Clear Sky Science · zh
利用自然语言处理和机器学习从初级保健电子病历中识别慢性疾病
为什么医生笔记比你想象的更重要
当你去看家庭医生时,每次咳嗽、每项抱怨和每个顾虑都会被记录进你的电子病历。许多细节以自由格式的文本形式存在,而不是整齐的复选框。本研究表明,这些叙述性笔记与现代计算技术结合后,可以帮助医生更准确地发现关节炎、肾病、糖尿病、高血压和呼吸系统问题等慢性疾病——尤其是在这些问题未在病历其他部分清楚编码时。
日常门诊记录中的隐秘线索
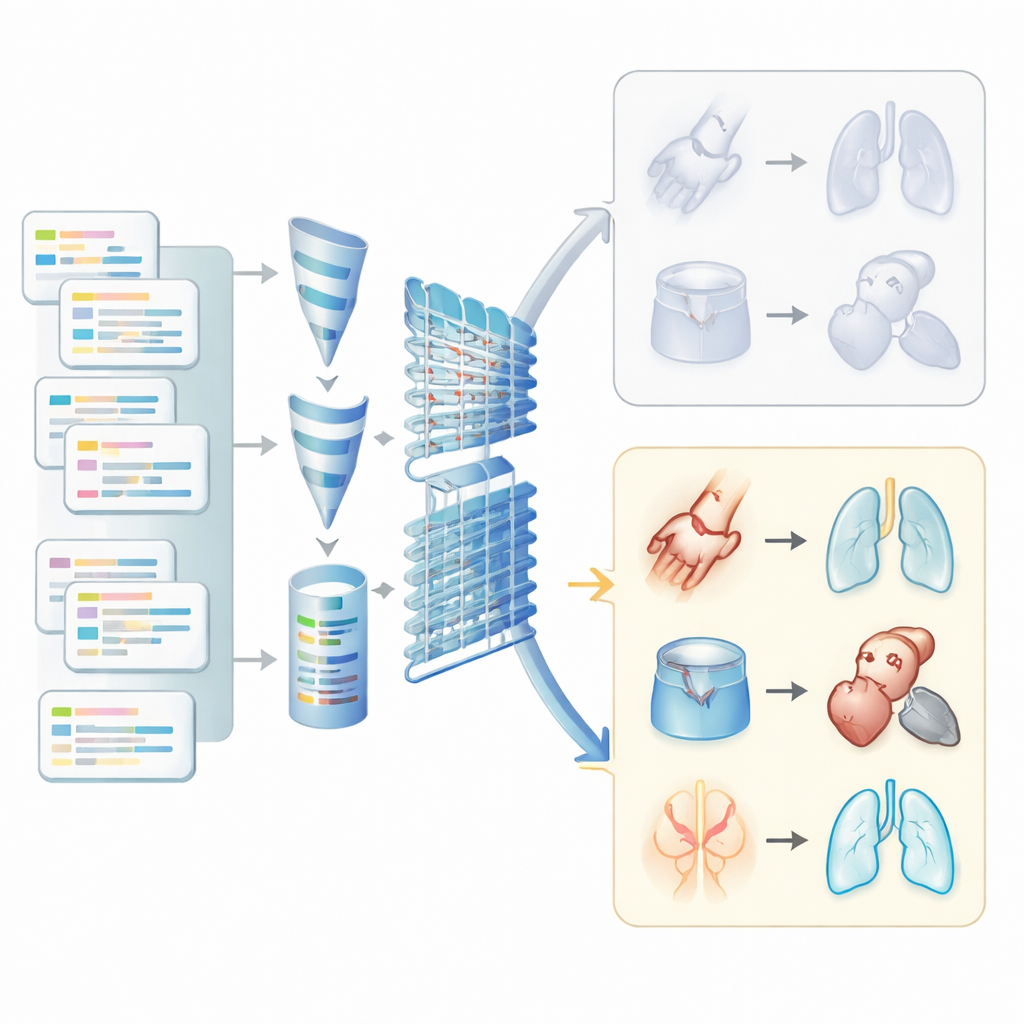
初级保健的电子病历包含两类截然不同的信息。一类是结构化项,例如计费代码、用药清单和化验结果;另一类是非结构化的笔记,临床医生在其中用通俗语言描述症状、病史和诊断推理。在加拿大,计费代码往往不完整,主要用于支付结算而非精确诊断,因此许多健康问题在笔记中比在复选框里表现得更清楚。研究人员着手检验,将这两类信息一起挖掘是否能更好地识别在阿尔伯塔一所家庭医学诊所就诊的60岁及以上患者中的五种常见长期病。

教会计算机“读”医生的语言
为了利用临床笔记中丰富但杂乱的文本,团队使用了自然语言处理这一帮助计算机处理人类语言的工具集。他们通过去除杂散符号、统一词形、扩展缩写并将相关词归并为共同词根来清洗文本。团队还构建了简单规则以识别笔记中表示患者不患某病的表达——例如“无证据表明”或“已被排除”之类的短语——从而避免将这些误判为阳性病例。团队中的临床医生为每种疾病制定了有意义的词汇和短语列表,帮助算法聚焦于相关医学概念,而不是每一个无关词。
发现主题并从模式中学习
接着,研究人员将文本量化,以便输入机器学习模型。他们统计了每个病人笔记中每个词或词对出现的频率,同时对非常常见的词进行降权,并突出那些对特定疾病特别有区分力的词。采用一种称为主题建模的方法,他们核对了笔记中最常见的词组是否与感兴趣的疾病相一致——例如与糖尿病或高血压相关的术语。这一步作为现实检验,确认计算机识别出的主题在建立预测模型之前与临床知识相符。
让算法标记可能患病的人
研究的核心是训练三类机器学习模型来判断每位患者是否可能患有五种慢性疾病中的每一种。一种模型像是精炼的风险计算器,另一种在健康与疾病病例之间画出边界,第三种类似于一个简单的类脑网络。研究人员先仅用记录的结构化部分训练这些模型,然后再用结构化数据与来自笔记的处理后文本特征共同训练。他们还针对样本中某些疾病较少见这一事实,谨慎地对数据进行重平衡,以免罕见疾病被算法忽视。
使用完整记录带来的明显提升
当加入非结构化笔记后,模型在区分有无疾病的人方面明显变得更好,尤其是对于那些在计费数据中常常缺乏编码的问题。对于关节炎和呼吸系统疾病,模型区分病人与非病人的能力以及识别真实病例的可靠性都有显著提升。例如,在包含笔记时,检测呼吸问题和关节炎的表现从一般提升到较强。糖尿病和高血压的提升较小,因为这些疾病已在结构化字段中较好地被捕获。有趣的是,较简单的模型经常表现得与或优于更复杂的神经网络,这表明对于此类诊所级工作,复杂的深度学习并非总是必要的。
这对你未来医疗意味着什么
总体而言,该研究表明关注病历中的叙述性部分——而不仅仅是代码和化验数值——可以显著提升我们发现慢性病患者的能力。通过将自由文本笔记转化为机器可读信号并与现有的结构化数据结合,卫生系统或能更早识别高危患者,将随访资源集中到最需要的地方,并将这种方法推广到其他主要存在于就诊文字记录而非下拉菜单中的疾病。
引用: Zhang, N., Abbasi, M., Khera, S. et al. Leveraging natural language processing and machine learning to identify chronic conditions from primary care electronic medical records. Sci Rep 16, 8441 (2026). https://doi.org/10.1038/s41598-026-38594-5
关键词: 电子病历, 慢性病检测, 自然语言处理, 医疗领域的机器学习, 初级保健数据