Clear Sky Science · zh
用于异构电子病历系统的联邦学习与经济高效的参与者选择
为什么共享医院数据如此困难
现代医院收集了大量关于患者的数字信息,从化验结果和生命体征到用药和手术流程。理论上,将多个机构的病历合并应能让医生构建出更智能的计算模型,以预测谁存在风险以及哪些治疗可能最有帮助。然而在实际操作中,医院使用不同的软件系统、以不兼容的格式存储数据,并且必须严格保护患者隐私和预算。本研究探讨如何在不复制数据或过度开支的前提下,让医院互相学习彼此的数据。
在不共享原始记录的情况下共同训练
作者在一种称为联邦学习的方法基础上展开:每家医院在自己的患者记录上训练本地模型,然后只共享模型更新而非原始数据。一家中央“主办”医院负责协调此过程,目标是改进其自身需要的预测模型,例如预测重症监护中的并发症。其他医院作为参与方会获得补偿。这种设置避免了跨机构移动敏感记录,但也带来两个难题:如何处理多种不同的记录系统,以及如何避免为并未实际改善模型的合作方付费。
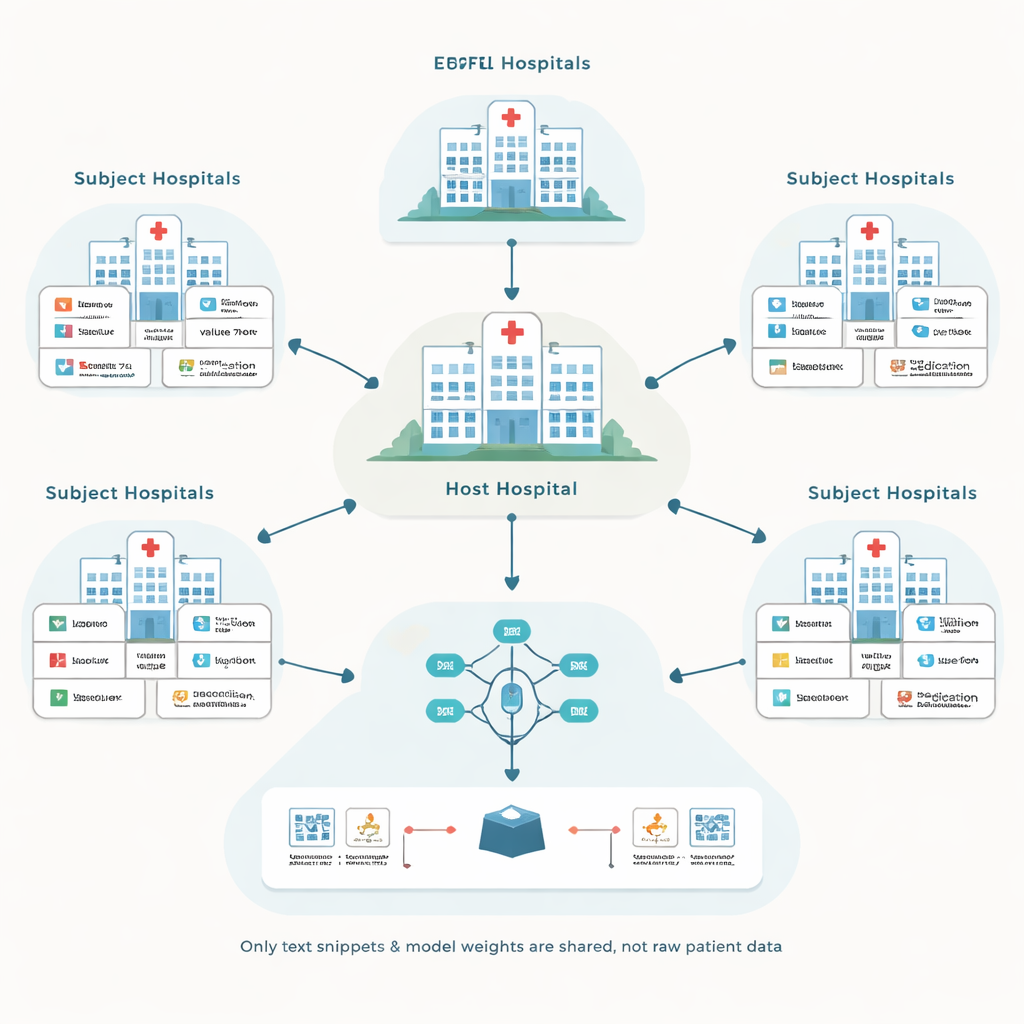
把混乱的记录转成共享的语言
电子病历系统在标注和编码信息的方式上差异很大。一家医院可能用某个数字代码存储血糖检测,而另一家医院对同一项检测使用不同的代码。传统解决方案试图将所有内容转换为单一、精心设计的标准数据库,这既昂贵又需要大量专家投入。相反,所提出的框架EHRFL将每个医疗事件转换为一段简短文本。例如,像葡萄糖测量这样的化验条目会变成“lab event glucose value 70 mg/dL”之类的短语。由于每家医院通常已有将本地代码映射到可读名称的字典,这种转换可自动化实现,无需大量人工调试。
从文本构建患者画像
事件被写成文本后,EHRFL 使用现代语言处理模型将每个事件转为数值向量,然后将多个事件合成为单个“患者嵌入”——对该人在某一时间窗口内病史的紧凑摘要。这些嵌入输入到一个预测层,处理多个临床任务,例如预测院内死亡或重症监护入院后肾损伤。作者在五个大型真实的重症监护数据集上进行了联邦训练,这些数据集跨越不同医院、不同时间段和不同记录系统。包括常用联邦方法在内的一系列算法测试表明,采用基于文本的方法训练的模型在各种情况下始终优于仅在单一医院训练的模型,即使底层数据格式不同。
在保护隐私的同时挑选合适的合作方
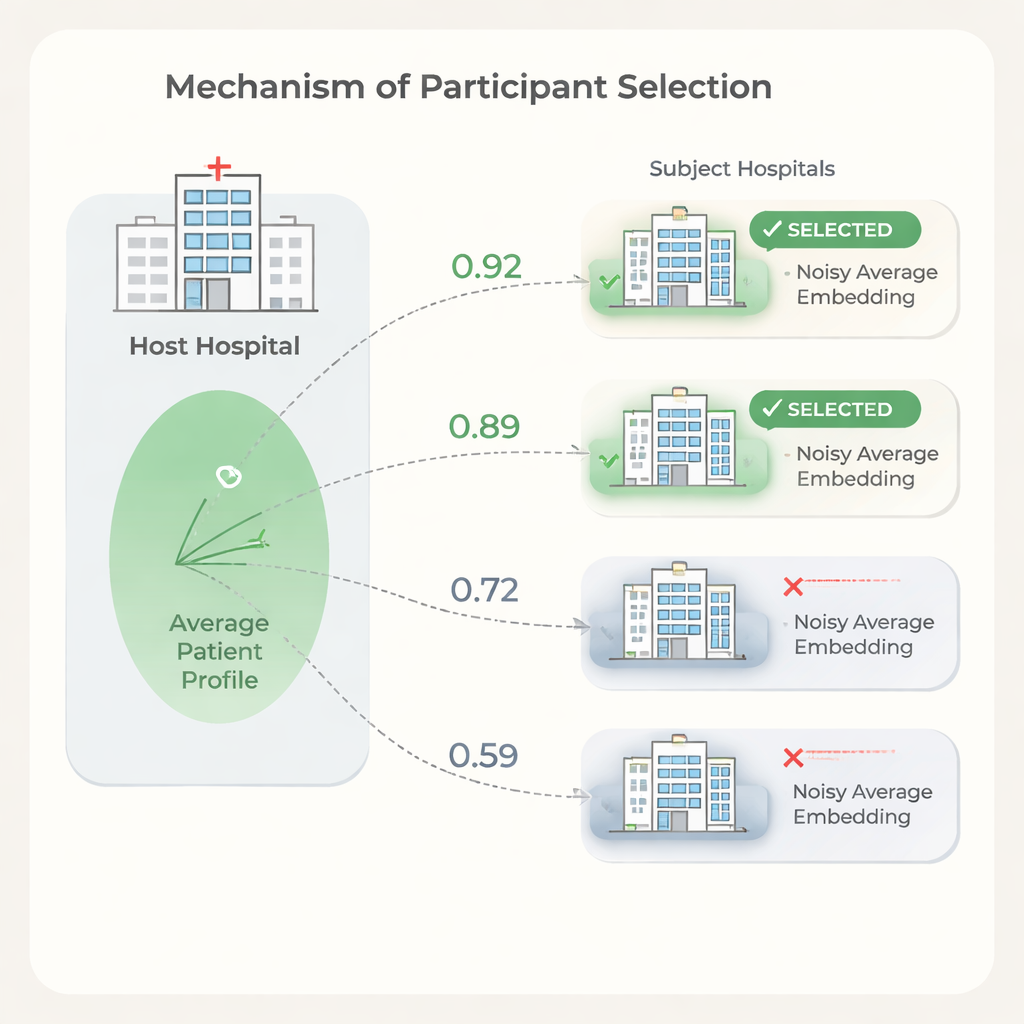
更多的合作医院并不总是带来更好结果。一些机构的患者群体或记录模式与主办方差别很大,纳入它们可能会减慢训练速度或略微降低性能,同时增加成本。为此,作者提出了基于医院间患者嵌入相似性的选择步骤。主办方先在自身数据上训练模型,分享模型权重,每个候选医院用这些权重计算患者嵌入。为保护隐私,每个参与方会截断嵌入中的极端值,将其平均为单个向量,然后在发送给主办方前添加精心校准的随机噪声,最终只发送这一带噪声的平均向量。主办方用简单的相似性度量比较自身平均向量与各参与方向量,并只选择与其最相似的医院加入完整的联邦训练。
节省经费而不损失精度
实验表明,医院之间平均患者嵌入的相似性与每家医院对主办方预测性能的帮助或损害程度一致。利用这一信号来选择合作方,主办方可以剔除相似性低的医院,同时在预测质量上保持甚至提升,比较之下优于使用所有可用站点。作者还给出了一个成本模型,说明由于数据使用费和训练时间会随参与医院数量增长,哪怕适度减少合作方也可带来显著节省。与此同时,该选择步骤计算成本低:模型只需训练一次,每家医院仅需对单个平均向量做简单运算。
这对未来医疗人工智能意味着什么
对非专业读者来说,关键信息是:医院可能在不合并原始病历的情况下“共同学习”,且能兼顾隐私与财务约束。通过将多样化的记录转换为共享的文本形式,再利用保护隐私的患者群体摘要来挑选兼容的合作方,EHRFL 提供了一个构建面向医院的预测工具的实用方案。虽然该研究侧重于重症监护数据,但相同思路可扩展到门诊、急诊室,甚至希望在不放弃数据控制权的情况下合作构建更好模型的非医疗领域。
引用: Kim, J., Kim, J., Hur, K. et al. Federated learning for heterogeneous electronic health record systems with cost effective participant selection. Sci Rep 16, 6876 (2026). https://doi.org/10.1038/s41598-026-38299-9
关键词: 联邦学习, 电子病历, 患者隐私, 临床预测, 医疗保健人工智能