Clear Sky Science · zh
用于数据流的动态蚂蚱增强神经网络的智能增量分类
为何不断变化的数据很重要
从电网和工厂到在线支付,现代系统每秒都在产生数据。在这些持续的数据流中,隐藏着设备故障、网络攻击或即将到来的价格暴涨的早期预警。挑战在于这条信息之河永不停歇,其行为随时间不断变化。本文所述论文提出了一种新的训练神经网络的方法,使其能够在不降低速度或丧失准确性的情况下,持续从实时数据中学习,从而在现实世界的监测和决策中更有用。
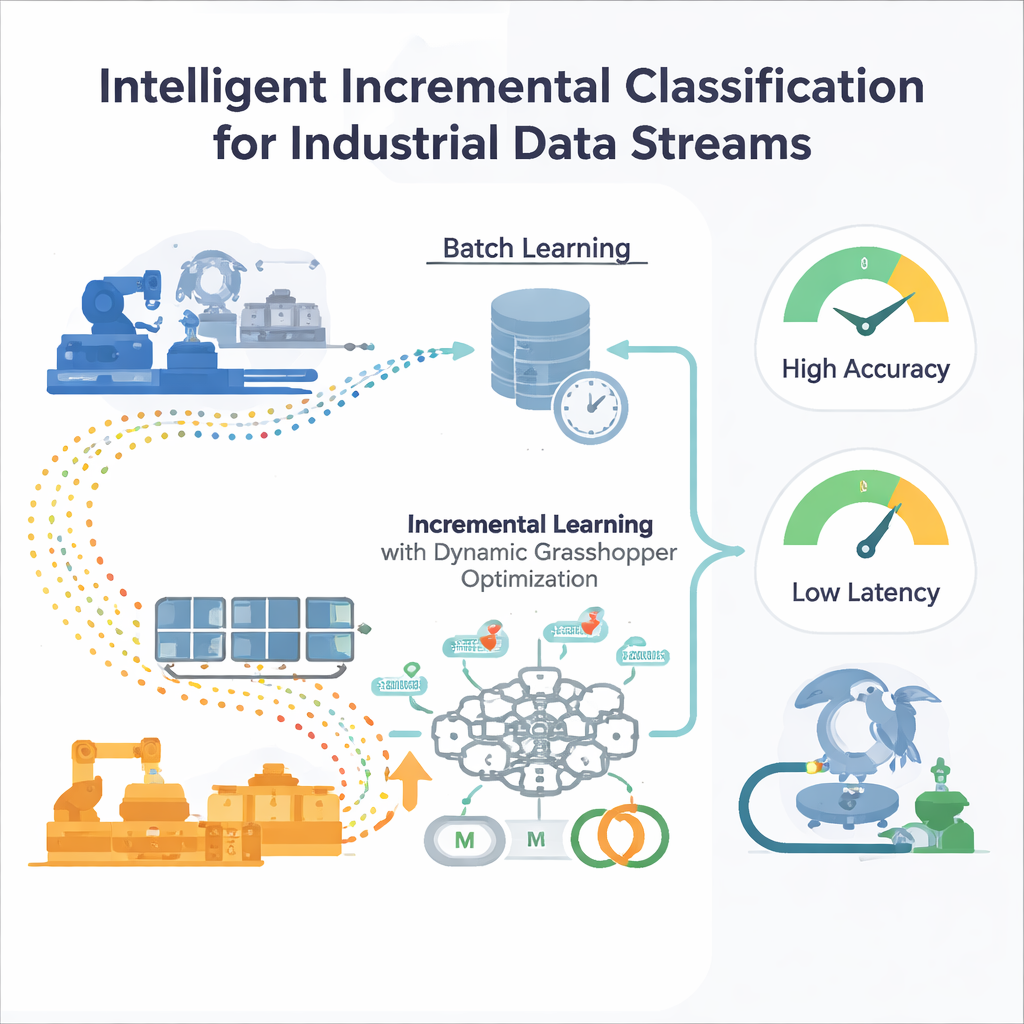
一次性训练的局限
大多数传统机器学习模型以“批量”方式训练:工程师收集大量历史数据,调优模型,然后部署。如果外部环境保持大致不变,这种方法可行。但在工业场景中,条件会漂移——需求模式变化、传感器老化、市场波动。一个静止不变的模型会逐渐对新模式失明,而在不断增长的数据集上从头重训既昂贵又耗时。像网格搜索或进化算法这样的标准自动调参方法也假定数据是固定的,这意味着每当数据分布发生变化就必须重启调参,这对全天候运行的系统来说不切实际。
能够在线学习的神经网络
作者提出了一个以多层感知器(MLP)为核心的增量学习框架,这是一种常见的神经网络。不是一次性把所有历史数据喂入网络,而是将进入的数据流分割成可管理的窗口。每个新窗口成为一次小规模的训练步骤,更新网络的内部权重后即被丢弃——一种“训练即忘记”的策略,能保持低内存占用。关键在于系统不依赖固定的训练设置。控制学习行为的两个关键旋钮——学习率(每次更新的步长)和动量(更新的平滑程度)——会随着数据流的演化持续调整,使模型在保持响应性的同时不至于变得不稳定。
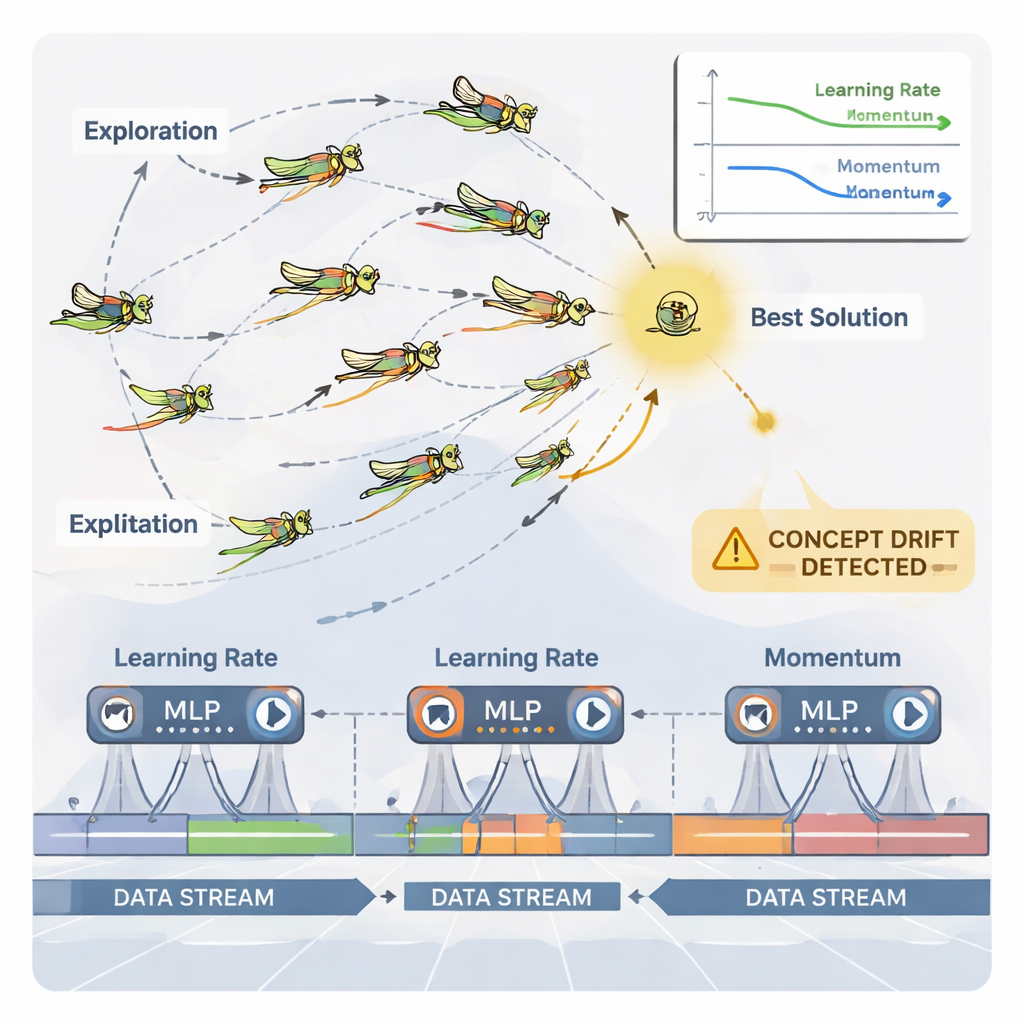
把蚂蚱当作智能参数调节器
为处理这种持续调整,论文采用了一种受自然启发的优化算法,称为动态蚂蚱优化算法(DGOA)。可以想象一群虚拟蚂蚱在探索学习率和动量的可能组合。早期它们广泛游走以搜索良好区域;随后收紧动作以微调有前景的选择。在这个动态变体中,它们的步长和对最佳解的吸引力会根据神经网络的表现随时间变化。系统还监测“概念漂移”——预测误差或数据本身的突变。当检测到漂移时,部分蚂蚱会被重置并临时增大步长,允许优化器迅速搜索新的区域并摆脱已过时的参数设置。
方法的实测
研究人员在澳大利亚的真实电力市场数据集上评估了他们的方法,目标是预测价格是会上涨还是下跌。与常见的调参方法(如网格搜索、随机搜索、粒子群优化、遗传算法、蚁群优化以及标准蚂蚱算法)相比,动态版本与增量学习相结合,在保持较低计算时间和较少迭代次数的同时取得了最高的准确率(约89.5%)。额外实验显示,该方法能更好地适应稳定和变化的数据流,在成千上万到数十亿样本的规模下保持内存可控,并且在预测性维护、异常检测、欺诈检测等任务以及标准数学优化基准上表现具有竞争力。
实际意义
对非专业读者来说,结论是:这项工作提供了一种在数据不断产生且环境持续变化的场景中,保持神经网络“活着”且调优良好的方式。与其反复停止系统从头重建模型,该框架允许轻量网络以窗口为单位自我更新,同时基于群体的优化器持续调整其学习速度和更新平滑度。结果是对新模式更快的适应、更好的长期准确性以及更高效的计算资源利用——这些都是能源、制造和金融等领域实现可靠实时决策的关键要素。
引用: Darwish, S.M., El-Shoafy, N.A. Intelligent incremental classification using a dynamic grasshopper-enhanced neural network for data streams. Sci Rep 16, 7730 (2026). https://doi.org/10.1038/s41598-026-38571-y
关键词: 数据流, 增量学习, 神经网络, 超参数优化, 群体智能