Clear Sky Science · zh
一种用于连续手语识别的双流深度学习框架,以增强哈伊勒地区的沟通可及性
弥合沟通鸿沟
对于许多聋人来说,手语是主要的沟通方式,但大多数电脑、手机和公共服务仍然无法理解手语。本文提出了一种新的人工智能系统,能够观看视频中的连续手语并更准确地将其转换为书面文字。该系统不仅关注手部动作,还关注头部位置和面部线索,旨在使基于技术的沟通更自然、更易获得——特别是在沙特阿拉伯哈伊勒地区,那里数字支持仍然有限。 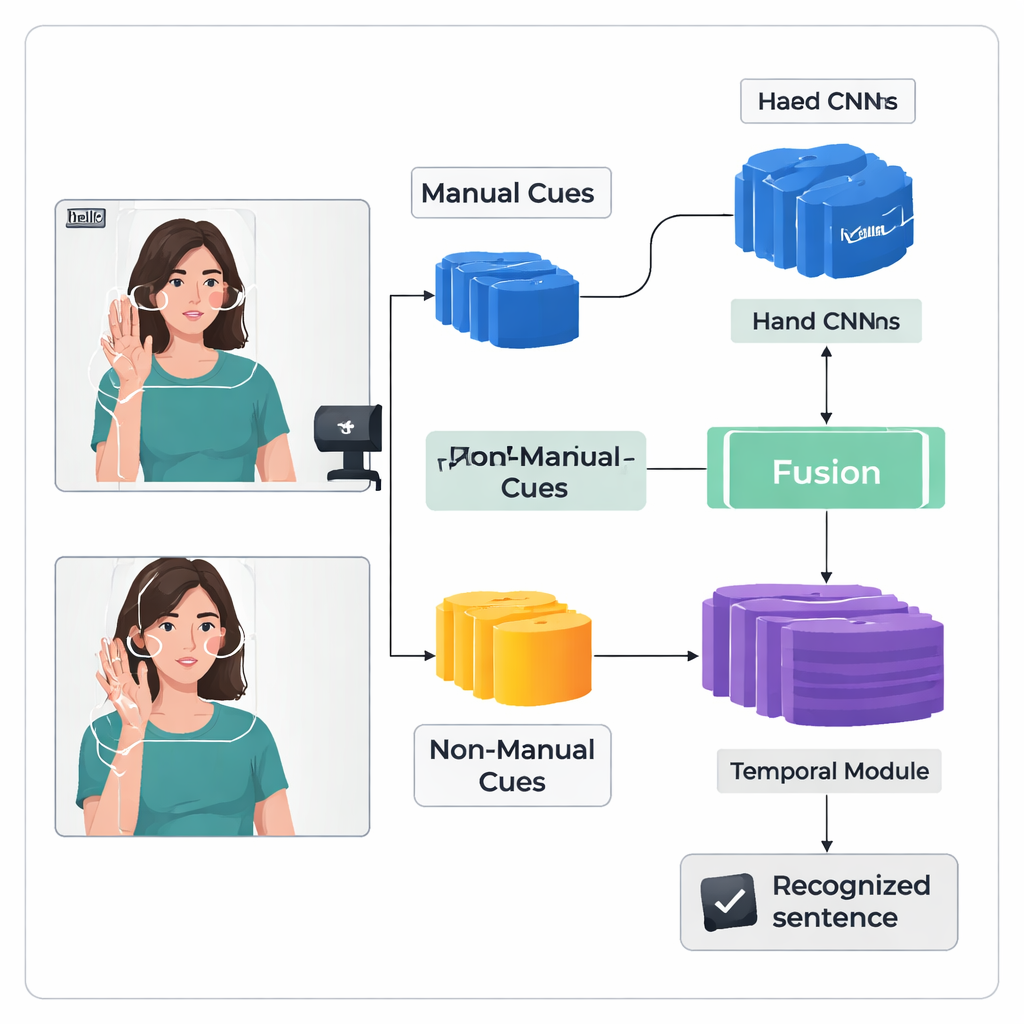
仅靠手势并不够
手语是丰富且复杂的系统,使用整个上半身来表达意义。意义不仅来自手的运动,还来自面部表情、注视方向以及头部的倾斜或点头。这些非手部信号可以标示疑问、否定、强调或情绪。人类能轻松解读这些信息,但大多数手语识别的计算机系统几乎只关注手部。虽然这种捷径简化了训练,但会丢失重要线索,尤其是在手势以快速、连续的句子形式出现而非孤立单词时。
并行工作的两条流
作者提出了一种称为 TS-CNN 的“双流”深度学习框架,分别处理手部和头部信号,然后将它们融合。一路专注于裁剪出的手部图像,学习形状、运动和位置的模式;另一路接收由面部关键点和头部姿态估计得到的紧凑脸部与头部映射。两条流都使用标准的视觉网络将每帧视频转换为数值特征。系统随后按帧融合这些特征,尊重手部和头部线索在真实手语中同时出现的事实。后续的时序模块跨多帧观察手势如何展开,循环层则生成预测的手语单元或注记序列(gloss)。
强化系统对手势的记忆
识别连续手语具有挑战性,因为训练数据有限且手势在时间上模糊、缺乏逐帧标签。为了解决这一问题,作者加入了特征增强模块,在训练期间为网络提供额外指导。一种广泛使用的技术将预测的注记序列与视频对齐,产生每个注记在时间上的可能位置。新的模块利用这些对齐建议作为直接的监督信号,以细化注记特征的内部表示。简单来说,系统不仅学习输出正确的序列,还学习构建更清晰、更一致的内部“记忆”,以表示每个手势在不同视频中的样貌。
将方法付诸测试
研究团队在两个知名的手语数据集上评估了 TS-CNN:用于德国手语的 RWTH-PHOENIX-Weather 2014 和用于中文手语的 CSL Split II。他们使用与语音识别类似的标准指标——字错误率来衡量性能。与仅观察手部动作的基线相比,加入头部姿态信息使德国数据的错误率降低了约 4 个百分点,在中文数据上降低了约 3–4 个百分点。加入特征增强模块则带来更大的提升,在两个数据集上总体将错误率减少约 10–14%。该系统运行效率也良好,在现代图形处理器上可达到实时速度,这对用于现场口译或移动工具至关重要。 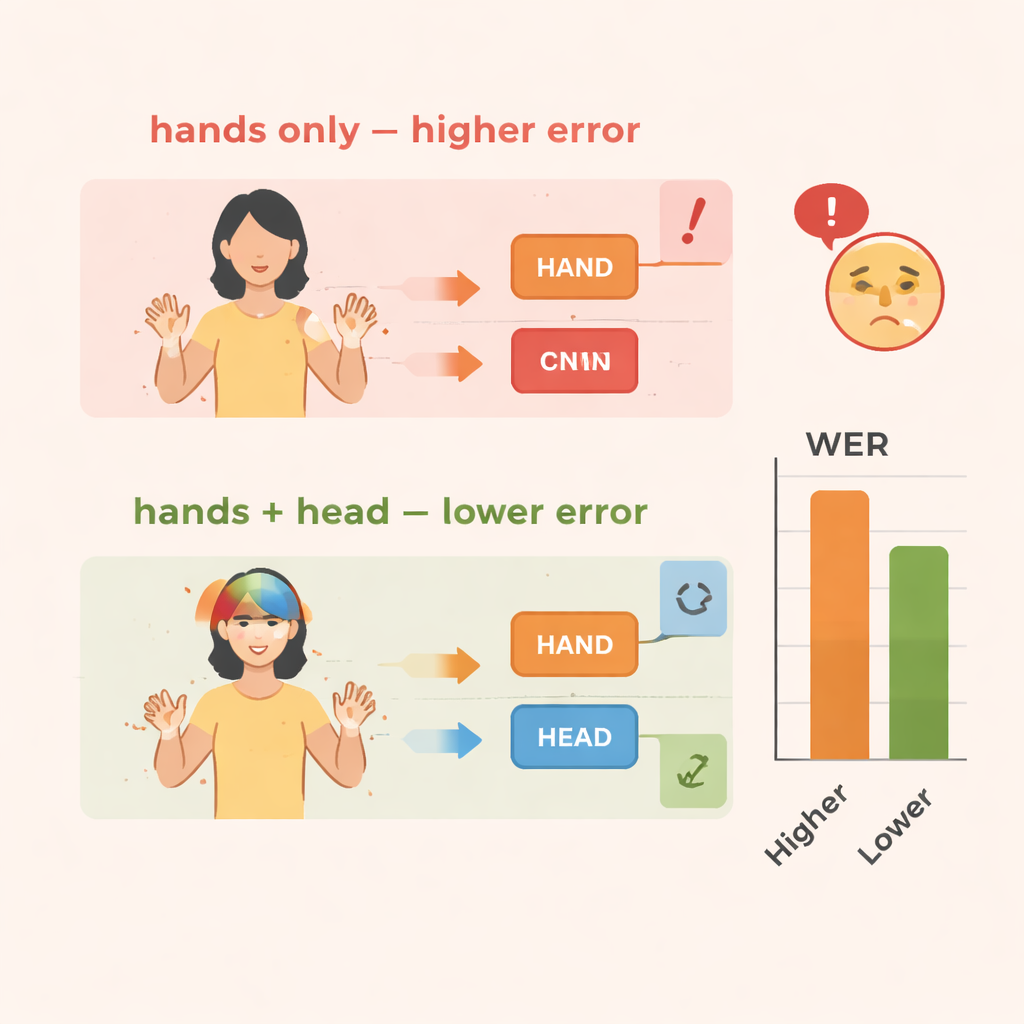
对日常生活的意义
用日常术语来说,这项研究表明,当计算机观察完整的示范者而非仅仅观察双手时,它们对手语的理解更可靠。通过将头部动作和面部线索与手部运动一起建模,并通过精细化有限训练数据的学习过程,TS-CNN 框架向实用系统更进一步,这类系统可以在教室、医院和公共机构中帮助聋人。对于像哈伊勒这样人工翻译稀缺且技术项目尚在起步的地区,这样的系统最终可能支持更具包容性的沟通——在不取代手语丰富人类体验的前提下,帮助弥合手语使用者与听力世界之间的差距。
引用: Harrouch, H., Guesmi, H., Alalfy, H. et al. A dual-stream deep learning framework for continuous sign language recognition to enhance communication accessibility in the Ha’il region. Sci Rep 16, 7070 (2026). https://doi.org/10.1038/s41598-026-38912-x
关键词: 手语识别, 深度学习, 无障碍, 计算机视觉, 人机交互