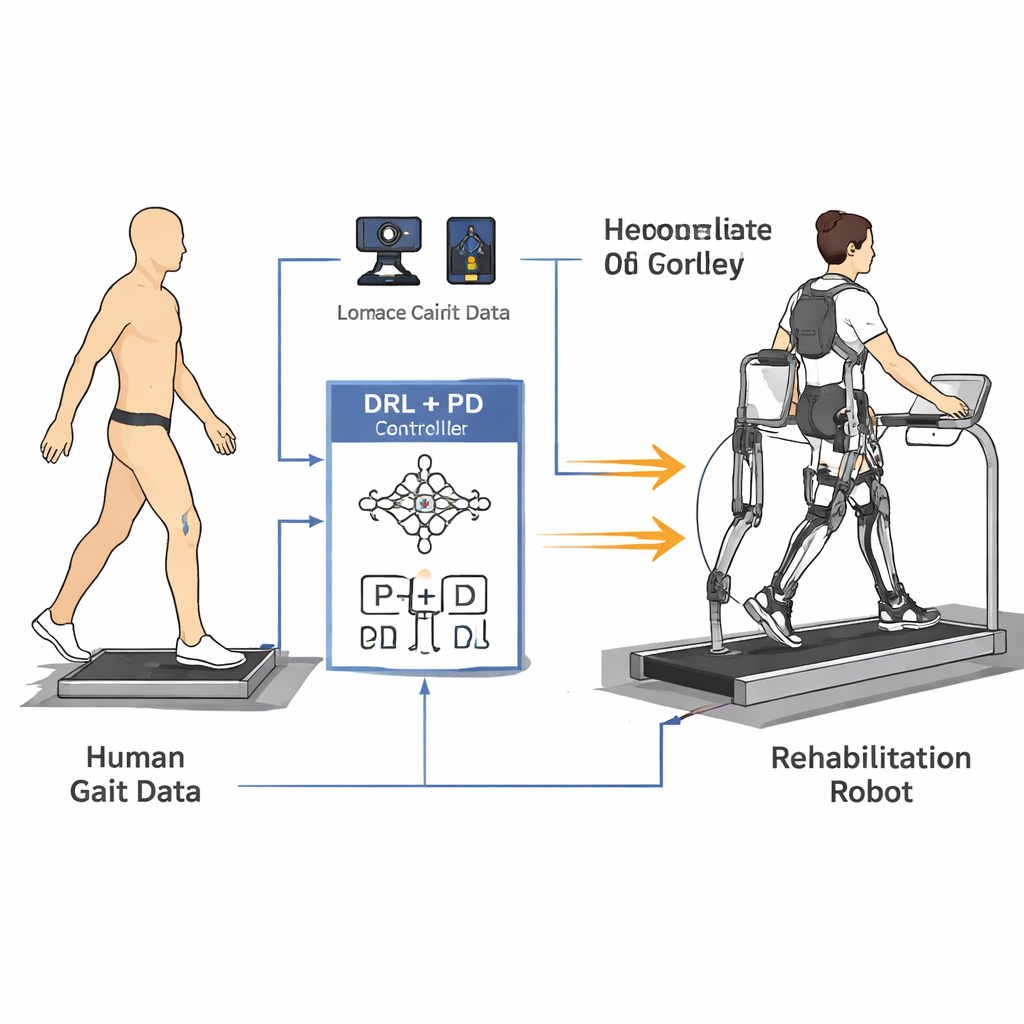
从真实步态中学习
为教会机器人人类真实的行走方式,研究者首先建立了腿部和躯干的简化数学模型。随后,他们使用高精度三维动作捕捉系统和地面力板记录了五位健康志愿者的步态数据。髋部、膝部、踝部和躯干上的反光标记使他们能够计算每个关节在完整一步中的运动,而脚下的传感器测量了每条腿对地面的作用力。基于这些测量,他们生成了髋关节和膝关节角度的平滑参考曲线,并跟踪关节力随时间的变化,既捕捉了正常步态的形状也捕捉了节奏。
更智能且仍保持安全的控制器
论文的核心是一种新的“人形”控制策略,将深度强化学习(DRL)与经典的比例-微分(PD)控制器结合。DRL是一种人工智能方法,虚拟智能体尝试动作、观察结果,并通过最大化奖励信号逐步发现最佳策略。在本工作中,智能体置于PD控制器之上:它观察机器人的关节角度和速度并决定施加何种力矩,而PD层则确保关节不会远离安全、类人的目标角度。奖励函数被精心设计,以鼓励稳定的向前行走,同时惩罚会让患者感觉不适的行为——例如突兀的运动、关节处的大力或不安全的姿势,如过度倾斜或足部通过地面的高度过低。
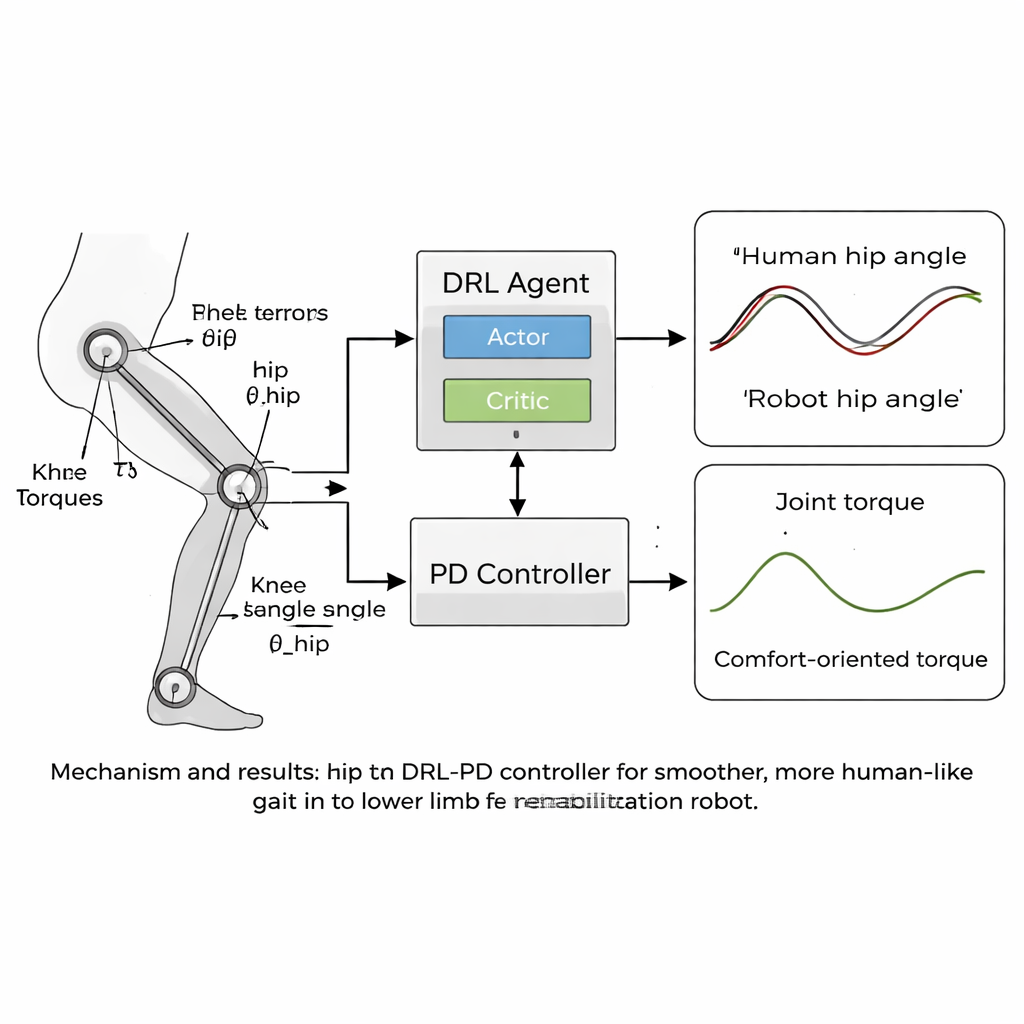
更平滑的运动,更接近人类步态
团队在计算机仿真中测试了他们的方法,使用与其步态数据匹配的髋关节和膝关节的下肢康复机器人模型。经过数千次训练回合,DRL-PD控制器学会产生重复的行走循环,其中关节角度与人类参考模式紧密吻合。机器人的髋部和膝部以规律、稳定的轨迹运动,这是可靠、可重复步态的标志。关键是,与标准PD控制器相比,驱动关节所需的力矩变得更平滑且更小。定量指标显示,跟踪误差降至仅几百分之一弧度,且关节力矩变化率——作为患者感受到“突兀”力的代理量——减少了超过一半。当模型的腿部质量变化几个百分点时,控制器仍保持稳定,这表明它能容忍用户之间的现实差异。
这对未来康复机器人的意义
对非专业读者而言,要点非常清晰:通过让机器人从真实数据中学习人类行走的节奏和限制,并通过奖励其平滑与温和的行为,我们可以设计出使人练习行走时感觉更自然、压力更小的机器。若机器人与患者协同而非对抗,患者可能更愿意参与更长、更多次的训练。尽管当前结果来自仿真并且训练需要高性能计算,但一旦学习完成,该控制器可以在真实设备上高效运行。作者将此工作视为朝向个性化、适应性康复机器人的一步,这类机器人能根据每位患者独特的步态和舒适需求进行调整,有可能改善康复效果和生活质量。
引用: Jin, Y., Zhang, J., Li, W. et al. A humanoid control strategy based on deep reinforcement learning for enhanced comfort in lower limb rehabilitation robots. Sci Rep 16, 7370 (2026). https://doi.org/10.1038/s41598-026-39011-7
关键词: 康复机器人, 步态训练, 深度强化学习, 外骨骼, 患者舒适性