Clear Sky Science · zh
通过多模态大语言模型探索师生互动:一项实证研究
为什么用人工智能观察课堂很重要
凡是在课堂上待过的人都知道,教师与学生之间的互动能决定课堂是枯燥无味还是有效学习。然而,要研究这些瞬息万变的交流却出乎意料地困难:观察者会疲劳、人类判断存在分歧,视频资料也很快变得难以处理。本文探讨了一种新型人工智能——能够“看”图像和“读”文本的多模态大语言模型,如何帮助研究者和学校更快、更客观地理解复杂的课堂生活。
把真实课堂变成研究数据
研究者从中国中小学的普通课堂视频入手,这些视频来自一个国家教育平台并可公开获取。他们从30节课中提取了近2400张捕捉教学与学习关键瞬间的静态图像。每张图像都按五种易于理解的互动模式进行标注:引导型(教师讲解)、协作型(学生合作)、提问型(问答互动)、独立型(学生独立完成)和展示型(学生向全班展示)。教育技术方面的专家参与了这些类别的精细化,使之与经验观察者在真实课堂中关注的要点相匹配。
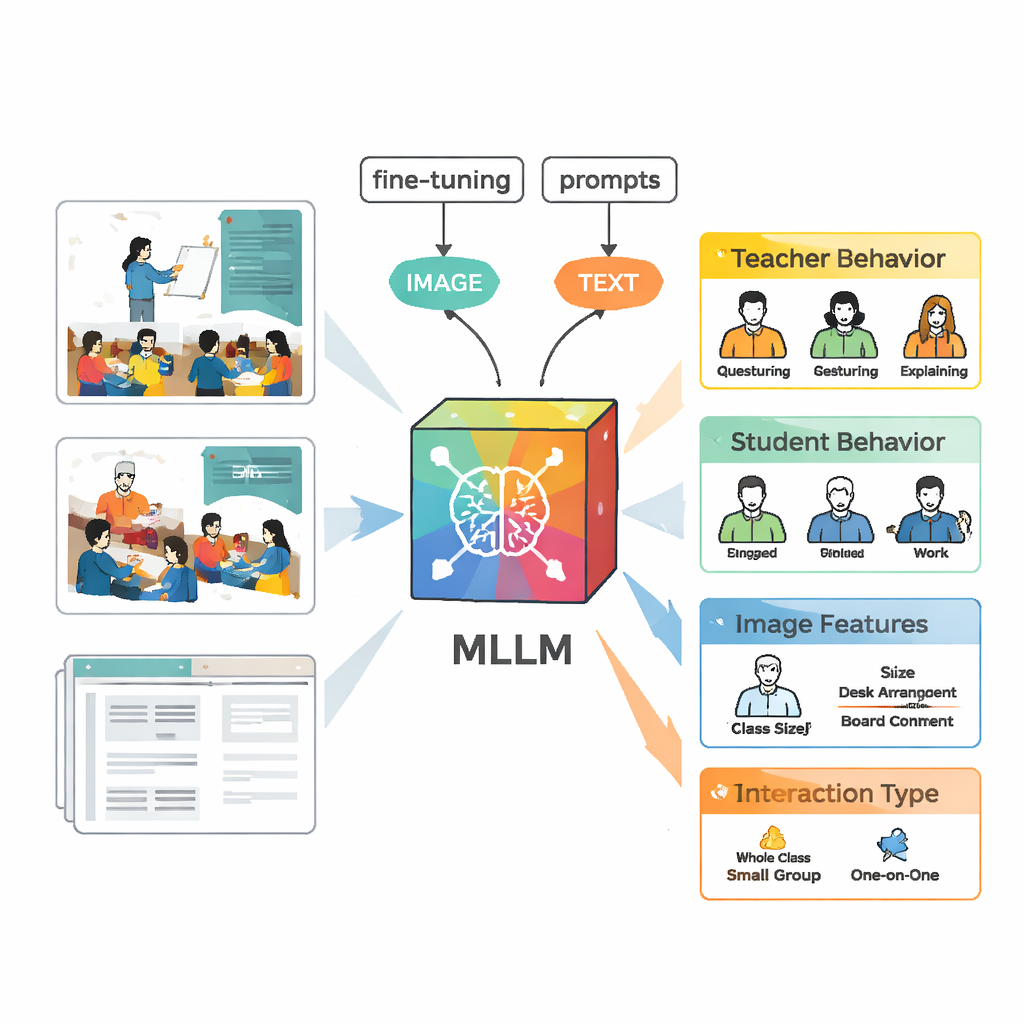
教AI识别课堂动态
为分析这些场景,团队使用了一种名为 VisualGLM‑6B 的多模态大语言模型,该模型可以同时接受图像和文本作为输入。由于原始模型是广泛训练的,并非专门针对课堂场景,研究者使用带标签的图像对其进行了“微调”。他们采用了一种称为 LoRA 的技术,只调整模型内部少量参数,使训练更高效但仍保留强大能力。他们还设计了严谨的提示词——结构化指令,要求模型以一致的格式描述教师行为、学生行为、视觉特征和互动类型,以便将输出与人类专家判断进行更容易的比对。
人与机器共建更好的标注
创建高质量训练集不仅仅是把模型指向视频。首先,VisualGLM 会生成每张图像的基本描述。人工标注者随后纠正错误并补充缺失的情境信息,例如谁在发言、学生是在倾听还是在讨论。接着,他们将这些润色后的描述输入 ChatGPT,在定制提示的引导下,生成遵循五种互动类别的结构化分析。专家再次对 AI 生成的分析进行审阅和编辑。最终结果是一个丰富的数据集,每张图像都带有对师生行为的详尽且可信的记录。
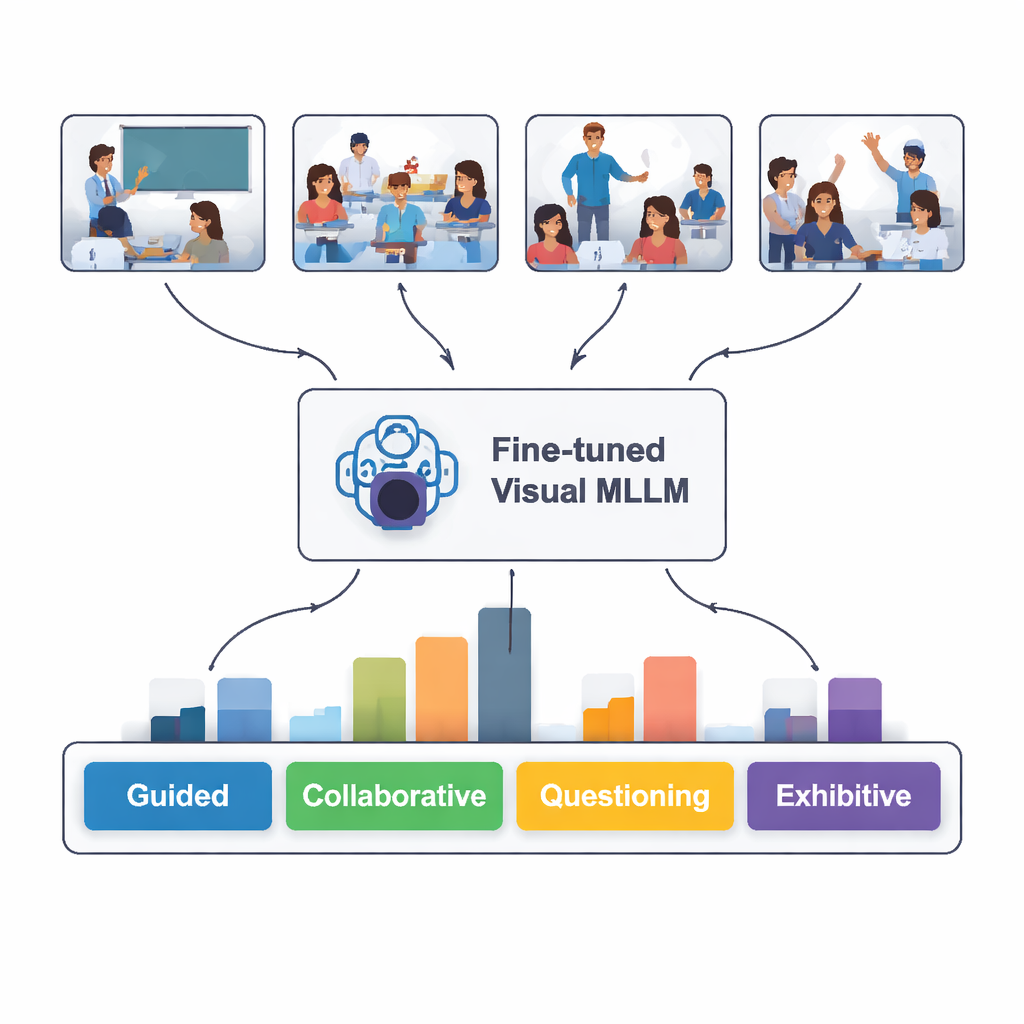
AI对课堂的“解读”表现如何?
在对100张模型未曾见过的新课堂图像进行测试时,微调后的模型在82%的情况下正确识别了互动类型。它在识别引导型、独立型和展示型情境时表现最好——例如教师在明确讲解、学生安静独立完成作业或学生在台前展示。它在识别协作型和提问型时难度较大,这类情境的肢体语言与座位安排即便对人也可能模糊不清。更深入的文本比对显示,模型的书面描述常常与专家分析高度一致,尽管有时会“幻觉”出图像中不存在的细节或误读微妙的姿态。
这对未来课堂意味着什么
对非专业读者来说,核心信息是:人工智能系统正变得能够观察课堂并总结教学与学习的展开方式,具有一种人类在数千个场景中难以维持的结构性与一致性。虽然并不完美——尤其是在识别细微的讨论与提问形式方面——但这种方法表明多模态大语言模型已能支持教育研究,并最终用于课堂反馈工具。随着这些模型开始纳入声音、手势以及更大、更具多样性的数据集,它们可能帮助教师看到以往被忽视的实践模式,为理解日常互动如何影响学生学习提供新的视角。
引用: Chen, G., Han, G., Niu, J. et al. Exploring teacher-student interaction through multimodal large language models: an empirical investigation. Sci Rep 16, 7602 (2026). https://doi.org/10.1038/s41598-026-38626-0
关键词: 师生互动, 课堂分析, 多模态人工智能, 教育技术, 大语言模型