Clear Sky Science · zh
使用支持向量机(SVM)评估TATA结合蛋白(TBP)与多种蛋白域折叠模式的进化关系
一种DNA“开关”蛋白如何与多种蛋白建立联系
TATA盒结合蛋白(TBP)是细胞中的一名主力:它通过在许多启动子处抓住DNA来帮助基因开启。该研究提出了一个表面看似简单但影响深远的问题:是否存在其他执行截然不同功能的蛋白,暗中共享TBP的基础形状?通过结合三维结构比较、序列分析和现代机器学习工具,作者追踪了TBP与参与代谢、神经递质化学乃至癌症相关通路的蛋白之间隐藏的家族联系。
基因调控核心的一个关键蛋白
TBP位于从酵母到人类等生物的基因表达入口处。它识别称为TATA盒的短DNA序列并弯曲DNA,帮助组装将基因转录为RNA的大型转录机器。由于这一步极为关键,TBP核心的折叠——即三维排列——在进化中高度保守。作者以被广泛研究的TBP结构(编号为1tba)为探针,搜索可能共享其构架蓝图的其他蛋白,即便它们的氨基酸序列和日常功能乍看之下非常不同。
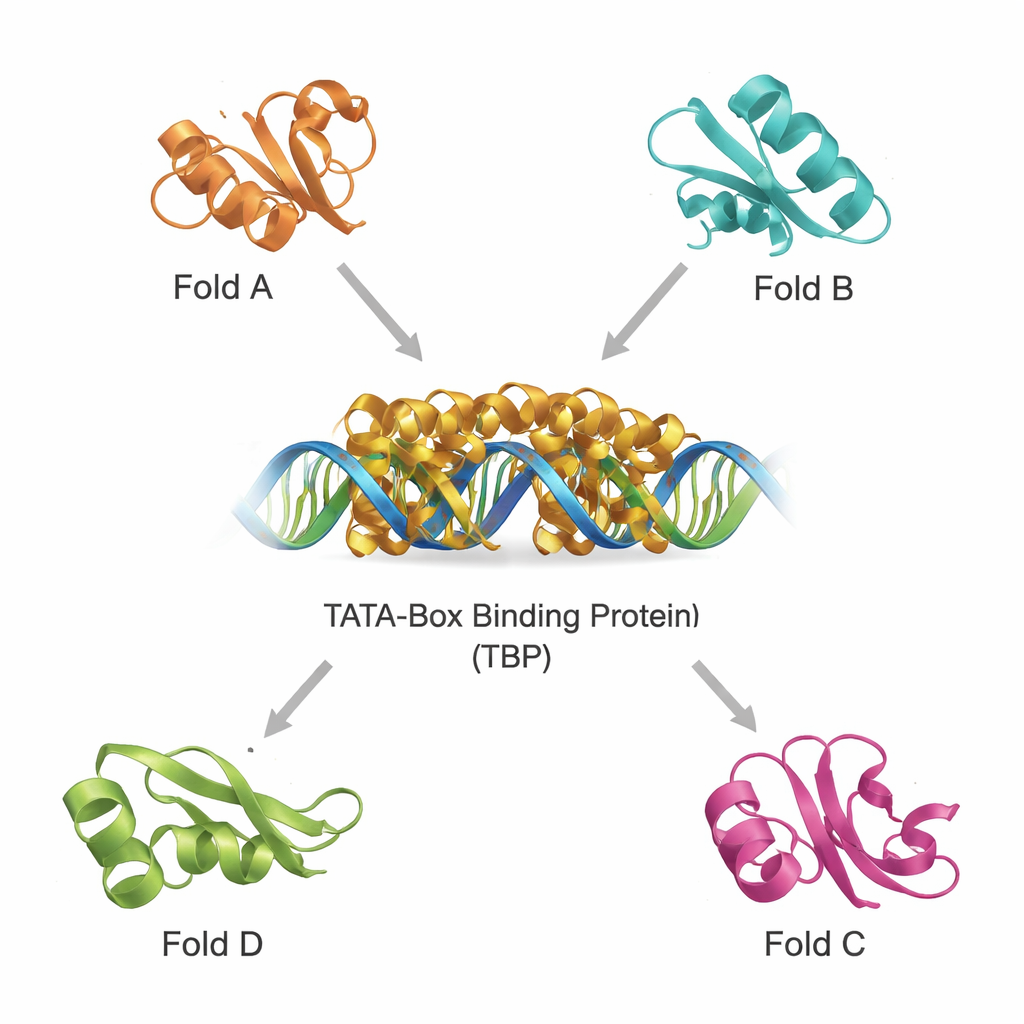
在繁杂的蛋白世界中寻找结构近亲
现代数据库包含数十万的蛋白结构,使得能够按三维形状而非仅按序列来扫描远缘亲属变得可行。研究团队使用两种强大的工具,DALI和TOP‑search,首先挑选出折叠看起来像TBP的蛋白。随后他们用进化域目录对这些候选进行分类,并缩小到一小组结构相似但功能多样的例子。其中包括在代谢中重要的谷氨酰胺合成酶样酶、出现在多种tRNA处理酶中的一个域、具有典型“热狗”折叠且参与脂肪酸化学反应的酶,以及帮助合成四氢生物喋呤(对大脑功能至关重要)的蛋白。将它们的结构与TBP叠加显示,尽管功能不同,它们共享可识别的核心基序。
教机器识别隐藏的蛋白家族
为了超越逐例检查,作者构建了可自动标记TBP样折叠的机器学习模型。他们汇集了已知属于TBP或各相关折叠的大量蛋白序列集,以及一组广泛的“背景”无关蛋白。每个蛋白被转换为简单的数值概要:每种氨基酸的出现频率,以及序列中每对氨基酸出现的频率。这些描述输入到支持向量机(SVM)和随机森林模型中,模型学会将一种折叠类型与其他类型区分开来。通过严格的交叉验证,模型达到了很高的准确率——通常超过95%,即便只用对应保守区域的序列片段训练时亦是如此。
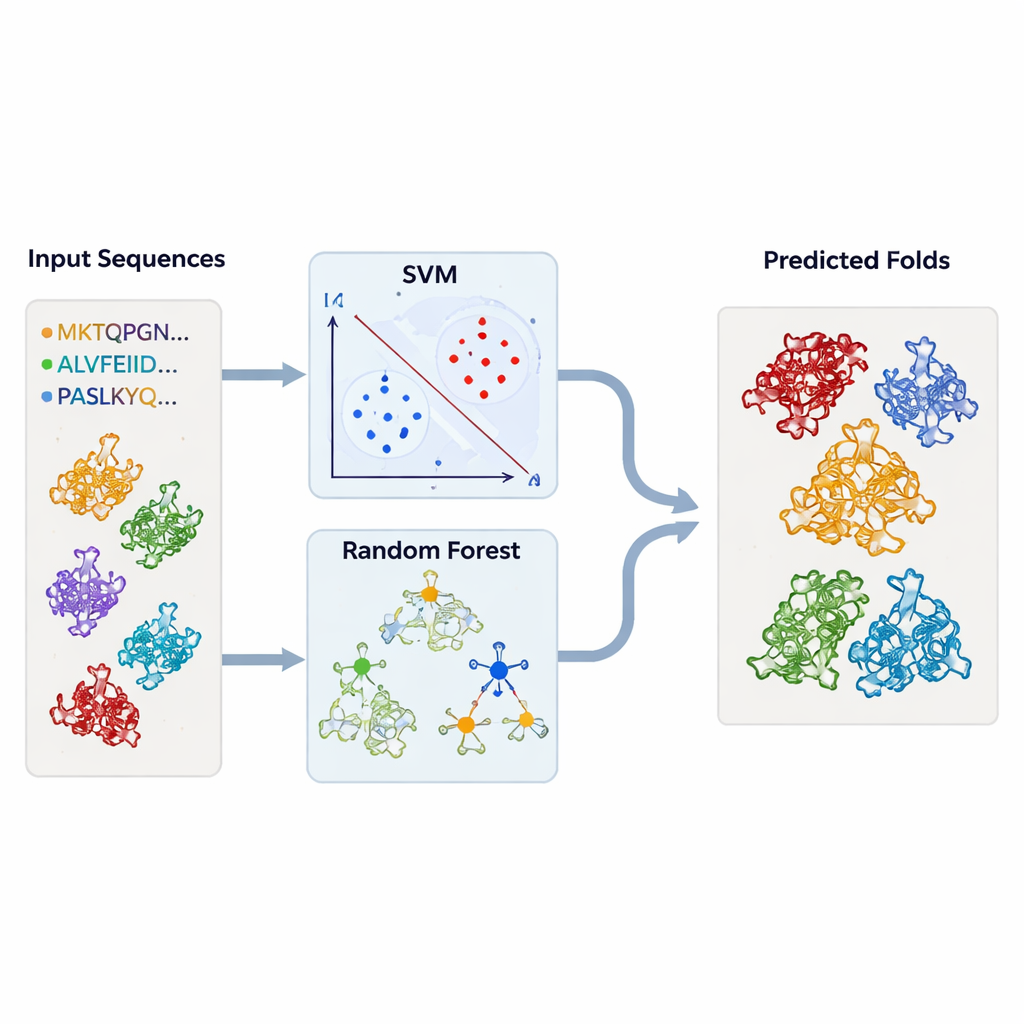
在成千上万未知结构上测试模型
凭借这些训练好的分类器,团队回到结构数据库。他们将从DALI和TOP‑search检索的数千条蛋白链输入模型,查看哪些显示出TBP样或相关折叠的统计特征。SVM和随机森林方法大体一致,并挑选出了许多结构工具也标记为相似的候选。在某些情况下,表面上功能无关的酶仍然与TBP或彼此强烈聚类,强化了进化可以将相同基础框架改造用于多种生化功能的观点。
这些隐藏联系为何重要
研究得出结论:TBP与若干酶家族存在深层结构血缘关系,包括类似谷氨酰胺合成酶的蛋白和tRNA加工酶的编辑域。即使序列发生漂变、功能已分化,这些蛋白仍保留共同的结构基序,提示它们来自共同祖先。对非专业读者来说,关键信息是自然倾向于重复使用成功的设计:一个折叠可以反复被改造以解决截然不同的问题,从开启基因到微调代谢与脑化学。通过将三维结构比较与机器学习结合,作者提供了一套实用工具来揭示此类关系,帮助生物学家预测未注释蛋白的可能功能,并为药物开发者指示基于进化的、与疾病相关的新靶点。
引用: Selvaraj, M.K., Kaur, J. Evaluating the evolutionary relationship of TATA binding protein (TBP) with various folding patterns of protein domains using support vector machine (SVM). Sci Rep 16, 7696 (2026). https://doi.org/10.1038/s41598-026-38883-z
关键词: TATA盒结合蛋白, 蛋白质进化, 机器学习, 蛋白质结构, 支持向量机