Clear Sky Science · zh
对波斯语风湿病学委员会考试中大型语言模型表现的评估:GPT-4o 与 GPT-5.1 的准确性与临床推理
这对医生和病人为何重要
人工智能正迅速进入医学院课堂和临床场景,但现有的大多数测评侧重于英语。本研究提出了对数百万波斯语使用者至关重要的问题:先进的 AI 聊天机器人,特别是 GPT‑4o 和 GPT‑5.1,能在多大程度上用波斯语应对复杂的风湿病学考试题目?答案能帮助教育者、受训者和病人了解这些工具在哪些方面可以安全辅助学习,哪些方面仍需依赖人类专业判断。
让 AI 接受考验
研究者收集了来自 2023 年和 2024 年官方伊朗风湿病学委员会考试的 204 道选择题,这些考试是专科医师获得认证所必需的。在剔除 7 道有缺陷的题目后,使用了 197 道题。每一道题(包括任何附带的图像或图表)均以波斯语输入到 GPT‑4o 和 GPT‑5.1 的单独新对话中。研究者要求模型选择最佳答案并解释其推理,模拟受训者在学习时向 AI 工具提问的方式。
检验答案与推理
表现通过两种方式评估。首先,将模型选择的选项与官方答案对照,得到一个简单的对错准确率指标。其次,六位通过委员会认证的风湿病学专家独立对每个解释的质量进行五分制评分,范围从明显错误的推理到完整且临床上可靠的推理。每个模型的答案由两位不同的风湿病学家评分,这些评分者对彼此的评分和官方答案均不知情。如此一来,研究者不仅能看到 AI 是否“猜对”,还可以判断其逻辑是否类似于专家的思维方式。
更新模型的表现如何
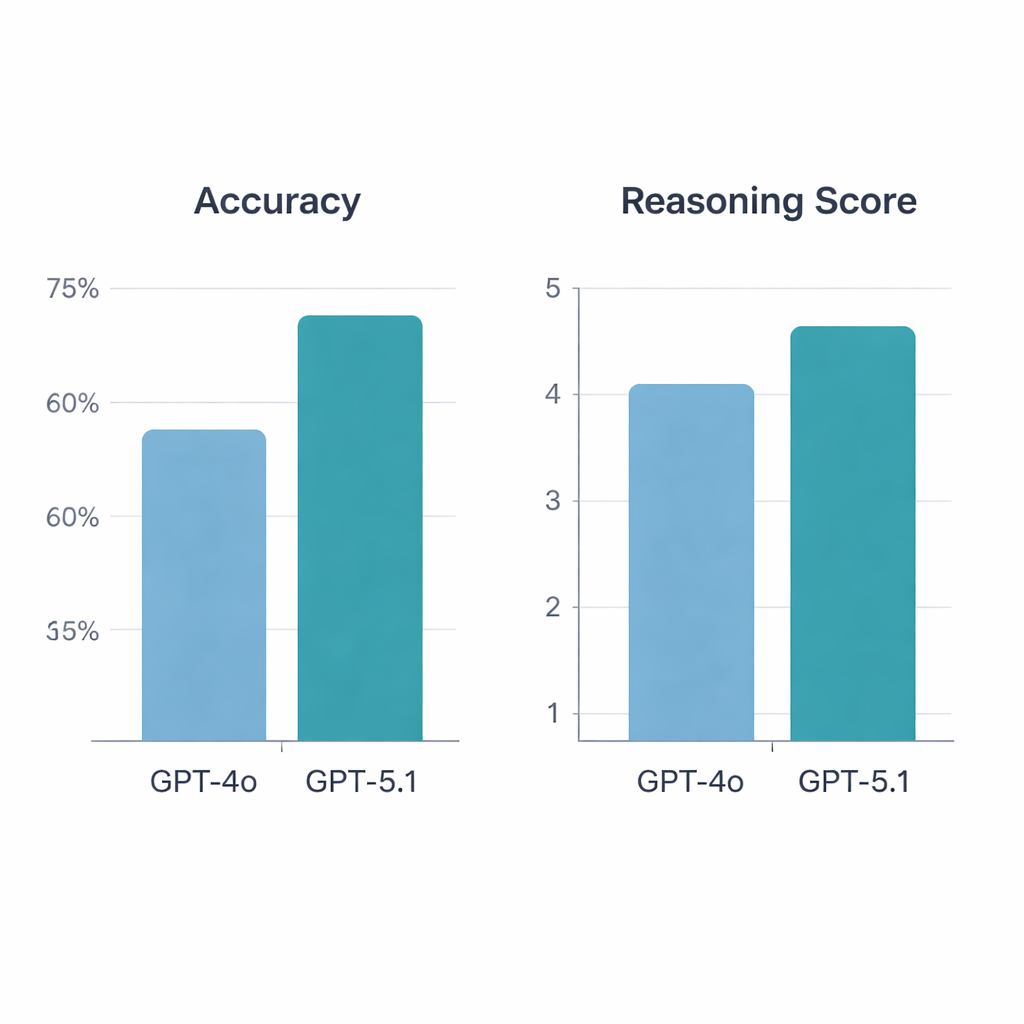
GPT‑5.1 明显优于 GPT‑4o。在 197 道有效题目中,GPT‑4o 的正确率为 64.5%,而 GPT‑5.1 达到 76%——这是一个具有统计学显著性的提升。两者都答对了 113 道题、答错了 34 道题,但 GPT‑5.1 单独答对了 GPT‑4o 未解出的另外 36 道题;GPT‑4o 独自答对的仅有 13 道。在风湿病学家对解释评分时,GPT‑5.1 仍然领先,其平均推理得分为 4.47(满分 5 分),而 GPT‑4o 为 4.13,且 GPT‑5.1 获得了更多的最高评分。与 GPT‑4o 不同,GPT‑4o 在基本科学、病例情景、诊断或治疗等不同题型上的推理质量波动较大,GPT‑5.1 在各类别间表现更均衡。
优势、欠缺与专家分歧
研究揭示了重要的细微差别。即便模型的最终答案错误,专家有时仍会认为其推理相当连贯,这突出显示了考试评分与实际临床思维之间的差距。与此同时,风湿病学评分者之间的一致性仅为中等水平,这强调了临床医生本身对于什么构成“良好推理”存在分歧。语言似乎也很重要:早期关于英语和西班牙语的研究报告了类似模型更高的评分,提示 AI 目前在处理主要世界语言方面仍优于波斯语。作者强调,这些聊天机器人可能会生成看似令人信服但包含事实性错误的解释,并且它们的表现会随着系统更新而变化。
对未来的意义
对于非专业读者,结论是:最新一代的 AI 聊天机器人在用波斯语处理专科医学考试方面确实有所进步,但还不足以取代严格的培训或专家判断。GPT‑5.1 可作为风湿病学受训者的有用学习伙伴——总结主题、逐步分析病例并提供结构化解释——但不应被信为诊断或治疗等重大决策的最终依据。作者呼吁进行更大规模的多语种研究、随时间重复测试以及真实的临床模拟,以确定如何将这些工具安全地融入医学教育,并最终纳入日常病人护理。
引用: Rafiei, F., Sadeghipour, S., Sheikhalishahi, S. et al. Evaluation of large Language model performance on Persian rheumatology board exams: accuracy and clinical reasoning of GPT-4o vs. GPT-5.1. Sci Rep 16, 7274 (2026). https://doi.org/10.1038/s41598-026-38716-z
关键词: 风湿病学, 波斯语医学教育, 大型语言模型, 临床推理, 资格考试