Clear Sky Science · zh
一种用于多标签文本情感检测的混合堆叠集成学习框架
为何识别文本情感很重要
每天,人们在社交媒体帖子、评论和消息中倾诉情感。在这洪流般的文字中,隐藏着关于心理健康问题的早期预警、上升的仇恨言论以及公众对危机和灾难的反应。但计算机通常只看到“正面”或“负面”的情绪,错过了现实中人们常同时表达的多种情感。本文探讨了一种新的方法,教机器在同一段文本中识别多种情感,并不仅限于英语,还覆盖那些很少享受先进人工智能成果的语言。
超越简单的正负判断
传统的情感分析工具像是粗糙的温度计:它们能判断情绪是好还是坏,但无法识别某人在同时感到愤怒、恐惧、希望或如释重负等具体情绪。作者认为,理解这种更丰富的情感谱对灾难响应、心理疗法支持和客户服务等应用至关重要。例如,一条同时包含恐惧和紧迫感的信息可能需要立即关注,而夹杂悲伤与乐观的信息则可能需要不同类型的支持。因此,同时捕捉多种情感——即“多标签”情感检测——是迈向更敏感、更具人性化系统的重要一步。
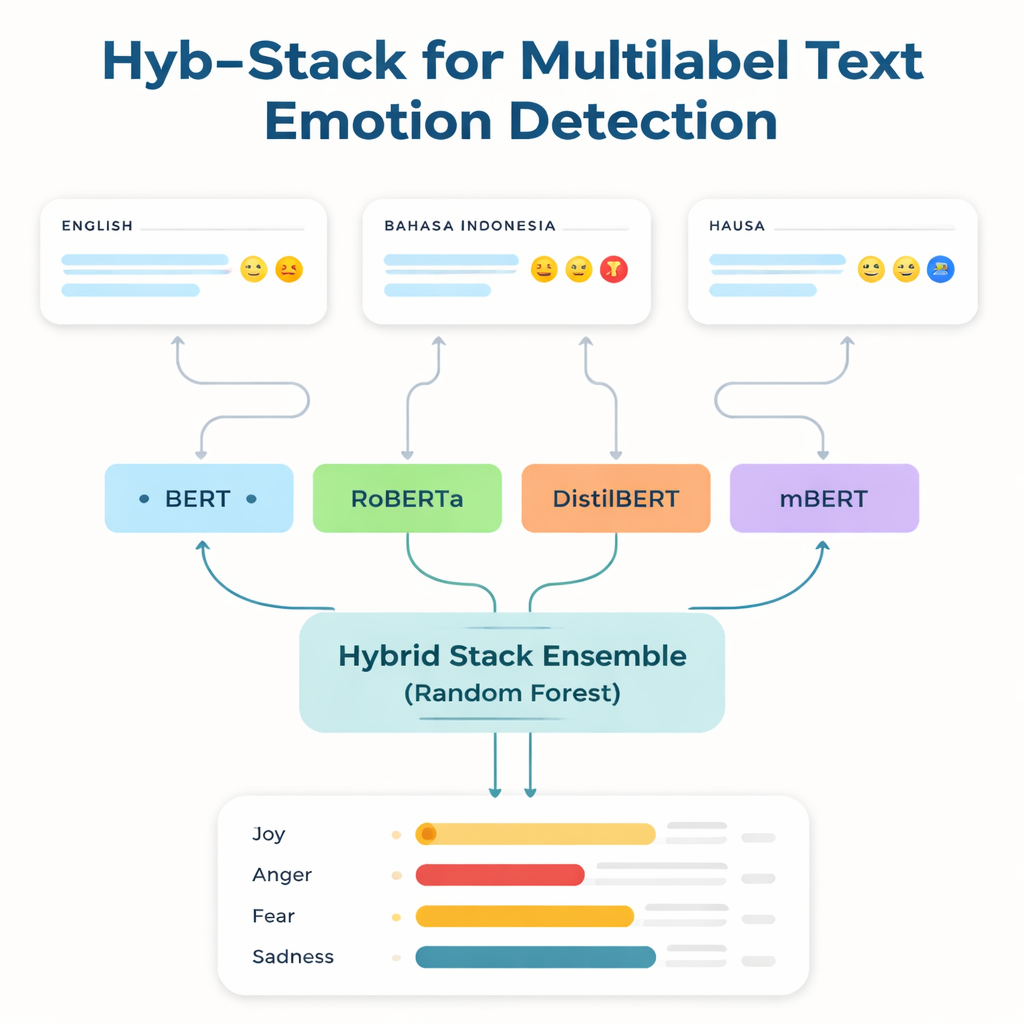
为被忽视的语言发声
大多数强大的语言技术都是在英语和少数其他广泛使用的语言上训练和调优的。资源匮乏语言的使用者——那些缺少标注数据和数字工具的语言群体——常被落下。为缩小这一差距,研究者关注三套数据集:一套知名的英语情感基准;一套以辱骂和仇恨言论为中心的印度尼西亚语(Bahasa Indonesia)语料;以及他们新建的豪萨语(Hausa)推特语料库,名为 HaEmoC_V1。豪萨语数据集包含一万二千多条经过精心清理和标注的推文,每条标注有一种或多种情感(共十一类),如愤怒、喜悦、信任、悲观和期待。专家审阅者对标签进行了检查,达成度量显示这些注释既一致又可靠。
把若干个智能阅读器组合为一体
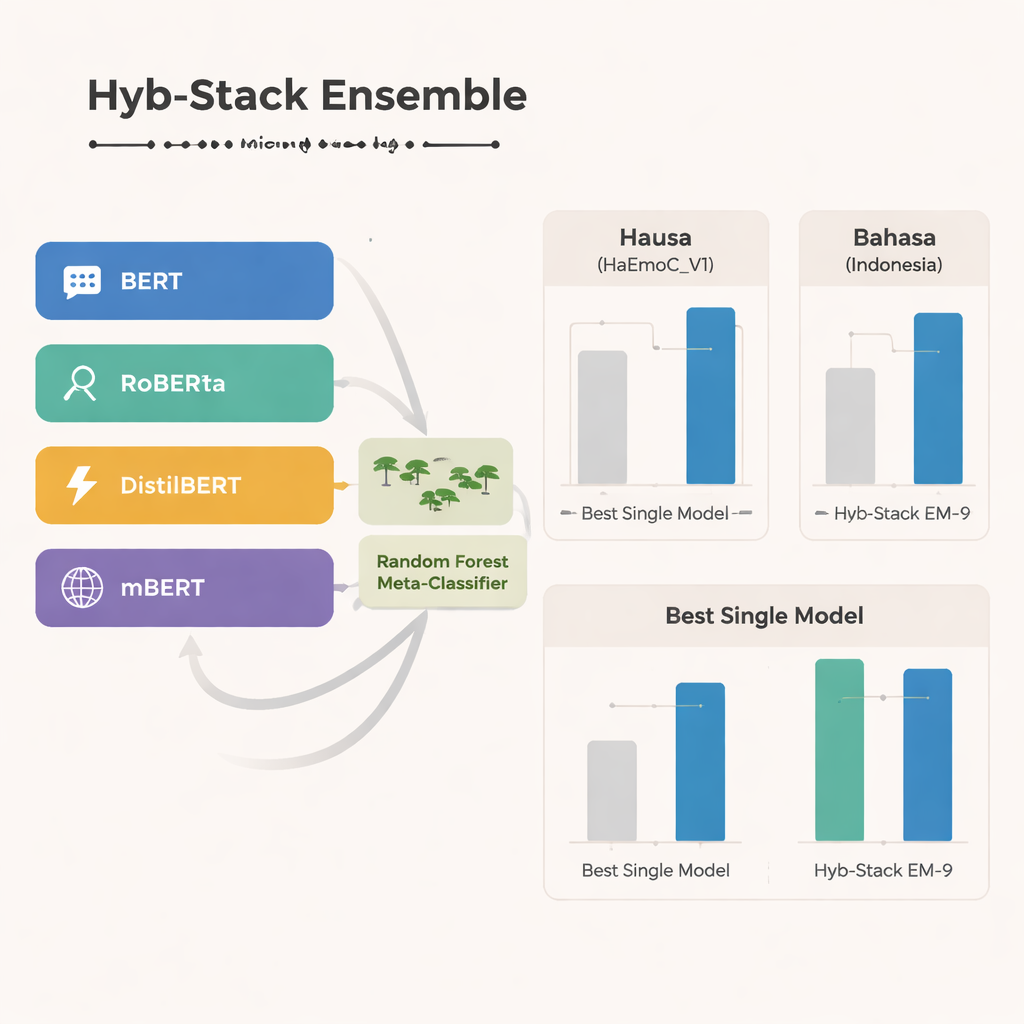
研究的核心是 Hyb-Stack,一种混合堆叠集成——类似于语言领域的“专家委员会”。四个先进的基于变换器的模型(BERT、RoBERTa、DistilBERT 和多语种 mBERT)分别进行微调,用以识别文本中的情感信号。Hyb-Stack 不只信任某一个模型,而是让它们都给出预测,然后将它们的内部得分输入到第二层的决策者:随机森林分类器。这个元分类器学习如何权衡每个模型的不同优点,捕捉情感共现的复杂模式。团队还测试了更简单的集成方法,例如仅对预测取平均、或依据先前表现加权的平均,以检验更复杂的堆叠方式是否真实带来优势。
混合方法的表现如何
在三种语言的所有数据集上,多语种 mBERT 作为单一模型表现最为突出,尤其在新建的豪萨语数据和印度尼西亚语仇恨言论集合上表现良好。然而,混合集成表现更佳。其中一个特定组合——称作 EM-9,将 BERT、DistilBERT 和 mBERT 在 Hyb-Stack 框架内合并——持续提供最佳结果。与任何单一模型或简单平均方法相比,它在 F1 分数(一种常用的准确性度量)上更高,最大提升出现在资源稀缺的豪萨语和印度尼西亚语数据集。详细的错误分析显示,剩余错误通常发生在相近情感之间,例如喜悦与惊讶、悲伤与恐惧,这反映了人类情感的自然模糊性,而非明显的系统性失败。
对真实系统意味着什么
对一般读者而言,主要结论是:以智能方式组合多个 AI 模型可以让计算机更准确地读取文本情感,尤其是在长期被技术忽视的语言中。通过构建高质量的豪萨语情感语料库并展示混合集成优于单一模型与简单投票方案,作者们表明了一条通向更具包容性、情感感知工具的实用路径。未来工作将把该方法扩展到更微妙的情感层次、混合语(code-mixed)语言、表情符号及更多代表性不足的语言,目标是构建能感知人们不仅是快乐或悲伤,而且能理解他们为何及如何产生这些情绪的系统——无论他们说何种语言。
引用: Adamu, H., Azmi Murad, M.A. & Nasharuddin, N.A. A hybrid stacked ensemble learning framework for multilabel text emotion detection. Sci Rep 16, 7714 (2026). https://doi.org/10.1038/s41598-026-38172-9
关键词: 情感检测, 多语种自然语言处理, 集成学习, 变换器模型, 资源匮乏语言