Clear Sky Science · zh
FedSCOPE:一种具有解耦对比学习和隐私保护语义增强的联邦跨域序列推荐方法
为什么更智能、更安全的推荐很重要
每当你浏览电影、在网上购物或阅读评价时,推荐系统都在悄然决定接下来向你展示什么。随着我们的数字生活横跨多个应用和网站,如果这些系统能够同时从所有活动中学习——且绝不暴露你的私人数据——它们本可以做得更好。本文提出了 FedSCOPE,一种让不同平台在不侵犯隐私的前提下协作提供更准确推荐的新方法。
当今推荐引擎的问题
目前大多数推荐系统仅存在于单一应用或网站中,只能看到你行为的狭窄片段。因此它们在面对“冷启动”用户(历史很少)或与少数人互动的小众商品时表现不佳。当公司尝试将来自不同领域的数据合并——比如书籍与电影、食品与厨房用品——会遇到三大挑战:数据通常稀疏、不同平台的用户和行为类型差异很大、严格的隐私法规使得将原始数据集中存储风险高。简单的修补办法,比如对所有人施加相同程度的隐私噪声,往往要么削弱保护,要么严重损害准确性。
让语言模型填补空白
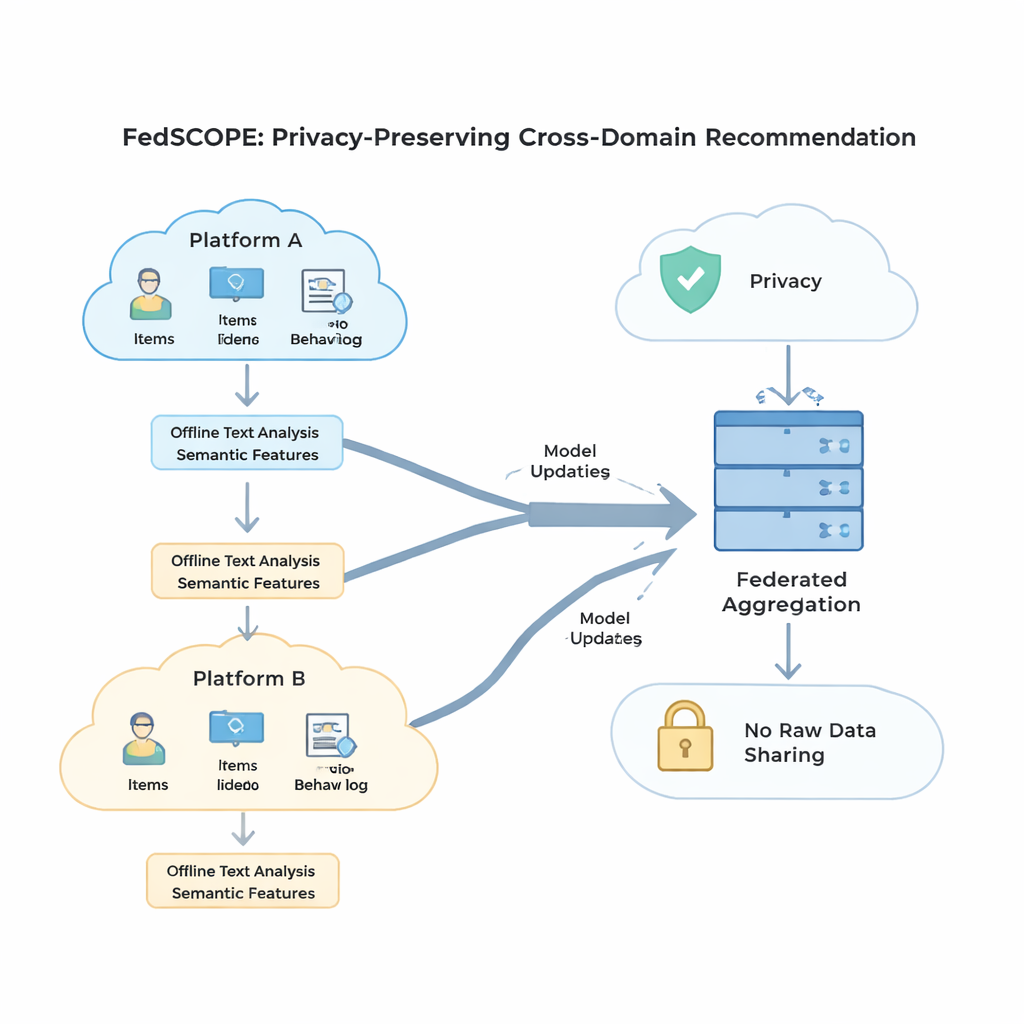
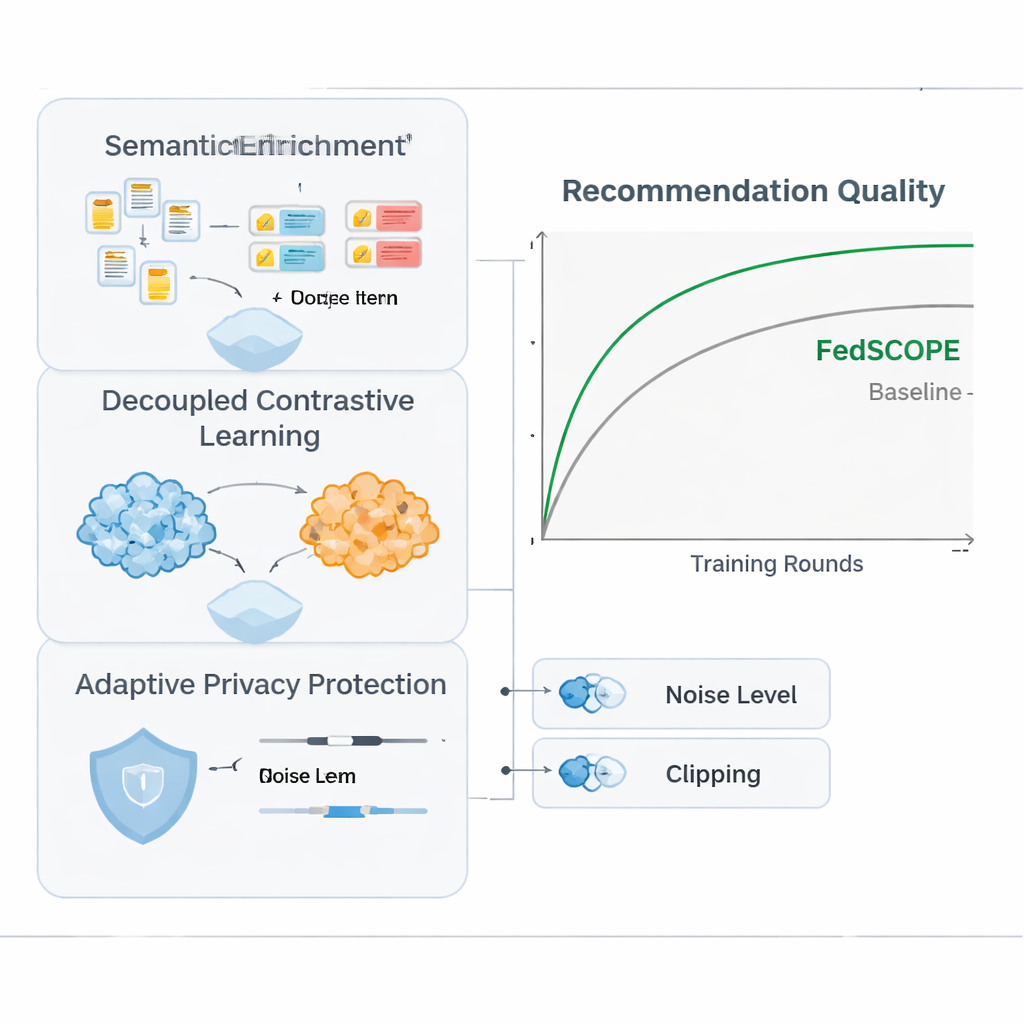
FedSCOPE 通过让每个平台使用大型语言模型(LLM)丰富其数据来解决稀疏问题,但方式与众不同且注重隐私。每个客户端不会在每次推荐时将用户历史发送到远程 AI 服务,而是在本地执行一次离线过程:将标题和基本条目信息(例如电影名称和类型)输入 LLM,要求生成结构化描述,如可能的主题、观看习惯或相关兴趣。这些生成的属性保留在本地设备或服务器上,并通过轻量神经网络与常规的点击和观看历史融合。这样系统对用户和物品有了更丰富的刻画,尤其在交互记录稀少时非常有用。由于该过程是离线且本地进行,原始行为数据不会离开平台,也无需持续依赖外部 AI 服务。
把个人信息和共享信息分离
为了在不混淆信息的前提下利用来自多个领域的行为数据,FedSCOPE 提出了一种名为解耦对比学习的训练策略。简单来说,系统同时学习两类内容。首先,在每个域内——例如仅电影领域——将行为相似的用户拉近,将不相似的用户推远,从而增强该环境下对个人喜好的识别。其次,在跨域层面上,将同一用户在不同域的表示对齐,同时保持不同用户互不混淆,让你看过的内容能帮助预测你可能阅读或购买的东西,而不会把你与他人合并。通过分别处理“域内”和“跨域”目标,该方法避免了将所有内容强行统一到单一共享表示中而破坏细粒度偏好的常见问题。
在不牺牲有用性的前提下保护隐私
强数学意义上的隐私(即差分隐私)通常意味着在将模型更新共享到中央服务器之前加入随机噪声。许多早期系统对所有参与方使用相同的隐私设置,但当一些客户端拥有数百万用户而另一些只有几千时,这种做法并不合适。FedSCOPE 为每个客户端提供个性化的隐私预算,并根据其数据量和历史行为调整更新的裁剪与扰动程度。数据量大、信息丰富的平台可以在不过度加噪的情况下贡献更精确的信息,而规模较小的平台则得到更强的保护。所有更新随后通过安全聚合合并,因此服务器永远不会以明文看到任何单一贡献。
实验在实践中的结果
作者在来自亚马逊的真实购物数据上测试了 FedSCOPE,配对领域例如电影与图书、食品与厨房用品。他们将其与一系列现代推荐方法比较,包括其他隐私保护和跨域方法。在多个准确性度量上,FedSCOPE 始终名列前茅或接近顶端。它在训练时收敛更快,对历史交互很少的用户表现更好,并且在参与客户端数量或每轮抽样比例变化时依然稳健。重要的是,当团队收紧隐私约束时,FedSCOPE 的自适应策略比使用一刀切差分隐私的系统保持了更高的性能。
这对普通用户意味着什么
从普通用户角度看,FedSCOPE 指向一种未来:你喜欢的应用可以在不汇聚你的原始数据的前提下协作更深入地理解你的喜好。通过用语言模型的洞见丰富稀疏历史、谨慎区分域内与共享信息,并为每个参与方调优隐私控制,该框架能提供既更相关又更尊重个人信息的推荐。在实际层面,这可能意味着更好的观影、阅读或购物建议——而不用以牺牲数字隐私为代价。
引用: Zhao, L., Lin, Y., Qin, S. et al. FedSCOPE: Federated cross-domain sequential recommendation with decoupled contrastive learning and privacy-preserving semantic enhancement. Sci Rep 16, 7420 (2026). https://doi.org/10.1038/s41598-026-38628-y
关键词: 联邦推荐, 隐私保护人工智能, 跨域个性化, 大型语言模型, 差分隐私