Clear Sky Science · zh
通过无监督方法估算物种常见性与普遍性
为何统计常见种与稀有种很重要
当我们想象自然面临威胁时,常会想到那些濒临灭绝的稀有动物。然而,我们周围的大多数生物构成往往由非常普通的物种组成——它们要么很常见,要么在无人察觉的情况下悄然消失。能够判断一种物种在某一地点究竟有多广泛,对于预测生态系统如何应对污染、土地利用变化或气候变化至关重要。本文介绍了一种方法,利用现成的观察记录和现代数据分析技术,同时估算大量物种的常见性或稀有性。其目的是为用于预测物种现今与未来分布的计算模型提供更客观的先验输入。
从简单的目击记录到重大的生态学问题
生态学家常用一种称为生态位模型的计算工具,来判断哪类环境适合某一物种生存。这类模型能预测在气候变化或入侵新地区时物种可能出现的地点。一个关键要素是“普遍性”——大致上指在被调查的地点中物种出现的比例。普遍性体现了在进行新调查之前,一种物种被期望是常见还是稀有。这一先验预期会显著影响模型如何将原始适宜性分数转换为存在的概率,以及如何在地图上划定“存在”和“缺失”的界线。如果普遍性估计不准确,尤其是对稀有物种,预测可能产生误导,保护计划也可能关注错误的地区。
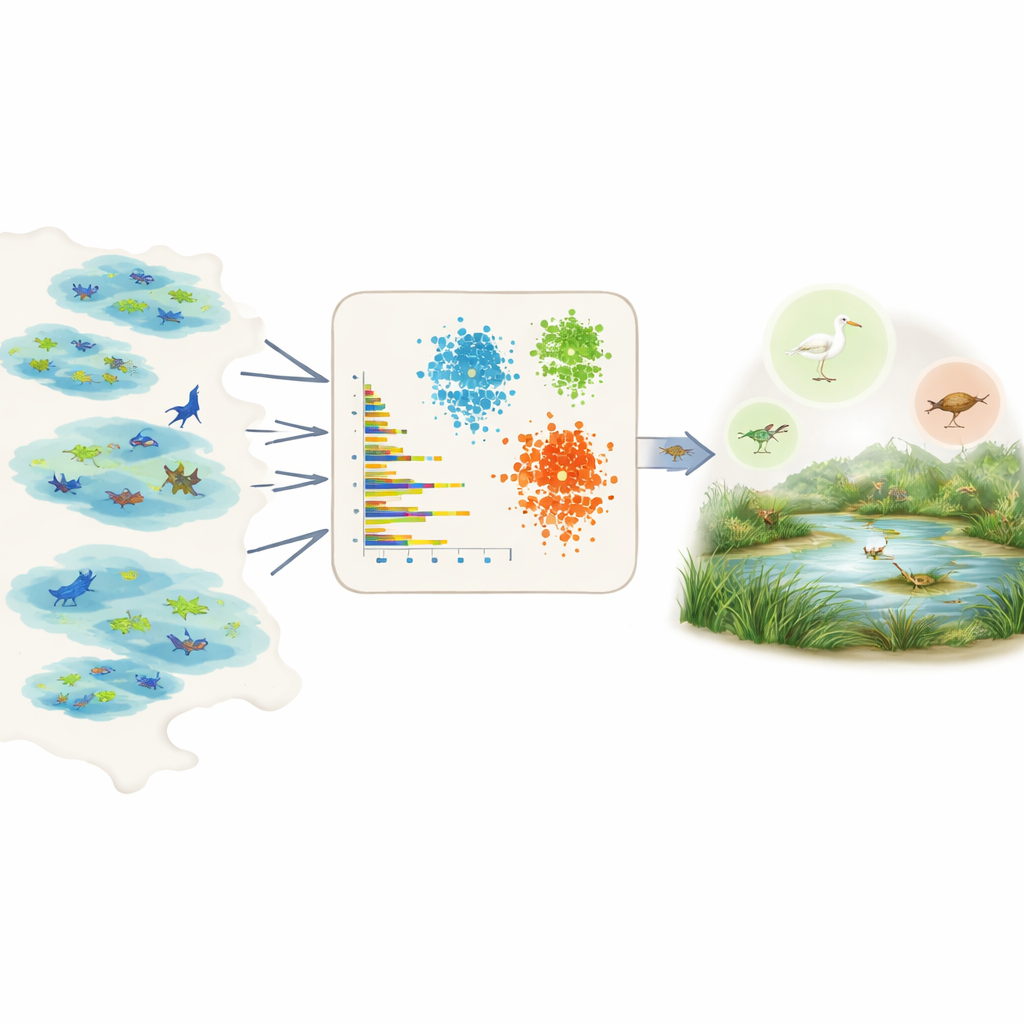
让数据为数百种物种发声
直接测量普遍性很困难,因为实地数据常常不完整且存在偏差。有些地区调查频繁,有些物种更容易被发现,而且许多记录来自调查努力不均的公民科学项目。作者没有依赖每个物种的专家意见或详细先验知识,而是利用了全球生物多样性信息机构(GBIF)这一庞大的开放物种观测数据库。对于所选区域的每一个物种,他们将原始记录汇总为少数几个简单且可比较的数值:每次目击通常报告的个体数、包含该物种的不同数据集或湿地数量、该物种在这些湿地内的分布广度,以及随时间的观察频率,包括是否经常出现大量观测的集中爆发。
教机器区分常见种与稀有种
利用这些汇总特征,研究团队应用了三种无监督学习工具——两种聚类方法和一种称为变分自编码器的深度学习模型——这些方法在事先不知道哪种物种常见或稀有的情况下寻找模式。聚类方法将具有相似丰度、分布范围和观测频率的物种归为一类。自编码器学习何为“典型”的物种记录,并将异常模式标记出来,这些异常常对应于稀有或记录不足的物种。随后,模型将每个物种分配到三个直观类别——非常常见、较常见或稀有——并将这些类别转换为数值化的普遍性值,可直接作为生态位模型的先验概率使用。
在脆弱湿地中检验该方法
为评估该框架在实际中的表现,作者将注意力放在意大利托斯卡纳的马萨丘科利湖盆地——一个低洼湿地,栖息着丰富的鸟类、鱼类、昆虫及其他动物。该地区既是生物多样性热点也是旅游胜地,但也易受气候变化、缺水和污染的影响。针对与湖泊相关的161种动物,模型使用来自意大利其他湿地的记录进行训练,然后推断每种在马萨丘科利的常见程度。两位在该地区有深厚实地经验的本地专家独立对同一批物种进行了评估。比较结果显示,深度学习模型与专家综合意见在约81%–90%的物种上达成一致,而聚类方法及三种方法的集成也表现良好。
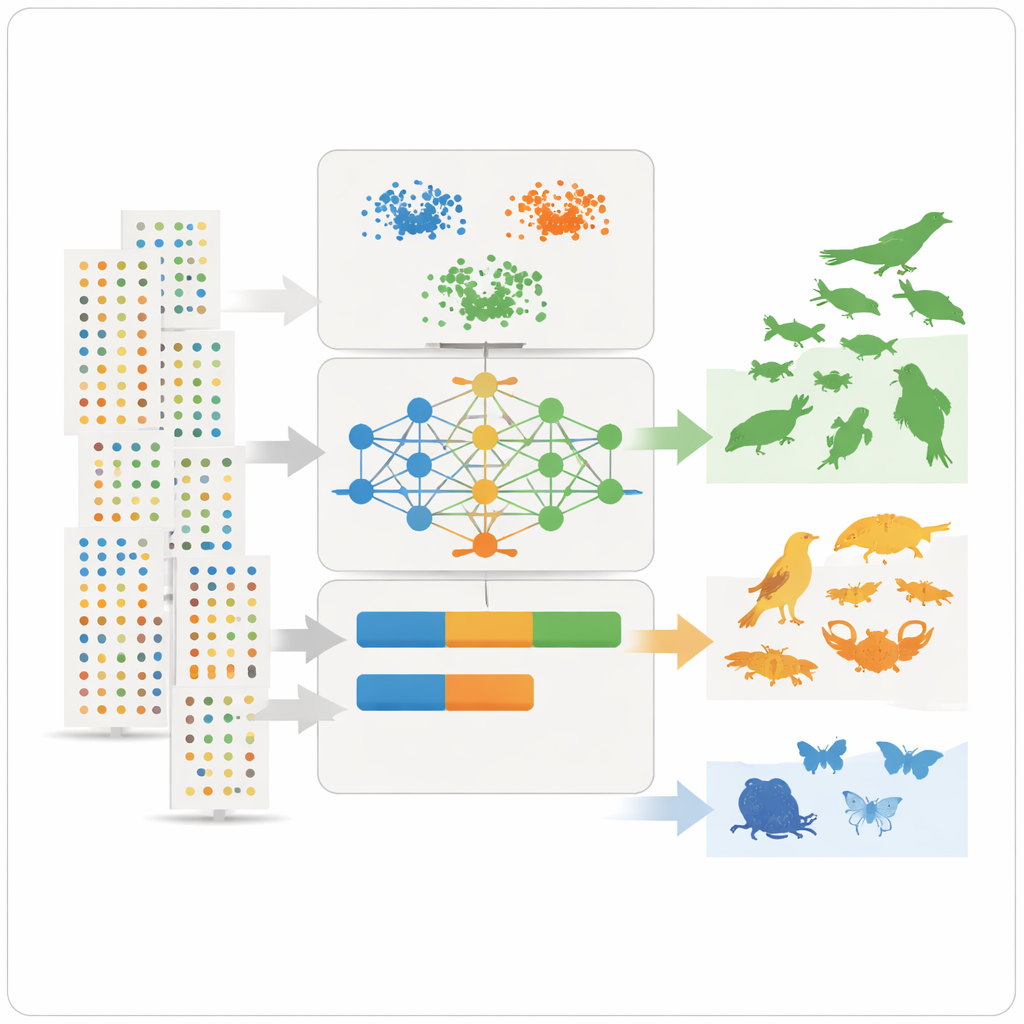
从分歧与隐性偏差中学习
并非所有情况都完全一致。有几种专家熟知在湖区很常见的物种在数据中显得稀少,通常是因为它们难以被发现、被低报,或在部分湿地受到更多关注。这突显了一个关键限制:大型数据库反映的是人们在哪里以及如何观察自然,而不仅仅是物种真实的分布。灵敏度分析显示,哪些特征对分类最为重要,其中每个数据集的平均记录数、每次目击的个体数以及多年观测的一致性尤为有信息量。尽管存在偏差,该方法仍产生了清晰且可重复的普遍性估计,并且可以根据建模需要调整为更细或更粗的类别。
这对未来自然预测意味着什么
对非专业读者来说,主要信息是:我们现在可以更智能地利用现有的生物多样性数据来判断在特定环境中哪些物种可能是常见的、中等的或稀有的,而无需为每一种情况手工微调。通过将嘈杂的观测记录转化为透明且以数据为驱动的普遍性估计,这一框架帮助生态模型作出更现实的栖息地适宜性与未来生物多样性趋势预测。反过来,这能支持对马萨丘科利等湿地以及全球许多其他生态系统的更好规划,即便实地数据不完整且专家时间有限。
引用: Bove, P., Bertini, A. & Coro, G. Estimating species commonness and prevalence through unsupervised methods. Sci Rep 16, 8331 (2026). https://doi.org/10.1038/s41598-026-38900-1
关键词: 物种普遍性, 生物多样性建模, 湿地生态系统, 机器学习生态学, 物种常见性