Clear Sky Science · zh
MDI‑YOLO:一种基于Transformer‑CNN的轻量级多维特征融合小目标检测模型
更敏锐的空中“眼睛”
从交通监控到灾害响应,无人机和卫星越来越多地监视我们的世界。然而,在这些图像中我们最关心的事物——微小的汽车、行人、船只和飞机——常常只占据极少的像素。关于MDI‑YOLO的论文解决了一个简单但关键的问题:如何让计算机即使在无人机携带的低功耗设备上,也能实时、可靠地检测这些微小目标?
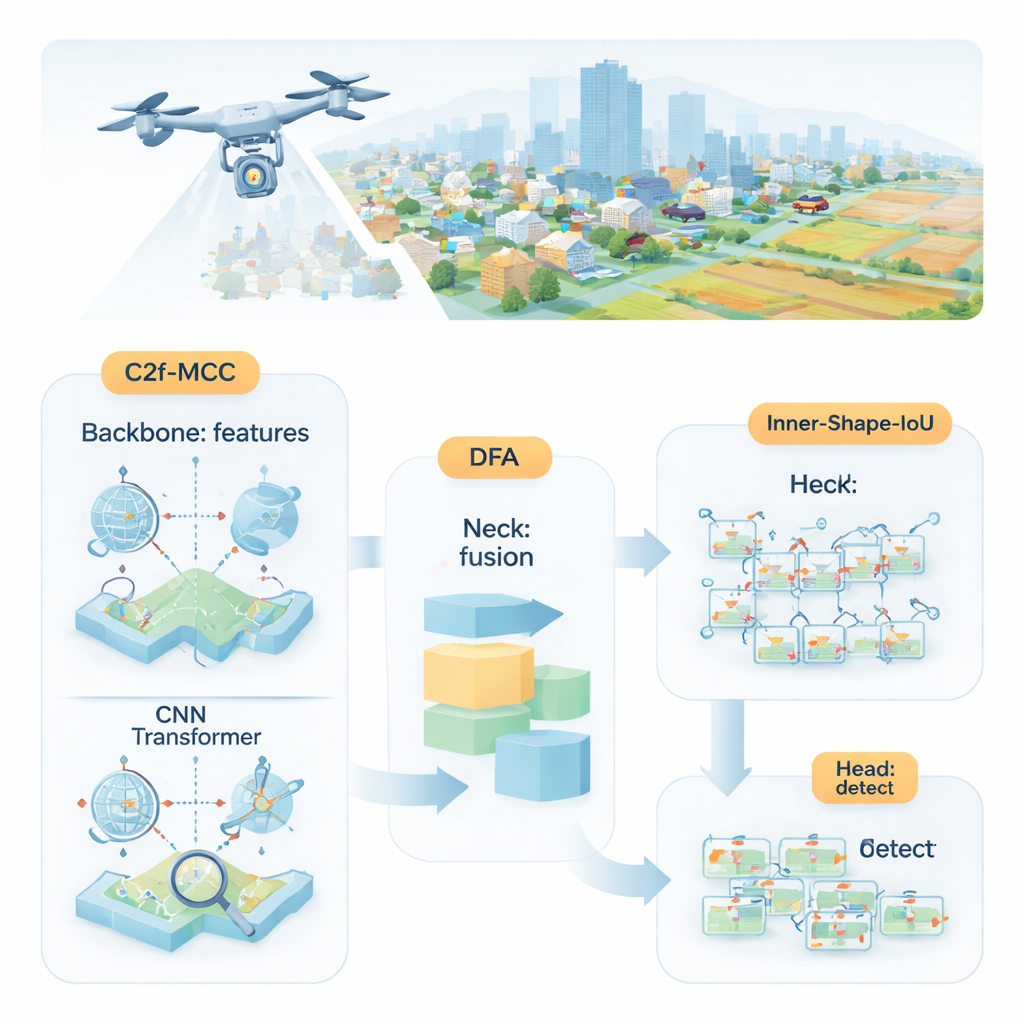
小目标为何难以检测
在航拍和卫星视野中,目标通常非常小,经常相互拥挤,并可能被建筑、树木或阴影部分遮挡。标准检测系统面临权衡:轻量模型可在无人机等边缘设备上快速运行,但容易漏检许多小目标;更重、更准确的模型速度太慢、资源消耗太高,难以在实地实用。小目标也容易融入复杂背景——想象灰色车与灰色路面——因此其特征在图像压缩和深度网络处理过程中很容易消失。
全局与局部视觉的新结合
研究者提出了MDI‑YOLO,这是对流行的YOLOv8检测器的重新设计,旨在保持模型紧凑同时提升发现微小目标的能力。其核心是一个名为C2f‑MCC的新模块,它将网络中流动的视觉信息拆分为两条路径。一条路径采用类Transformer的处理,擅长捕捉跨整个图像的长期依赖关系——例如一簇像素如何融入更大的道路或跑道中。另一条路径保留经典的卷积滤波,擅长提取边缘和纹理等局部细节。通过对通道进行分组并仅将部分数据送入更“重”的Transformer通路,模型在不显著膨胀体积或降低速度的前提下获得了全局感知能力。
帮助网络聚焦重要信息
即便有了更好的构建模块,网络仍需决定应关注哪里。为引导这一点,作者引入了名为方向融合注意(Directional Fusion Attention,DFA)的机制。该模块观察图像宽度和高度方向上的模式,以及场景的整体摘要,并学习如何为不同区域和特征通道赋权。在实践中,DFA促使模型集中注意力于可能包含目标的区域——例如路面上的车形斑块——并削弱重复或令人困惑的背景纹理。这种空间与通道的联合聚焦使模型更容易将微小目标与杂乱背景或相似外观的背景区域区分开来。
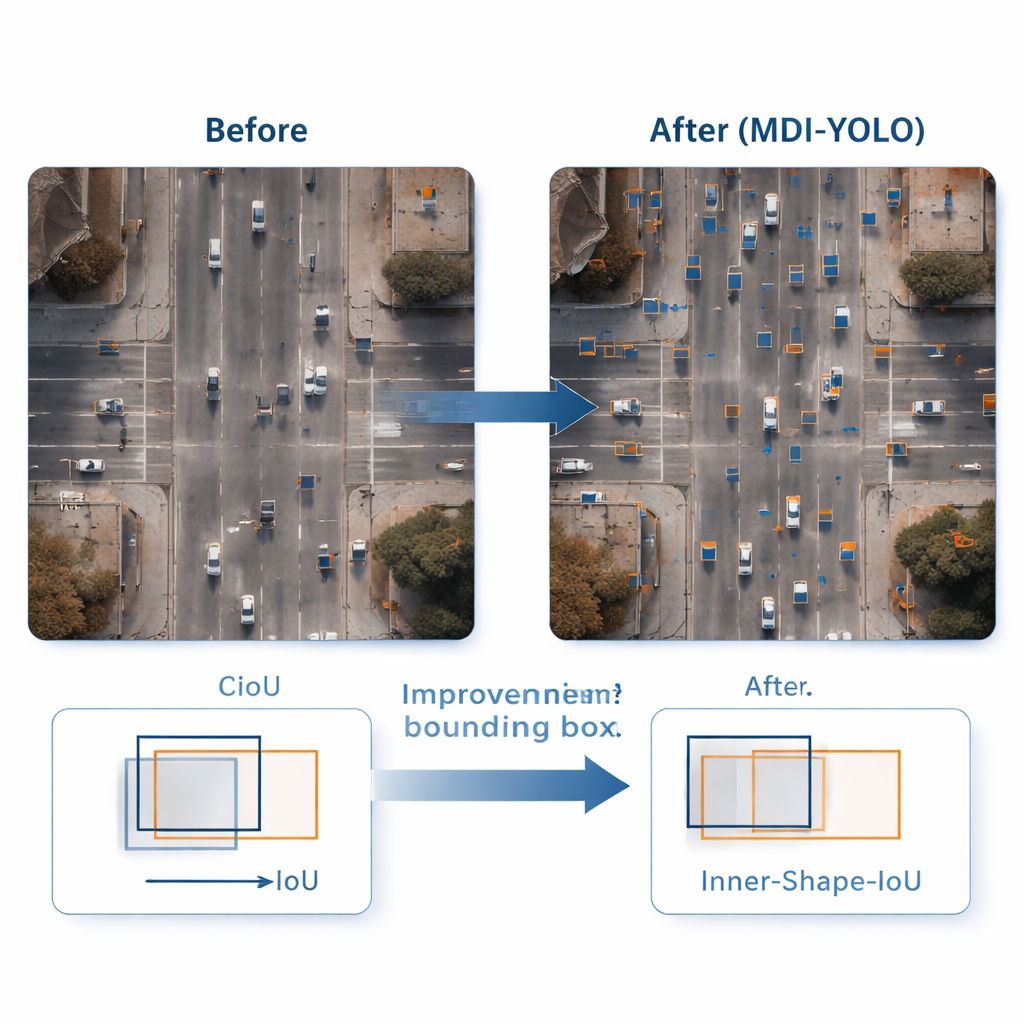
为微小目标画出更精确的框
发现目标只是部分工作;检测器还需要准确地勾画出其边界。标准训练方法通过“重叠”得分比较预测框与真实框,但当目标很小或形状奇特时,这种方式可能不够敏感。作者设计了一种新的损失函数Inner‑Shape‑IoU,它不仅根据重叠程度评判框,还考虑框的形状、大小和中心区域与真实目标的对齐程度。通过结合两种互补的度量,它会惩罚那些只在边缘上匹配而错过目标核心的框,从而产生更精确的轮廓,尤其适用于密集、细长或微小的对象。
在不增加负担的前提下取得验证效果
为了测试MDI‑YOLO,团队在两个具有挑战性的公开基准上进行了实验:VisDrone2019,包含城市与交通的无人机视频;以及DOTAv1.0,一个包含大量微小密集目标的航拍场景集。在不依赖预训练模型的情况下,MDI‑YOLO相比基线YOLOv8将标准精度指标提高了数个百分点,同时参数数量几乎保持不变且推理速度仍然快速。与一系列流行检测器对比——从轻量级YOLO变体到更重的基于Transformer的系统——它展现了少见的高精度、低计算成本和跨场景鲁棒性的结合。
对实际应用的意义
对非专业读者来说,结论是MDI‑YOLO能为无人机和遥感系统提供更清晰、更可靠的“视觉”,而不需要庞大、耗电的计算设备。通过巧妙融合全局语境、局部细节、定向注意力以及更具辨别力的边框训练方式,该方法使检测对安全、监控和制图重要的微小目标变得更容易。这类高效且高精度的视觉技术是朝着能够自主运行、快速响应并广泛部署的智能空中平台迈出的关键一步。
引用: Shi, H., Wu, Y., Xu, Y. et al. MDI-YOLO a lightweight transformer-CNN-based multidimensional feature fusion model for small object detection. Sci Rep 16, 7233 (2026). https://doi.org/10.1038/s41598-026-38378-x
关键词: 无人机成像, 小目标检测, 遥感, YOLO, 计算机视觉