Clear Sky Science · zh
NeuroAction:一种用于自动驾驶的神经进化强化学习方法
为什么更聪明的驾驶风格很重要
多数人把自动驾驶汽车想象成冷静、完全理性的司机。但当今系统往往追求一种固定的目标混合——例如在不出事故的前提下尽快到达目的地——而这类混合权重是由工程师预先设定的。本文所述的NeuroAction旨在赋予自动驾驶汽车更接近人类的灵活性:能够在多种安全驾驶风格之间进行选择,从谨慎的“车内有婴儿”式行为到利落的高速巡航,而无须每次都重新训练车辆。
从一刀切到多种安全选项
当前用于驾驶的深度强化学习系统通过试错学习:它们观察道路、执行转向与加速等动作,并获得一个将速度、安全性和车道位置等不同目标混合在一起的单一数值回报。要调整系统,工程师必须非常仔细地设计这个单一回报。如果对速度赋予过高权重,车辆可能会开得过于激进;若过分强调安全,车辆可能会缓慢前行。之后改变偏好通常意味着必须回到起点,从头重新训练一个大型神经网络,这既耗时、占用大量内存,又对技术设置敏感。
把驾驶拆成简单目标
NeuroAction通过将驾驶任务拆分为若干明确的目标来解决这个问题,而不是仅用一个目标函数。在研究中,虚拟驾驶员在三个方面被独立评估:在安全范围内的行驶速度、在最右侧(通常更安全的)车道上的保持程度,以及避免碰撞的能力。该方法并不把这些指标合成为单一分数,而是将它们作为独立的衡量标准。在后台,每一种可能的驾驶策略——将传感器输入转化为转向与速度决策的神经网络——同时在这三条轴线上被评估。
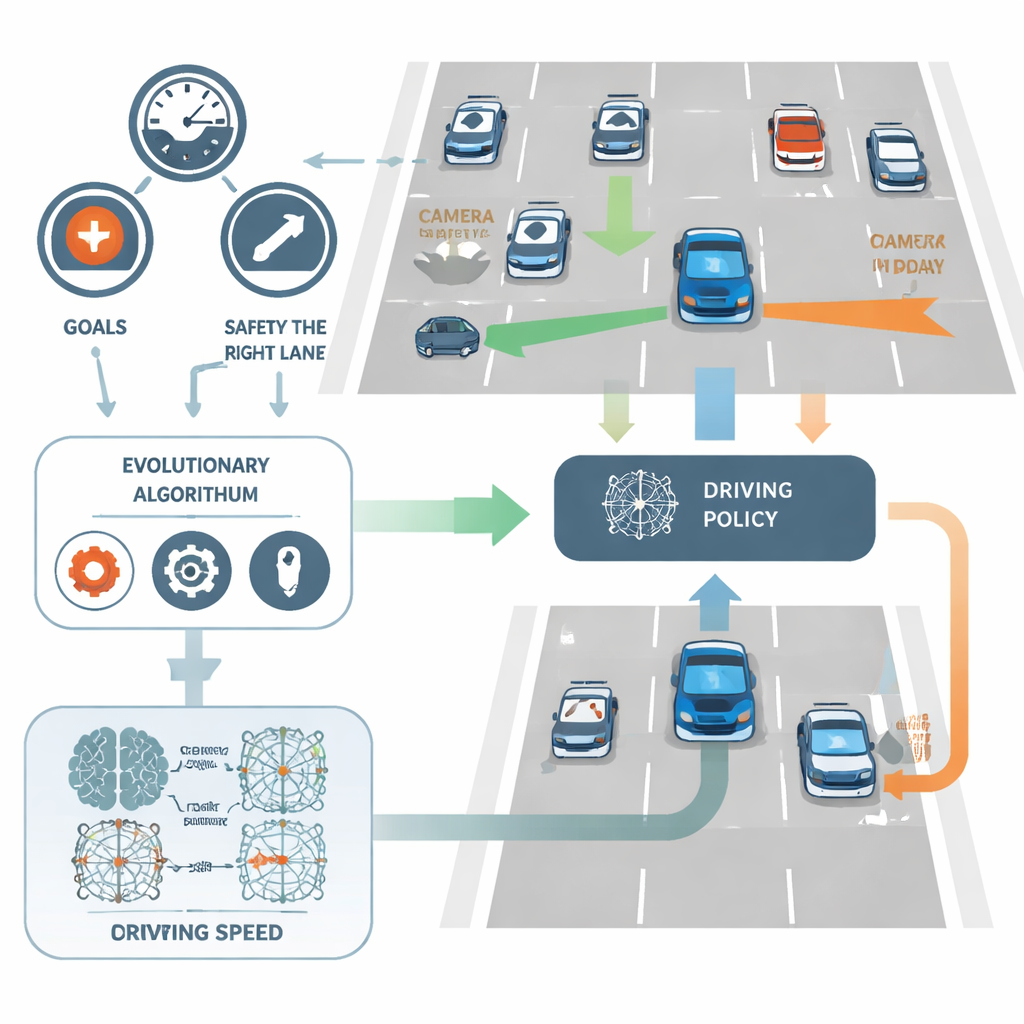
让进化去寻找更好的驾驶员
NeuroAction并不采用标准的反向传播来微调网络权重,而是借鉴生物进化的思想。研究中生成并测试了一群不同的驾驶策略,在模拟的高速公路环境中运行。那些在速度、车道纪律和安全之间取得良好权衡的策略被保留并重组,而表现较差的策略被淘汰。经过多代进化,这一过程发现了一整条强解的边界——称为帕累托前沿——在该前沿上无法在不牺牲至少一个目标的情况下改进某一目标。
比较进化方法与基于梯度的学习
研究者将NeuroAction应用于一个广泛使用的二维高速公路模拟器,采用了标准的基于神经网络的驾驶代理。然后他们用几种成熟的多目标进化算法来优化代理的参数,比较每种算法覆盖理想权衡范围的能力。一个关键性能度量——所发现前沿的“超体积”(hypervolume)——同时反映了解的质量与多样性。结果显示,算法NSGA-II在整体覆盖上表现最佳,而其近亲NSGA-III在重复运行中给出了尤为稳定的一致性结果。
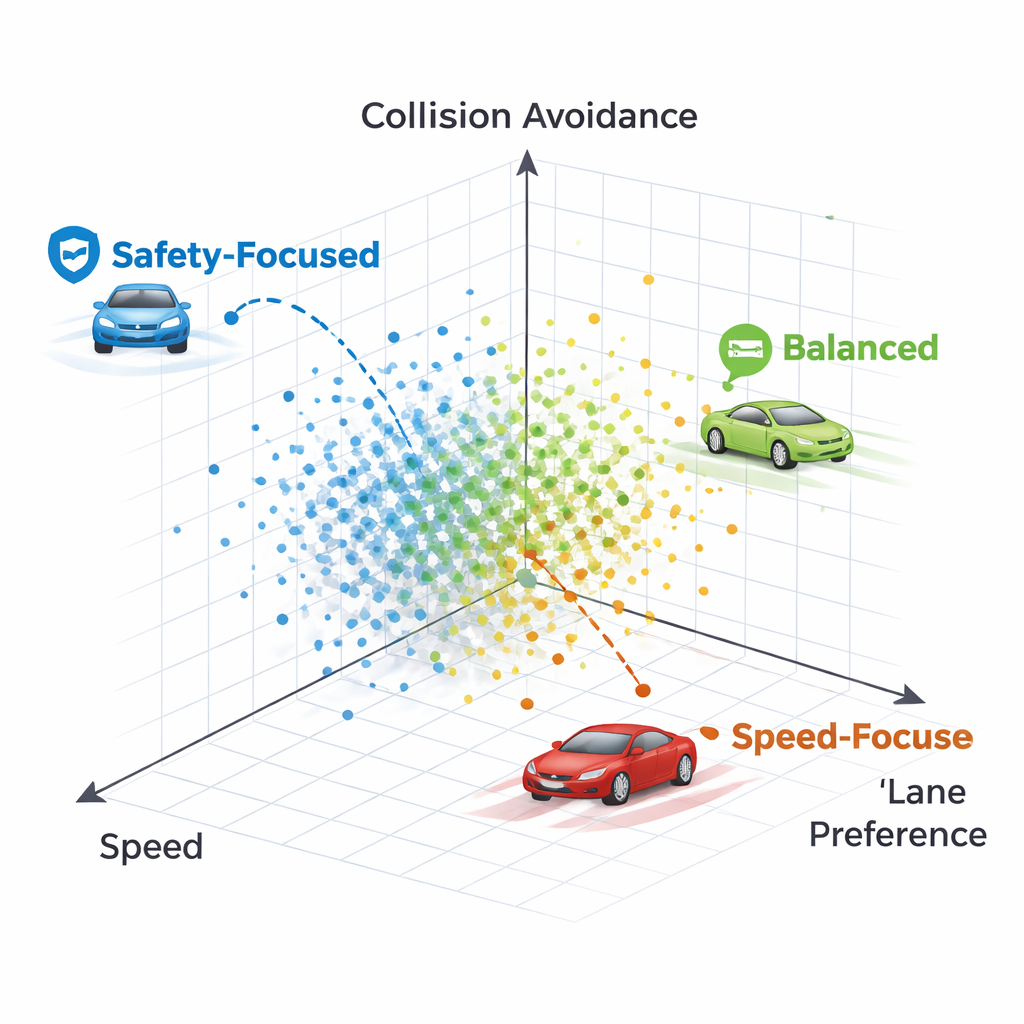
不同驾驶风格的样貌
通过检查帕累托前沿上的个别策略,作者展示了每个点代表一种可识别的不同驾驶风格。某些策略几乎不惜一切代价坚守右侧车道,牺牲速度并最终与前方非常慢的车辆发生碰撞——这是一种过度谨慎的策略,对车道偏好权重过高。另一些策略则先变道然后返回一条清晰的右车道,在保持较高速度的同时仍能避免碰撞。总体而言,这些方法产生了从保守的车道保持型司机到更果断但仍安全的巡航型司机的一系列策略,所有这些都可以同时可用而无需重新训练。
这对未来自动驾驶汽车意味着什么
对非专业读者而言,核心信息是NeuroAction将自动驾驶汽车的训练转变为寻找多种良好选项而非一个固定行为的过程。这样就可以根据情境选择驾驶策略——载有儿童时慢且极为安全,急事时则更快——同时仍然遵守安全约束。尽管当前实验在仿真环境中进行且使用了简化的目标, 该框架指向了更具适应性、能感知偏好并提供个性化但可靠驾驶风格的自主车辆,这一切建立在坚实的数学基础之上。
引用: Aboyeji, E., Ajani, O.S., Fenyom, I. et al. NeuroAction: a neuroevolutionary approach to reinforcement learning for autonomous vehicles. Sci Rep 16, 7403 (2026). https://doi.org/10.1038/s41598-026-38269-1
关键词: 自动驾驶, 强化学习, 进化算法, 多目标优化, 无人驾驶汽车