Clear Sky Science · zh
SAT:无需光流估计的用于视频去噪的移位对齐变换器
从嘈杂场景中恢复更清晰的视频
任何在室内或光线有限的手机上尝试过拍摄夜间视频的人都知道结果:颗粒感强、闪烁明显,细节似乎在爬动,颜色失真。这篇论文提出了一种清理此类视频的新方法,将它们转换为更清晰、更稳定的序列,而无需依赖通常实现此目的的繁重运动跟踪软件。该方法称为移位对齐变换器(Shift Alignment Transformer,SAT),旨在在保持细节的同时仍具有足够的效率以便实用。
为什么视频去噪如此困难
对单幅照片去噪本身就是一项挑战;对视频做同样的事更难。一方面,每一帧都被随机的斑点和色彩偏移所污染。另一方面,帧之间在时间上是相关联的:物体在移动、摄像机抖动,细节会出现或消失。传统的视频去噪方法常依赖估计帧间运动,通常通过一种称为光流的工具来跟踪每个像素从一帧到下一帧的移动。尽管光流很强大,但在视频非常嘈杂或运动快速复杂时,这些运动估计很容易失效,而且它们还会增加大量计算负担,可能使系统变得非常缓慢。
无需跟踪的新型对齐方式
移位对齐变换器(SAT)并不试图显式地跟踪每个像素,而是采用不同路径:通过谨慎地移位和比较特征,让网络隐式发现帧间关系。该模型基于一种擅长发现长程关联的现代架构——变换器(Transformer)。在此框架内,作者引入了时空移位模块(Spatial-Temporal Shift Module),它在时间和空间上温和地重排信息。在时间维度上,模型周期性地移位帧特征,使得层与层之间每帧能够“看到”更远的过去和未来。在空间维度上,它将特征拆分为许多小组,并将每组向不同方向轻推。该组合有效地模拟了物体在视频中可能的移动,使网络在不计算显式运动场的情况下对齐来自不同帧的信息。
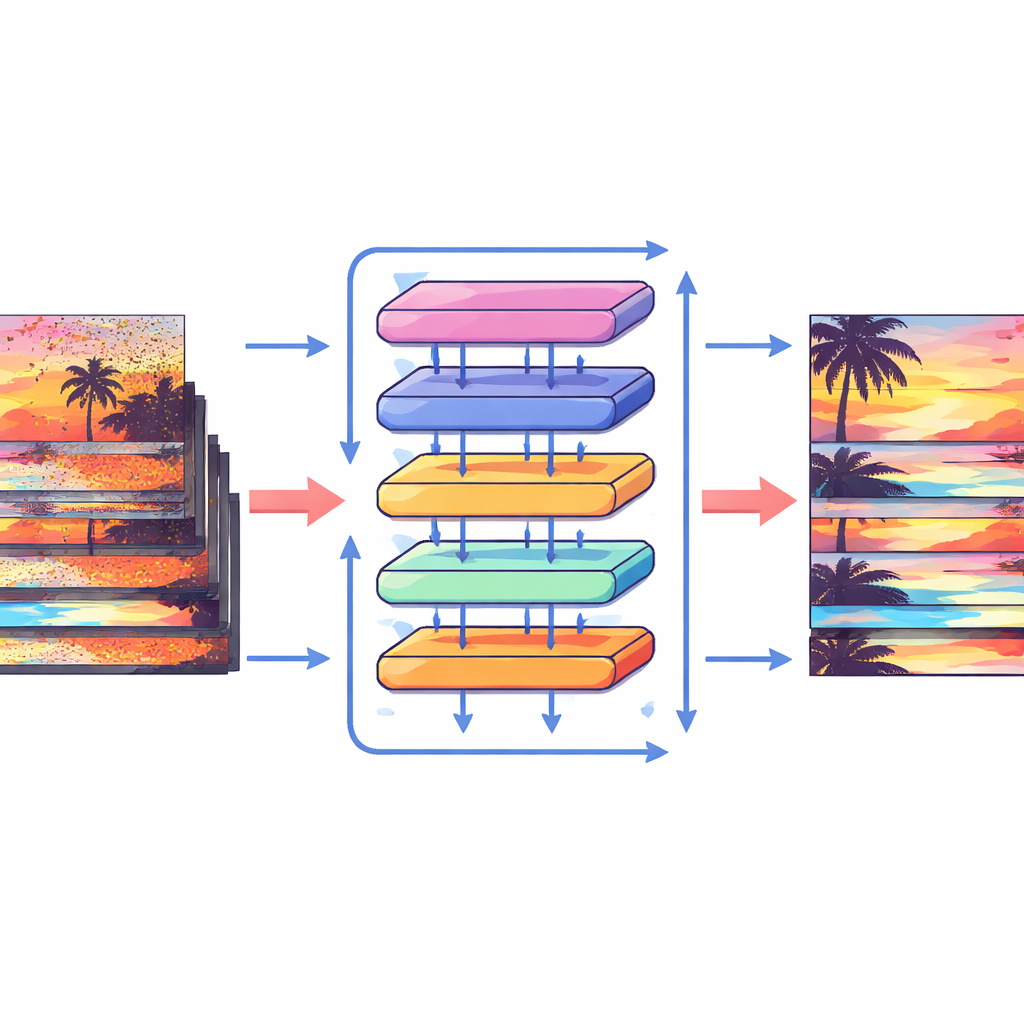
这些新构件如何工作
为充分利用这些移位,作者设计了一个特殊的注意力块来混合帧内和帧间的信息。首先,将来自相邻帧的移位特征聚合并通过交叉注意力操作进行比较:模型学习在每个位置上其他帧中哪些区域最能支撑当前帧。与此同时,一个独立的注意力操作关注每一帧内部的关系,强化局部结构和纹理。这两条信息流随后被合并并通过简单的处理层输入到多尺度的U形网络中,该网络从粗到细再回到粗的分辨率变化。这样的布局使系统既能处理较大的相机运动,又能恢复细小细节,如细边缘或微小图案,逐步重建每一帧的清晰版本。
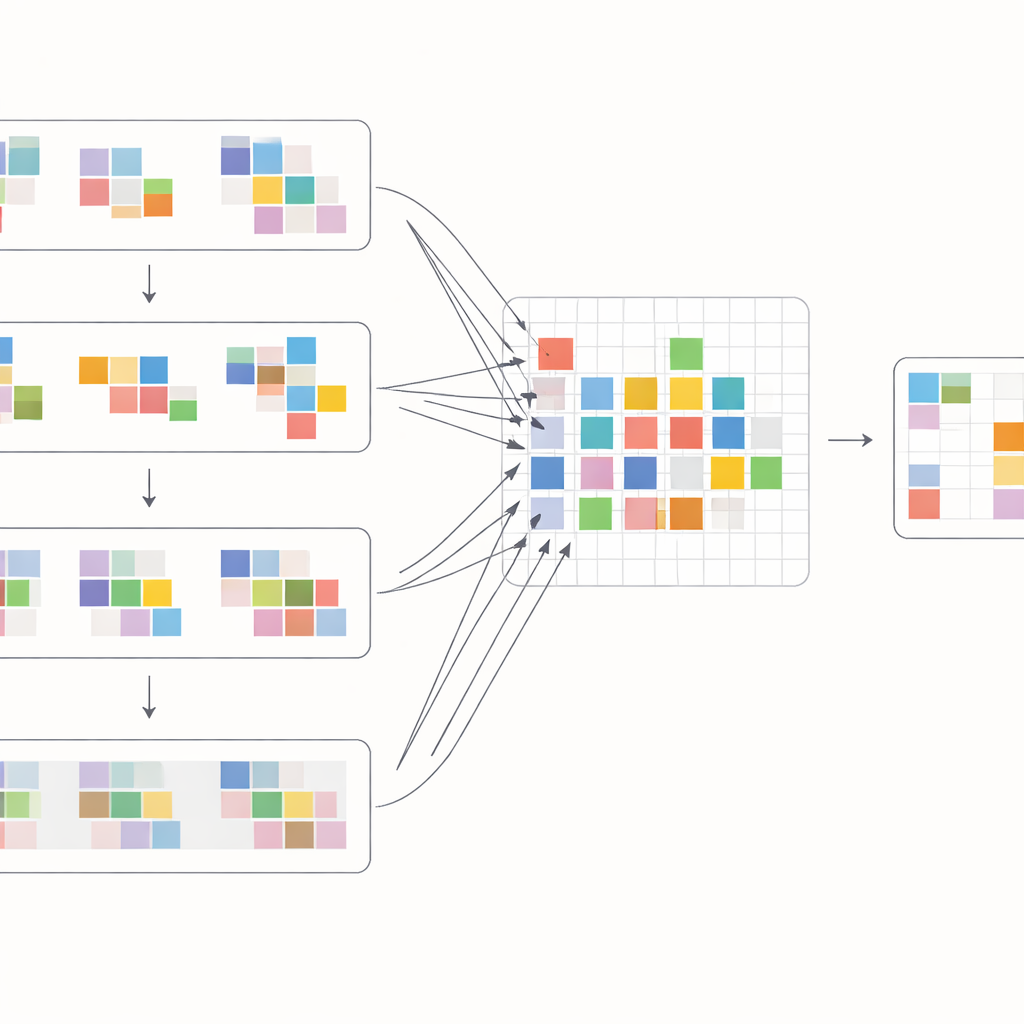
实际效果如何
研究者在两个具有挑战性的基准上测试了他们的方法。第一个基准使用干净视频并人工加入不同级别的随机噪声,以便精确测量恢复帧与原始帧的匹配程度。在这里,该新方法持续匹配或超越早期卷积和递归网络的质量,并在使用更少计算量的情况下接近现有基于变换器的最佳模型。第二个基准使用在弱光下由图像传感器拍摄的真实镜头,其中噪声不均匀、有色且远不那么可预测。在这一更现实的测试中,移位对齐变换器明确优于此前的先进方法,生成的视频在时间上更干净、更锐利、更稳定,色彩漂移和残留伪影更少。
这对未来视频工具意味着什么
简而言之,作者展示了无需显式跟踪运动,通过在时间和空间上巧妙移位并结合基于注意力的特征匹配,也能有效地对视频进行去噪。他们的移位对齐变换器在准确性与效率之间提供了良好平衡,尤其适用于传统运动估计脆弱的真实弱光视频。随着基于注意力的模型变得更加高效,此类方法可能会进入日常相机和流媒体服务,帮助将嘈杂、难以观看的片段转变为平滑、清晰的视频,且对用户几乎无额外麻烦。
引用: Zhang, X., Fan, S., Zhang, H. et al. SAT: shift alignment transformer for video denoising without flow estimation. Sci Rep 16, 8207 (2026). https://doi.org/10.1038/s41598-026-38431-9
关键词: 视频去噪, 变换器, 图像噪声, 弱光视频, 计算机视觉