Clear Sky Science · zh
通过度量学习实现无秩张量分解
在数据海洋中发现模式
现代科学被复杂数据淹没:成堆的医学影像、脑活动图、天文图像以及材料模拟。理解这些数据通常意味着将其压缩为更简单的形式,同时不丢失真正重要的信息。本文提出了一种新的方法。它不是试图忠实重建每个像素,而是着重捕捉样本之间的真实关系——哪个大脑更像哪个,哪个星系形状更接近哪个——使得生成的数据映射反映的是意义而非原始细节。
从重建图像到测量相似性
传统的多维数据简化工具,被称为张量分解,有点像将和弦拆成若干音符。它们把数据“块”分解为少量基本模式及其权重。为此必须事先指定允许使用的模式数量——即“秩”,并以原始数据重建的好坏来评判成败。这对压缩或去噪很理想,但不一定适用于“这两张脸是同一个人吗?”或“这次脑扫描属于自闭症还是典型受试者?”之类更看重正确分组而非完美重建的任务。
与此同时,深度学习普及了另一种思路:不是代数上分解张量,而是通过神经网络学习紧凑的数值编码或嵌入。经典自编码器仍然以重建为目标。本工作颠覆了这一目标。它提出了一个“无秩”框架,不事先固定秩,也不关心像素级的完美恢复。相反,它学习一种距离度量,使得应该靠近的点(同一人、相同诊断、相同物理类别)在嵌入空间成邻居,而应当不同的点被推远。
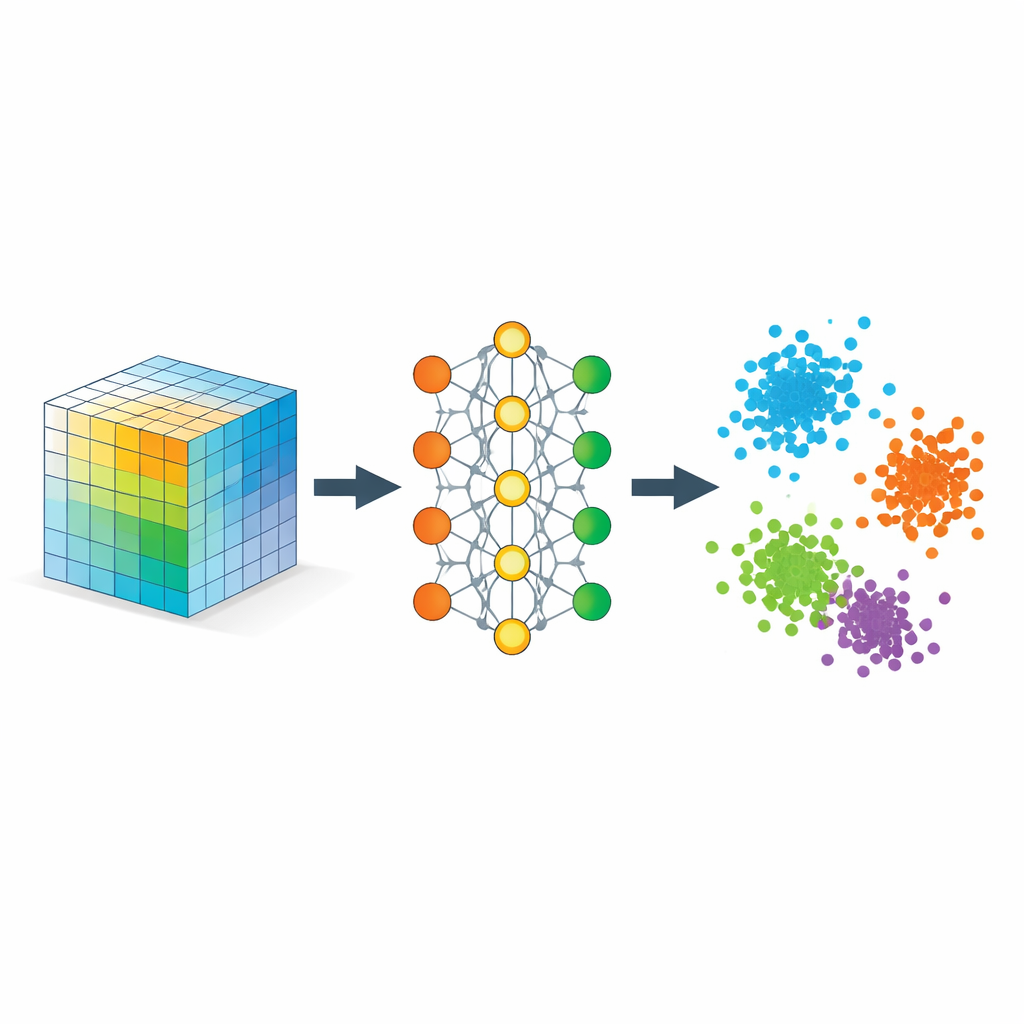
教网络什么是“靠近”
关键成分是一种称为度量学习的策略,这里通过三元组示例来实现:一个锚点样本、一个同类的正样本和一个不同类的负样本。在训练过程中,当锚点比负样本更靠近正样本且满足一定安全边距时,网络会获得奖励。经过大量此类三元组,这条简单规则雕塑出嵌入空间,使得距离反映语义相似性而非原始像素相似性。附加的正则项则鼓励网络将信息均匀分布在各维度上,避免把所有东西塌缩到一条线上,并尽量保持局部邻域结构,使得在原始数据中相邻的点在嵌入后仍然相邻。
在数学上,作者表明这种嵌入行为类似一种灵活的张量分解,但不需要预设秩。学习到的坐标可以被解释为经典相似张量分解中的因子,该相似张量的条目衡量数据不同部分之间的对齐强度。因为模型对冗余方向施加惩罚,它倾向于有效利用所有嵌入维度,让数据本身决定需要多少有意义的成分。与此同时,作者给出了理论保证,证明标准训练过程会收敛,且所得几何结构在分离类别的同时不会过度扭曲有意义的局部关系。
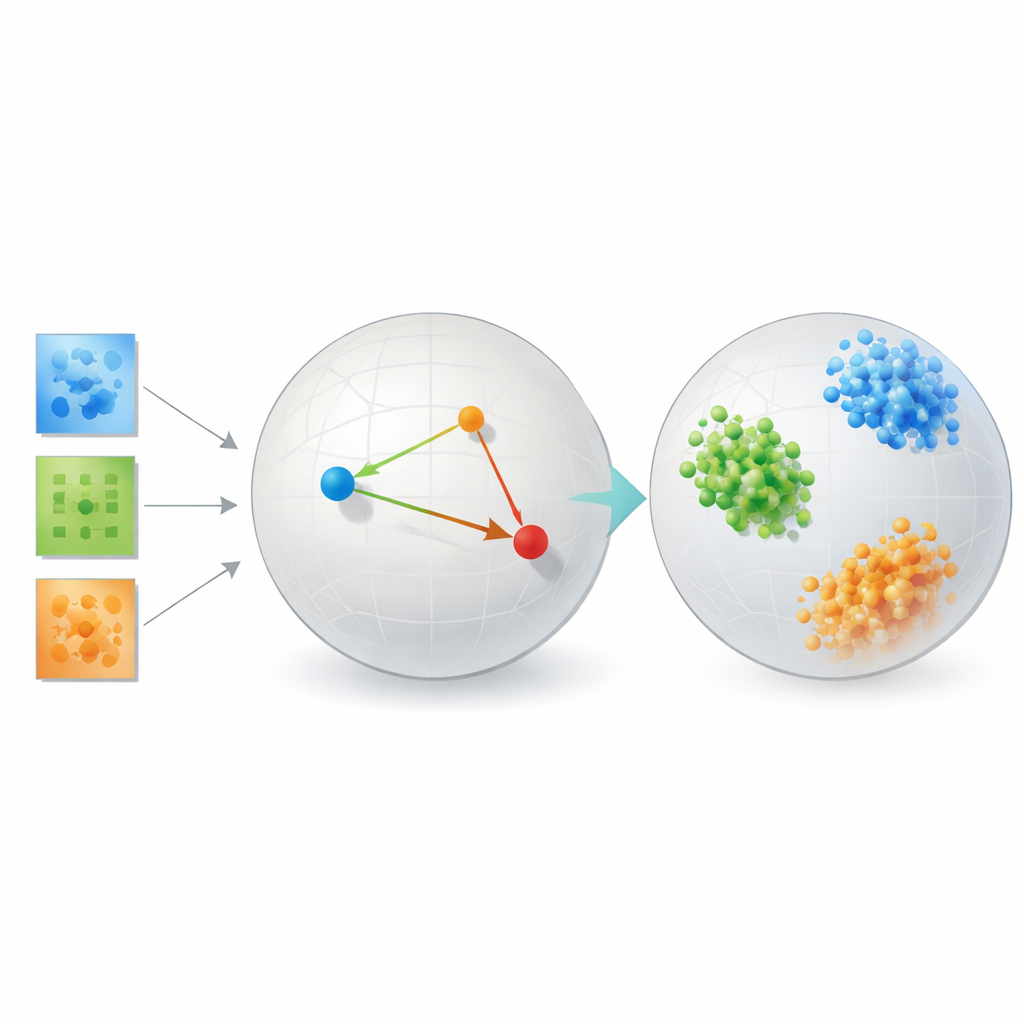
将方法付诸测试
为了证明他们的方法不仅是优美的理论,作者在若干迥异的问题上进行了测试。在人脸识别基准上,学习到的嵌入将同一人的图像聚成紧密且彼此分离的簇,显著优于主成分分析等经典方法、t-SNE 与 UMAP 等流行可视化工具,以及依赖固定秩的传统张量分解。在来自有无自闭症个体的脑连接性数据上,该方法发现了一个两组比重建导向的张量工具或自编码神经网络更清晰分离的空间,暗示其可能聚焦于与临床相关的大脑区域交互模式。
研究还包括对银河形状和晶体结构的受控模拟,那里“真实”类别是确切已知的。在这些情形中,度量学习框架几乎完美地按其底层物理类型对合成银河和晶体进行聚类。在所有这些设置中,该方法一致地在对原始像素布局的某种忠实度与使相似性与科学意义对齐的表征之间进行权衡。重要的是,它在这些相对较小的科学数据集中不依赖于训练基于变换器的大型深度模型所需的大量数据和计算资源,而那些模型在这些任务上表现并不理想。
这对未来科学数据的重要性
对于在有限、高维数据中寻找模式的科学家来说,这项工作提供了一个吸引人的视角转变。研究者无需猜测秩并为重建优化,而是可以直接要求一种反映他们关心关系的嵌入:相同诊断、相同材料相态、相同天体学类别。提出的无秩度量学习框架表明,这类嵌入既可以解释也很强大,尤其在数据稀缺时更是如此。如作者所述,仍有挑战需要解决——包括处理类别不平衡与扩展到大量类别——但结论清晰:在许多科学问题中,学习一个良好的相似性概念可能比重建原始信号的每个细节更有价值。
引用: Bagherian, M. No-rank tensor decomposition via metric learning. Sci Rep 16, 8326 (2026). https://doi.org/10.1038/s41598-026-38221-3
关键词: 度量学习, 张量分解, 表征学习, 降维, 科学数据分析