Clear Sky Science · zh
基于串联级联混合自适应深度网络并辅以优化方法的歌词文本分类
为何更智能的歌曲过滤很重要
音乐几乎不断地流入我们的生活,而我们听到的许多内容是由算法挑选的。然而,许多系统仍然难以回答一个简单问题:一首歌的歌词到底在表达什么,适合什么样的听众?本文通过构建一个先进的人工智能(AI)模型来解决这一问题,该模型能够自动阅读歌曲歌词,并按情绪、流派、情感甚至表演者类型对其进行分类。目标是帮助为儿童创建更安全的播放列表、提供更准确的基于情绪的推荐,并为音乐研究人员提供更好的工具。
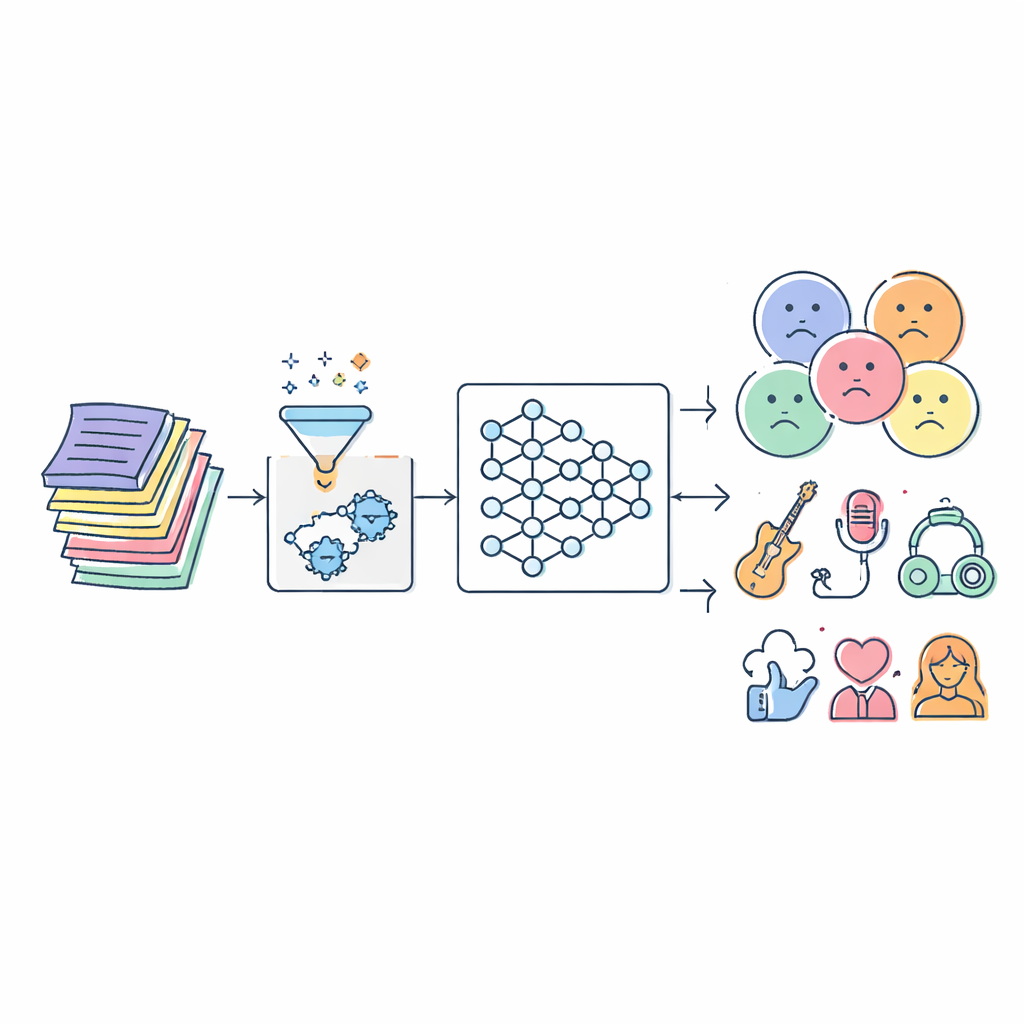
歌词中的挑战
歌词远比一张善恶词表复杂得多。同一句话在一首歌里可能显得温柔,而在另一首歌里又显得威胁性十足,听众还会把自己的经历带入理解之中。传统过滤器通常依赖静态的侮辱词表或简单的统计技术。这些方法忽略语境,难以跟上不断变化的俚语,并且经常给歌曲贴错标签。与此同时,数字音乐的爆炸性增长意味着需要分析的曲目达到数百万首,涉及多种语言和风格,这让人工标注和老旧算法不堪重负。
清理原始歌词
作者首先从三个公开数据集中汇集大量歌词,这些数据集合起来涵盖了跨越多种流派和语言的数十万首歌曲。在任何AI开始从文本中学习之前,歌词必须先经过清洗。系统会移除标点、特殊符号以及重复或无关的片段,然后将相关的词形还原为共同词根(例如“singing”、“sings”和“sang”都被归为“sing”)。这一预处理步骤剥离了噪音同时保留语义,使后续阶段能专注于情绪色彩和主题,而不是格式差异或拼写变体。
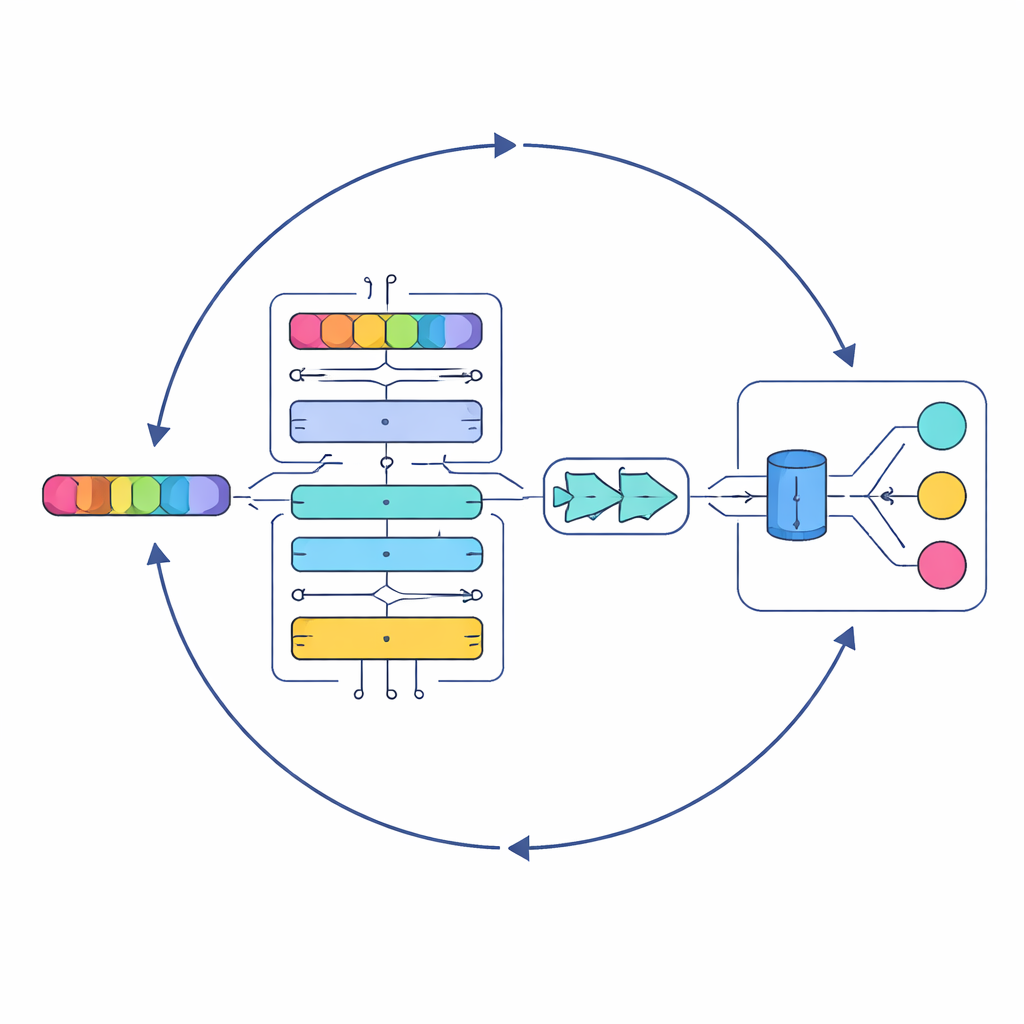
像细心听众一样分层阅读的AI
该研究的核心是一种称为串联级联混合自适应深度网络(Serial Cascaded Hybrid Adaptive Deep Network,简称SCHADNet)的新模型。它结合了现代语言AI的三种强大思路。首先,基于Transformer的编码器可以捕捉歌词中跨句的词语关系,而不仅限于相邻词。其次,双向长短期记忆层(BiLSTM)前后双向读取歌词,帮助系统理解前句如何影响后句的含义。第三,门控循环单元(GRU)层将这些信息精炼为适合最终决策的紧凑摘要。共同作用下,这些组件就像一组分工明确的读者合唱团,各自专注于歌词文本的不同方面。
借鉴海洋捕食策略
简单叠加深度学习层并不足以保证性能;它们的内部设置——例如神经元数量和训练时长——对性能有重大影响。作者没有手动调参,而是采用一种受海洋捕食者捕猎模式启发的优化方法。他们的改进型海洋捕食者算法(Improved Marine Predators Algorithm,IMPA)探索多种可能的参数组合,逐步锁定那些产生最佳结果的组合。通过裁剪在此场景下无益的原始算法部分,他们改进了收敛性,使系统更快、更可靠地达到良好解。
系统表现如何
研究人员在三种不同的歌词数据集上用IMPA测试了SCHADNet,并与多种已建立的方法进行比较,包括经典的机器学习分类器以及若干流行的深度学习模型,如纯LSTM、仅Transformer的系统和混合网络。在准确率、召回率(找回多少真实相关歌曲)等质量指标上,这一新方法始终表现优异。在一个大型多语种数据集上,它正确分类了大约93%的歌曲,并且在阴性预测值上表现尤其高——这意味着它在识别不应被标记的歌词方面非常可靠,这一点对避免过度封锁或错误标注至关重要。
对听众与创作者的意义
对普通读者而言,结论很直接:作者构建了一个更细致、可靠的歌词“阅读器”。与依赖粗糙词表的方法不同,该系统考虑整句、语境以及跨大规模曲库的模式,然后自动分配如情绪、风格或是否适合未成年人等标签。尽管该模型复杂且计算资源需求高,它为更智能的家长控制、更丰富的情绪播放列表以及研究流行音乐趋势的新途径打开了大门。未来的工作旨在减少其对数据的需求并加快训练速度,但即便在现有形式下,SCHADNet也指向了一个音乐平台能几乎像细心的人类听众那样理解歌词的未来。
引用: Jasmine, R.L., Mukherjee, S., Robin, C.R.R. et al. Serial cascaded hybrid adaptive deep networks-based lyrics text classification using optimization approach. Sci Rep 16, 8527 (2026). https://doi.org/10.1038/s41598-026-38813-z
关键词: 音乐推荐, 歌词分析, 文本分类, 深度学习, 内容审查