Clear Sky Science · zh
基于熵引导的多层特征融合网络用于高精度基于内容的图像检索
快速找到合适的图像
我们每天都会生成并存储大量照片——从医学扫描和卫星影像到监控录像和个人快照不等。人工标注和检索这些图片既慢又不可靠。本文提出了一种更智能的方法,让计算机直接“看”图像并以高精度找到我们需要的图像,即使在规模巨大、类型多样的集合中也能如此。
仅看像素还不够
传统的图像检索常依赖文件名或诸如“猫”“建筑”之类的简单标签。但人们并不总是认真标注图像,而计算机只能看到原始像素,无法感知人类推断出的丰富含义。早期的基于内容的系统尝试使用颜色、纹理和形状等简单视觉线索来弥合这一差距。这些线索确实有帮助,但通常以固定的重要性级别进行组合。这意味着系统把某些特征始终视为比其他特征更重要,即便在特定检索中不同的特征组合可能更有利。结果是在图像类型、光照或场景发生变化时,准确性会下降。
融合多种视角
作者提出了一个新的检索框架,融合了两类主要视觉证据。首先,采用深度学习模型——如 ResNet50 和 VGG16 等知名网络,这些网络已学会识别图像中的复杂模式。其次,加入经典的“手工”描述符,以更可控的方式捕捉颜色分布、边缘和纹理。系统不再事先猜测每种特征应有多重要,而是让数据来决定。它衡量每个特征对给定检索的 信息量,并动态调整它们的影响。这种高层和低层线索的多层融合,帮助计算机形成对图像更丰富、更灵活的理解。
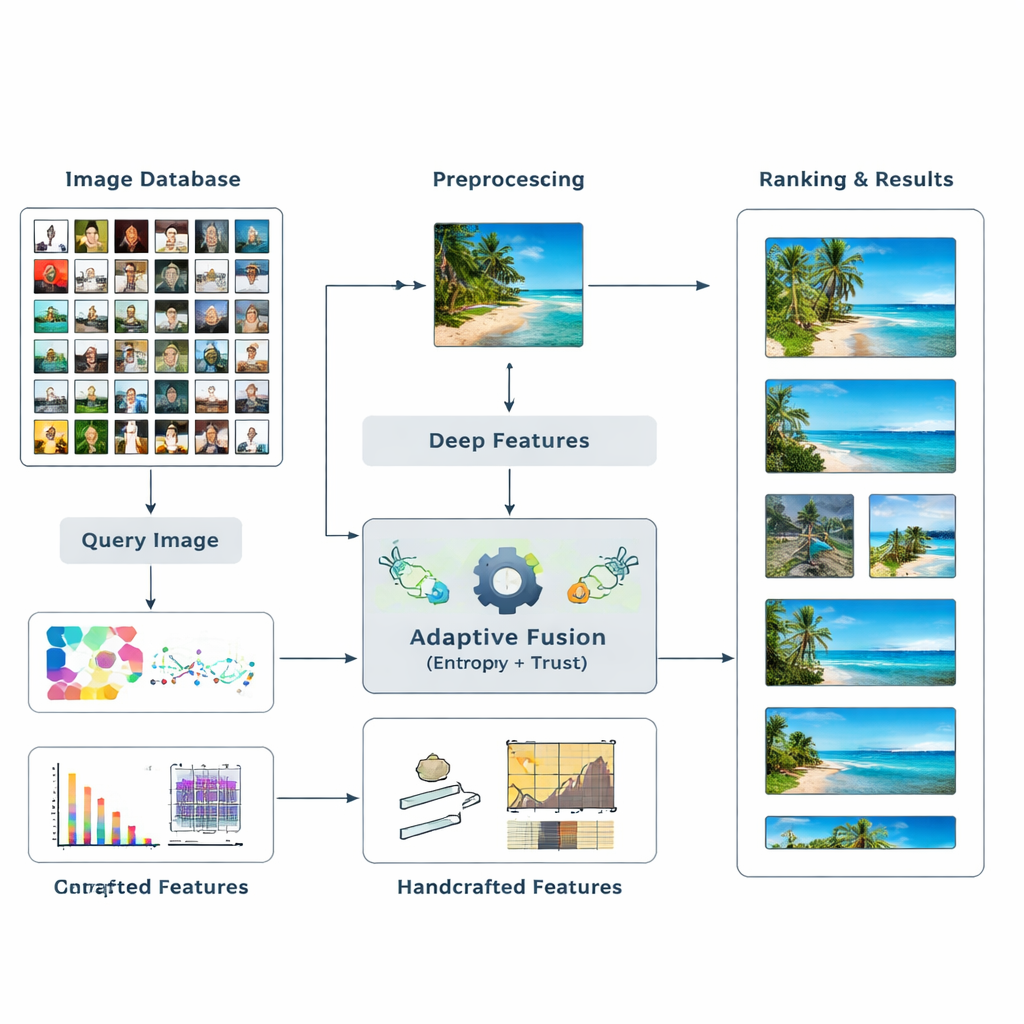
让信息量与可信度决定权重
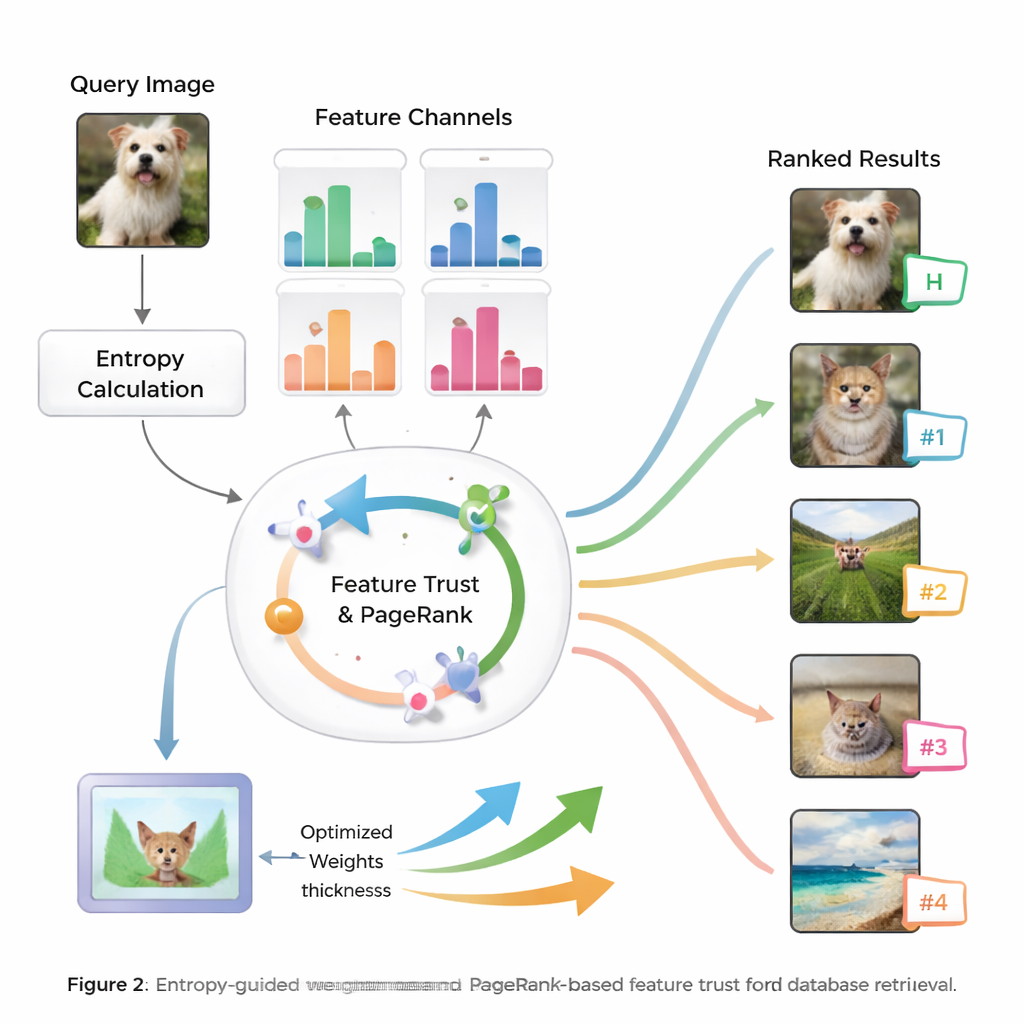
该方法的核心思想是熵,即衡量信息不确定性或分布广度的量度。那些能持续区分相关与不相关图像的特征具有较低的熵,因此被视为更具“判别性”。针对一个新查询,系统评估每个特征在数据库中的表现并分配初始重要性分数。接着评估每种特征检索结果的可靠性——例如顶端匹配项是否真正与查询相似——从而为每类线索建立一种“信任”度。将这些信任分数输入类似 PageRank 的过程(类似早期网络搜索引擎决定网页重要性的方式),通过概率传递网络细化特征权重。
从智能权重到更优排序
一旦系统学会了对当前查询应信任各个特征多少,就将它们的相似度分数合成为对数据库中每张图像的总体度量。然后按该综合分对图像进行排序,使在最有意义方面与查询匹配的图像浮到最上面。作者在广泛使用的图像基准上测试了他们的方法,并与若干现有方法进行了比较。他们报告平均精度(mAP)最高提升可达 8.6%,且前十结果在准确性和排序相关性上都有显著改善。统计检验表明这些改进不太可能是偶然的,表明该系统在多种图像类型上既准确又稳定。
这对日常图像检索意味着什么
简而言之,这项研究展示了如何构建能根据每个查询自我适应的图像搜索引擎,而不是依赖僵化规则。通过让信息含量和获得的信任度决定哪些视觉线索最重要,系统在更多情况下能更频繁地找到合适的图像——无论是在庞大的刑事数据库中识别指纹、在卫星照片中定位特定建筑,还是检索正确的医学影像。作者也承认该方法在计算上比简单系统更重,但他们认为其更高的可靠性和准确性使其非常适合用于需要极高正确率的大型关键图像库。
引用: Lavanya, M., Vennira Selvi, G., Gopi, R. et al. Entropy guided multi level feature fusion network for high precision content based image retrieval. Sci Rep 16, 7449 (2026). https://doi.org/10.1038/s41598-026-38699-x
关键词: 基于内容的图像检索, 深度学习, 特征融合, 图像搜索, 熵加权