Clear Sky Science · zh
使用可解释提升算法与SHAP分析对化学需氧量进行准确且可解释的预测
为什么要关注河流的含氧量
河流是城市和农田的生命线,但当它们被来自工厂、下水道或农田的有机废物充满时,水体会被耗氧并对人类和生态系统构成危险。衡量河流健康的常用指标是“化学需氧量”(COD),它表示分解污染物所需的氧气量。在实验室测量COD耗时且成本高昂,因此本研究探索了能否使用先进但可解释的机器学习工具,基于常规传感器数据可靠地预测COD——并清晰展示导致污染的主要因素。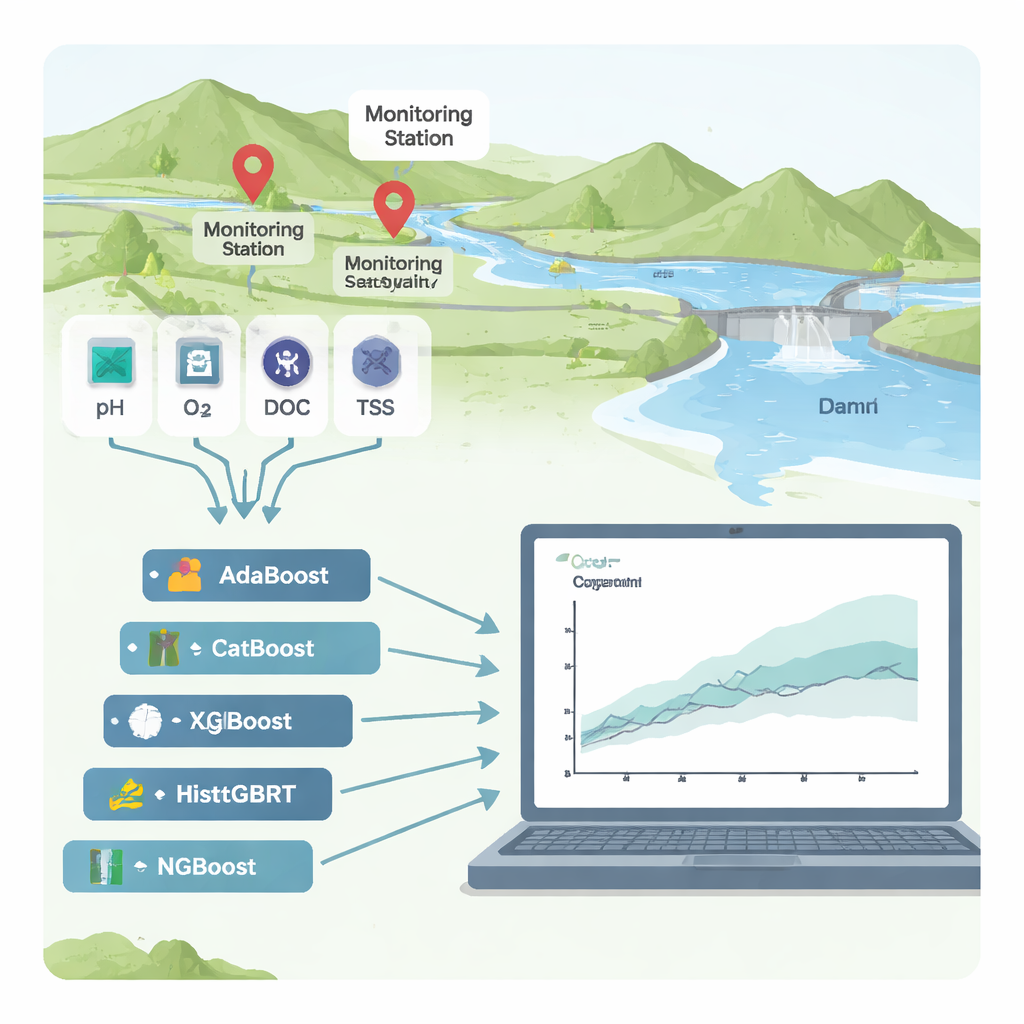
污染世界的智能模型
研究者把重点放在韩国两个河流监测站:位于多功能永州大坝上游的黄旨站和退一川站。在这些站点,有数十年的常见水质指标记录:酸碱度(pH)、溶解氧、悬浮物(水中的细颗粒)、氮磷等营养盐、总有机碳(TOC)、生化需氧量(BOD₅)、水温、电导率和河流流量。研究团队没有构建传统的基于物理的模型(这类模型往往难以在不同河流间迁移),而是测试了六种“提升”(boosting)算法——一种将许多简单决策树组合成强预测器的强大机器学习家族。
寻找最佳的河流“预报器”
为比较这六种提升方法(AdaBoost、CatBoost、XGBoost、LightGBM、HistGBRT 和 NGBoost),团队用大约70%的历史数据训练模型,并在剩余30%的数据上检验性能。他们用多种统计量评估准确性,这些量度既衡量预测与真实COD测量值的接近程度,也衡量模型对未见情形的泛化能力。在退一川站,NGBoost模型(不仅预测单一数值而是给出COD的完整概率分布)明显胜出,几乎捕捉到了COD的全部变异且误差极小。在黄旨站——一个更复杂的监测点,CatBoost在准确性和稳定性之间取得了最佳平衡。有些模型,尤其是XGBoost,在训练数据上表现几近完美但在测试数据上表现欠佳,这是“过拟合”的典型表现,即模型记住了噪声而非学习到真实模式。
打开人工智能的黑箱
本研究的核心目标不仅是预测COD,还要解释模型为何做出这些预测。为此,作者使用了SHAP(Shapley 加性解释),该技术为每个输入变量分配对单次预测的正负贡献。在两个河流和大多数算法中,三项变量始终作为COD的主要驱动因素出现:总有机碳(TOC)、生化需氧量(BOD₅)和悬浮物(SS)。简单来说,水中有机物和细颗粒越多,需氧量越高。模型还揭示了站点差异:在退一川,流量(排放)和总磷的作用更强,提示农业面源径流等扩散性来源的影响更大;在黄旨,电导率与悬浮物的模式则暗示更多的是局部或工业来源。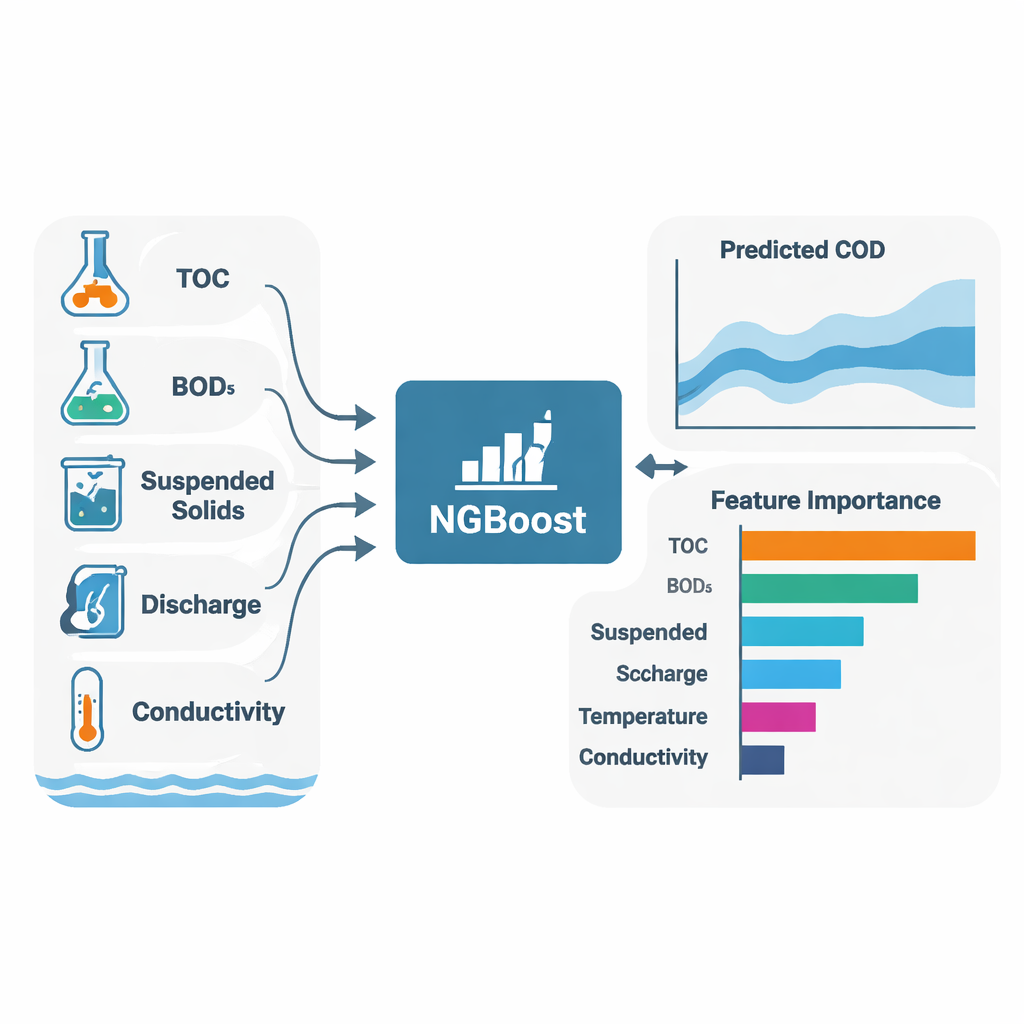
这些结果对真实河流的意义
这些见解表明,结合SHAP的提升模型可以超越作为不透明“黑箱”的局限。它们既能提供对河流需氧量的准确预报,也能给出关于各站点污染驱动因素的物理上合理的解释。这对必须优先确定监测项目和干预地点的水坝与流域管理者至关重要:如果TOC和BOD₅是最关键的杠杆,则控制有机物排放能带来最大的水质改善。NGBoost的概率性预测还提供了不确定性信息,这对预警系统和基于风险的决策尤为重要。简言之,该研究表明,精心设计的可解释AI可以通过将常规传感器读数转化为可靠、透明的河流健康预测,帮助保护饮用水库和水生生物。
引用: Merabet, K., Kim, S., Heddam, S. et al. Accurate and interpretable prediction of chemical oxygen demand using explainable boosting algorithms with SHAP analysis. Sci Rep 16, 6359 (2026). https://doi.org/10.1038/s41598-026-38757-4
关键词: 水质, 化学需氧量, 机器学习, 河流污染, 可解释人工智能