Clear Sky Science · zh
一种多尺度端到端可见光与红外图像增强融合方法
为人和机器带来更清晰的夜视
任何尝试过夜间拍照的人都知道黑暗会多快破坏细节:场景显得颗粒感强、模糊并伴有奇怪的色彩。然而,许多关键技术——从路边摄像头和家庭安防到自动驾驶汽车和救援无人机——都必须在正是这些条件下看清楚。本文提出了一种将普通彩色摄像机与红外“热成像”摄像机结合的新方法,使计算机,最终也使人类,能够在接近全黑的情况下获得明亮且细节丰富的视图。
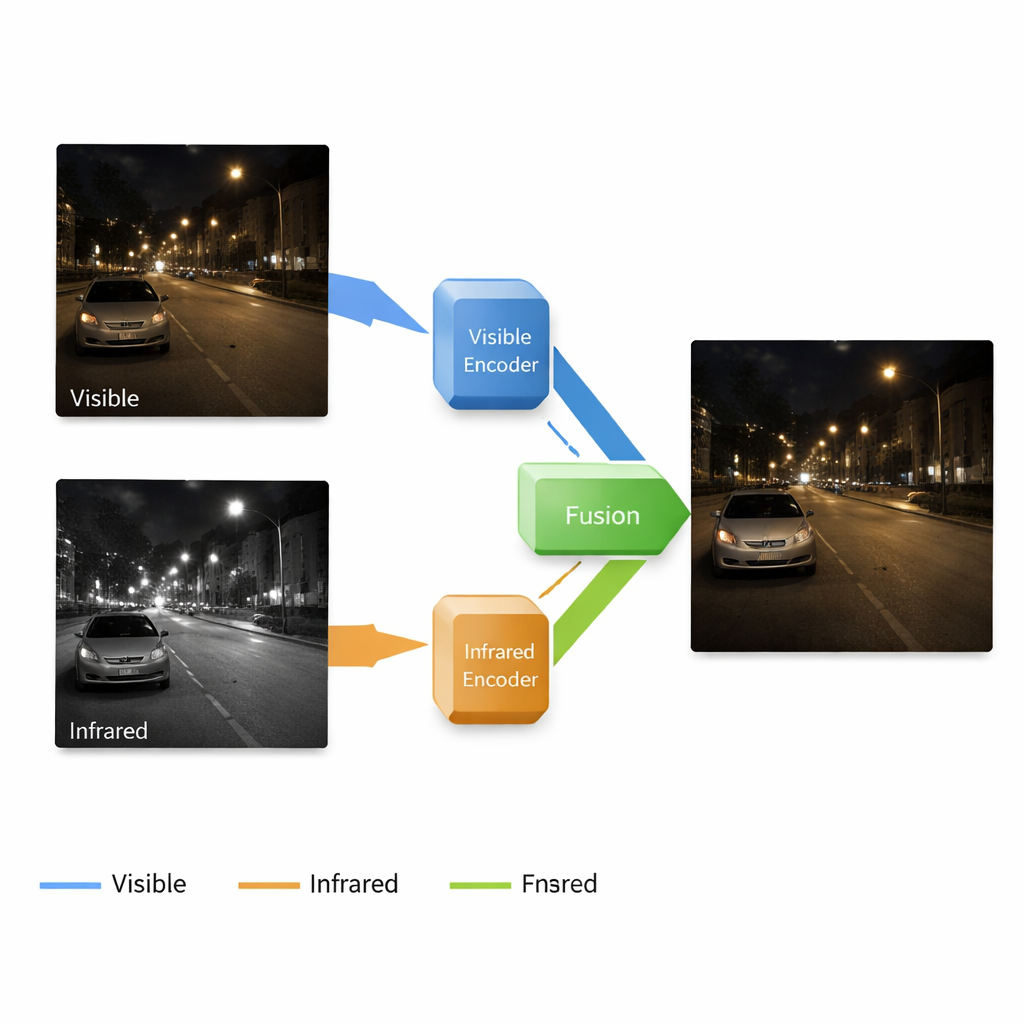
为什么两种摄像机胜过一种
标准摄像机捕捉的是我们眼睛能看到的光,这使得其照片易于人类解读,但在光线匮乏时表现很差:阴影吞没细节、噪点出现、颜色偏移。红外摄像机则相反:它们感知热图,能在黑暗或轻微雾霾中揭示人、动物和车辆,但图像缺乏精细纹理和自然外观。研究人员长期致力于将这两种视角融合为一幅既像清晰彩色照片又能显示隐蔽热源的图像。然而,现有方法常把每一步——增强暗光图像、去噪与合并红外信息——当作独立任务处理。这种零散的方法可能导致特征不匹配和令人失望的融合效果。
一个既增强又融合的单一流程
作者提出了一个端到端系统,在一条连续的流水线上同时增强并融合图像。它基于一个具有四个主要部分的神经网络:一条分支学习清理并增强弱光彩色图像,另一条分支学习表征红外摄像机的场景,融合模块结合各分支学到的内容,解码器则从这些混合信号重建最终图像。重要的是,系统在多尺度上工作,从粗糙的形状到细腻的纹理。浅层保留边缘和表面细节,如砖块或路面标记,而深层则捕捉更宽泛的结构——建筑、汽车或树木——以及红外图像中热目标的位置。
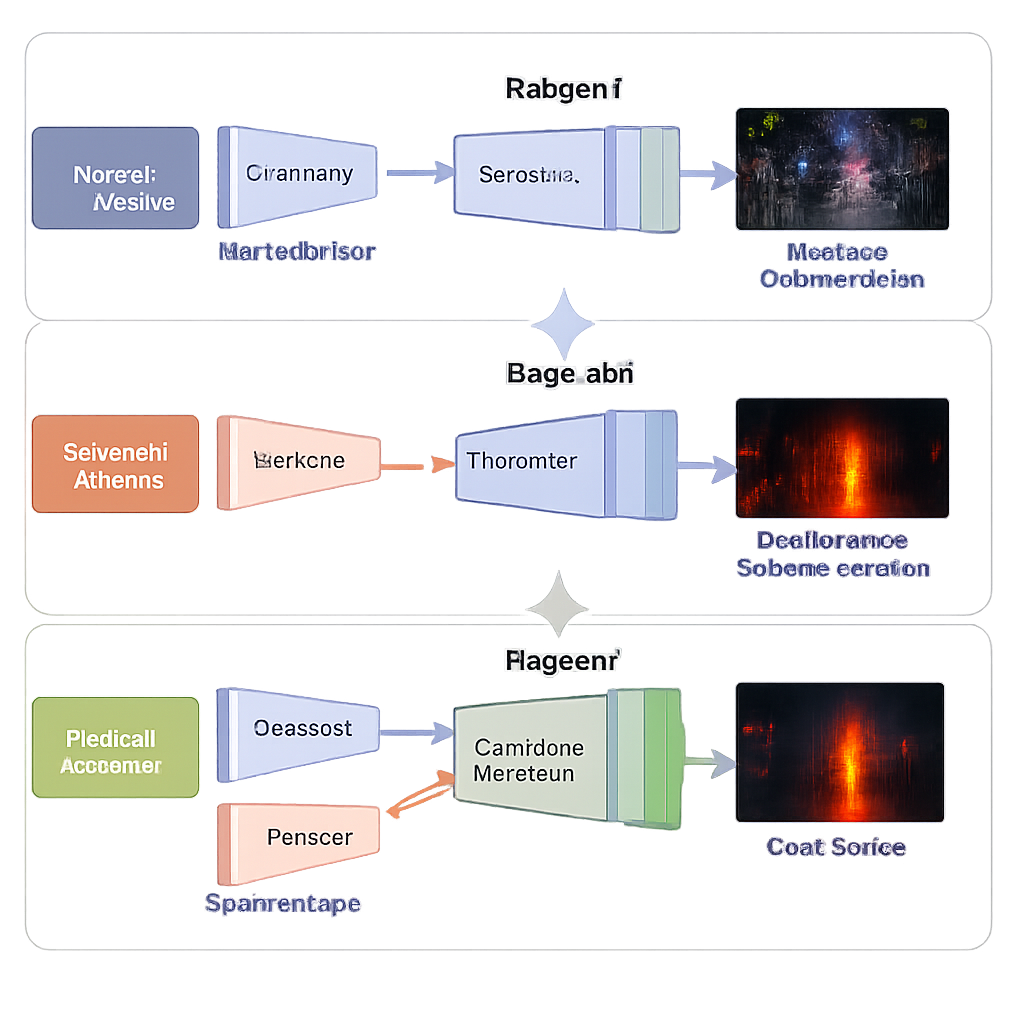
分三阶段学习而非一次性训练
研究团队没有一次性训练整个系统,而是采用了为稳定性和精度设计的三阶段学习策略。在第一阶段,网络只看到暗弱光的可见光照片,学习在没有人工“完美”参考图像的情况下增强亮度。精心选择的损失项推动输出具有自然的亮度、稳定的色彩、无斑块的平滑区域以及保留的纹理。在第二阶段,复用相同的解码器,同时新的红外分支学习忠实地重建红外图像,教会网络热模式应有的表现。在第三阶段,这些已学到的部分被固定,仅训练融合模块将两种表征混合成单幅高质量图像,既明亮又信息丰富。
方法检验
研究者在公开数据集上评估了他们的方法,这些数据集包含在光照困难条件下拍摄的可见光与红外配对图像,如夜间街道。他们与若干领先的融合技术进行了比较,包括基于经典图像变换的方法、标准卷积网络以及更复杂的生成模型。他们的方法总体上带来更清晰的细节、更均匀的亮度和更清晰的热目标,同时在信息含量、边缘清晰度、结构相似性和对比度等定量指标上得分更高。附加的消融实验表明,系统的每个部分——多尺度融合模块、分阶段训练以及可自适应权衡可见光与红外特征——都对最终质量有可测量的贡献。
这对真实世界视觉系统的意义
对非专业读者而言,结论很直观:这项工作表明,一个经过精心训练的单一网络既能增强昏暗场景,又能智能地将热成像与彩色视图融合为一幅连贯的图像。融合后的图像在突出温暖目标的同时保留细腻纹理,使其在夜间监控、驾驶辅助以及暗环境下的增强或虚拟现实等任务中更为有用。尽管作者指出仍存在一些问题——例如在非常明亮区域对比度降低以及对更快、更轻量模型的需求——他们的方法仍标志着朝着能在黑暗中可靠、自然且可解释地“看见”的摄像系统迈出了一步。
引用: Xin, Y., Huang, J., Sun, C. et al. A multi-scale end-to-end visible and infrared image enhancement fusion method. Sci Rep 16, 7135 (2026). https://doi.org/10.1038/s41598-026-38323-y
关键词: 弱光图像增强, 红外图像融合, 夜视, 多传感器成像, 深度学习视觉