Clear Sky Science · zh
在染色体图像分类中使用 ImageNet 预训练与两步迁移学习
更清晰地观察我们的染色体
我们的染色体承载着构建与维持身体所需的指令,医生通过研究它们的形态来发现遗传疾病和某些癌症。如今,计算机可以辅助解读染色体图像,但要将它们训练得很可靠很困难,因为医学影像稀缺且与日常照片差异很大。本研究提出了一个简单却具有重大实际意义的问题:计算机能否不只是从大量的猫、狗和汽车照片中学习,而是从相关的医学影像中学得更好?
染色体图像为何重要
在医院里,专家会把一个人的46条染色体排列成一张称为核型的图表,分成24类(22对常染色体加上X和Y)。沿着每条染色体的细微深浅带纹能揭示缺失或多余的片段,这些片段与唐氏综合征或某些白血病等病症相关。传统上,专家通过肉眼对这些带纹进行分类,既费时又主观。深度学习提供了自动化的可能,但这些系统通常从在 ImageNet 上训练的模型开始。这个跨越——从假期快照到显微镜下的染色体视图——差异极大,目前尚不清楚这种经验究竟能有多好地迁移。
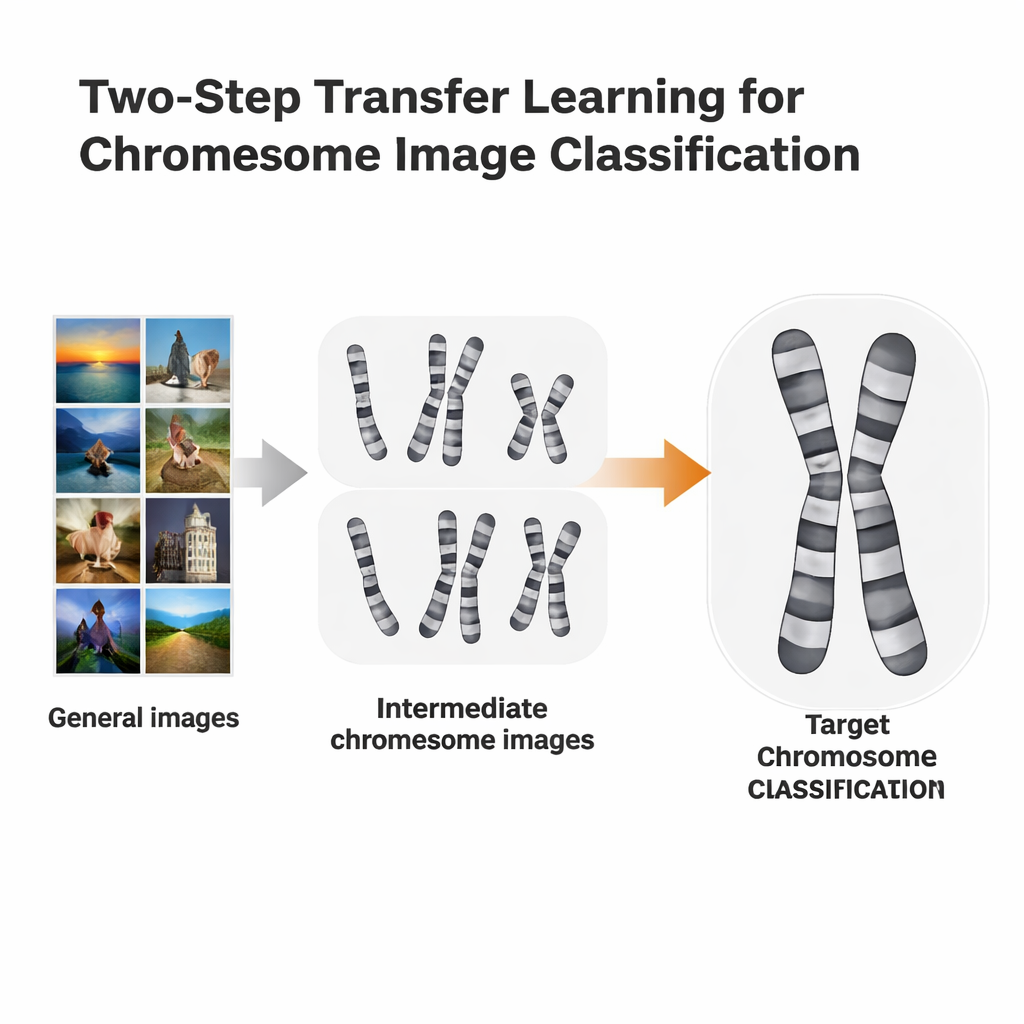
两步学习的快捷方式
研究人员测试了一种更有针对性的训练路径,称为两步迁移学习。与其直接从 ImageNet 跳到具体的染色体任务,不如先将 ImageNet 预训练模型在一种染色方法的染色体图像上微调,然后再在第二种略有不同的方法上再次微调。他们使用了两个公开数据集:Q 带图像(质量较低且更难辨认)和 G 带图像(更清晰、细节更多)。每个数据集轮流充当另一个数据集的“垫脚石”。这个思路类似于语言学习:如果你已经会西班牙语,学习意大利语可能比从英语直接上手容易。
测试多种计算“视觉”
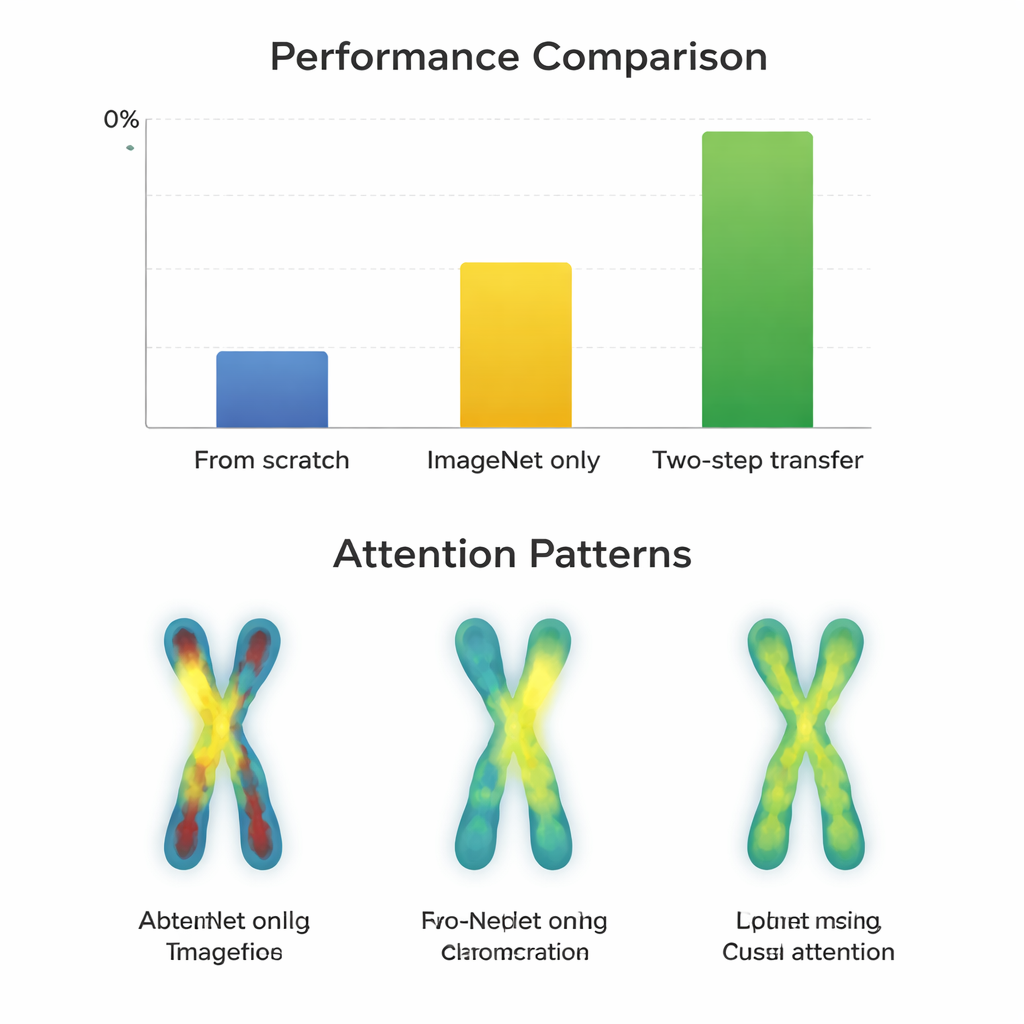
为了了解何时这一额外步骤有益,团队训练了66个不同的分类器,结合了11种流行神经网络架构和三种策略:从头训练、仅从 ImageNet 微调、以及使用两步迁移。他们用 Macro-F1 来衡量性能,这个分数对所有染色体类型一视同仁,包括那些罕见类型。首先,研究确认 Q 带与 G 带图像在统计上彼此更相似,而两者都比 ImageNet 照片更相近,这使它们成为有前景的中间垫脚石。随后,研究比较了不同模型在这三种策略下于容易(G 带)与困难(Q 带)数据集上的学习表现。
何时额外步骤有回报
在质量更高的 G 带图像上,几乎所有模型在简单的 ImageNet 微调后就已表现非常好,分数大约在97–98%。在这种情况下,额外的两步训练只带来微小提升——通常不足一个百分点——有时还会对较旧的网络架构产生负面影响。相反,在更具挑战性的 Q 带图像上,情况有所不同。现代的紧凑型架构,如 ConvNeXt、Swin Transformer、Vision Transformer 和 MobileNetV3,明显受益于两步路径,相较仅用 ImageNet 增益约在0.8到3.3个百分点之间。模型的注意力可视化图也说明了原因:采用两步迁移后,网络在染色体两臂的带纹上更均衡地聚焦,而不是仅关注轮廓或单一区域。然而,非常大且较老的网络(例如 VGG)并未获益,有时反而变差,这表明更聪明的设计胜过纯粹的规模。
数据本身设定的限制
研究人员还检查了 G 带图像上的错误。有些失败并非源自学习策略,而是因输入存在问题,例如在分离重叠形状时染色体被错误裁剪。在这些情况下,所有训练方法都难以应对,注意力图要么分散要么固定在误导性的边缘上。这强调了对临床与开发者的一个现实讯息:即便是最好的训练流程也无法完全弥补图像质量差或预处理错误的影响,尤其是在像染色体成像这种数据量有限的情形下。
对真实世界诊断的意义
对非专业人士来说,关键结论是:明智地重用相关的医学图像可以提升自动化染色体解读的准确性——尤其是在目标数据嘈杂或稀缺、且使用现代且设计精良的神经网络时。对于高质量图像,基于 ImageNet 的标准训练可能已足够。但当病理学家面对更困难的数据集时,利用密切相关类型图像的额外学习步骤可让计算机的“视觉”更敏锐,将性能提升到约93–98%的范围。这一方法或可超越染色体领域,推广到许多标注数据有限的医学影像领域,帮助把可靠的 AI 工具更快地带入日常临床实践。
引用: Chen, T., Xie, C., Zhang, W. et al. ImageNet pre-training and two-step transfer learning in chromosome image classification. Sci Rep 16, 7572 (2026). https://doi.org/10.1038/s41598-026-38662-w
关键词: 染色体分类, 医学影像人工智能, 迁移学习, 深度学习模型, 核型分析