Clear Sky Science · zh
高效计算与高速双精度吠陀乘法器架构的设计
为何更快的数值计算至关重要
每当你流媒体观看视频、在手机上使用导航,或让人工智能系统分析医学影像时,专用计算硬件都会在后台每秒执行数十亿次微小运算。其中很大一部分是对“浮点”数的乘法运算——浮点数是计算机表示实数(如 3.14159)的标准方式。本文探讨了一种更聪明的构建方式:一种借鉴古代吠陀数学思想的高速、能效更高的乘法器,以提升现代数字硬件的性能。
从古老算术技巧走向现代芯片
浮点算术是数字信号处理、图像处理、通信和深度学习加速器的基础。标准乘法器必须处理宽位二进制字——双精度使用 64 位——并且要在不浪费芯片面积或功耗的前提下尽可能快地运行。传统方法(如 Booth、Karatsuba 和阵列乘法器)在速度、硬件规模和设计复杂性之间权衡。吠陀数学是印度发展出的 16 条经典算术规则体系,其中一种乘法方法称为 Urdhva Tiryakbhyam(“纵横”法),该方法以高度并行的方式生成部分积,从而可以减少中间步骤和所需硬件。研究者最近已将这些思想改编到数字电路中,但现有设计在用于双精度浮点运算时仍存在开销。
这款新乘法器的独特之处
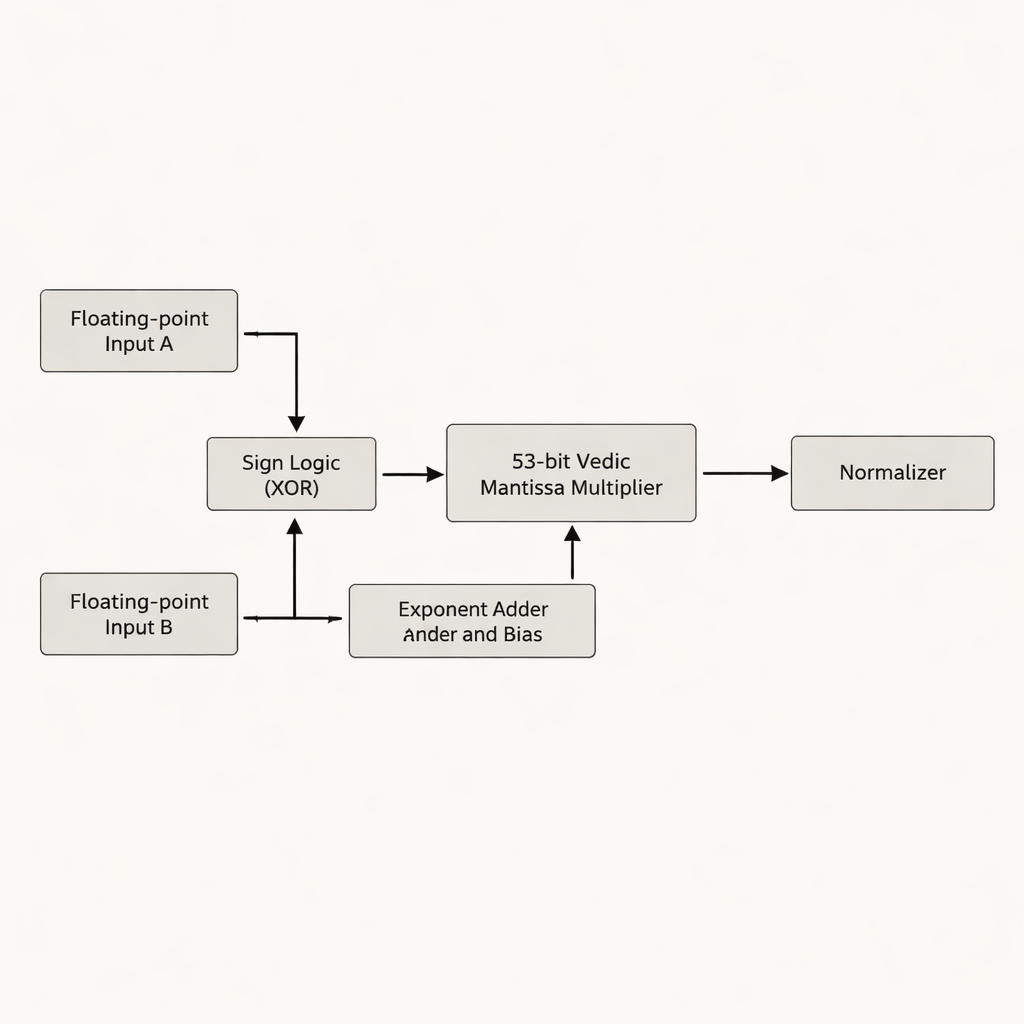
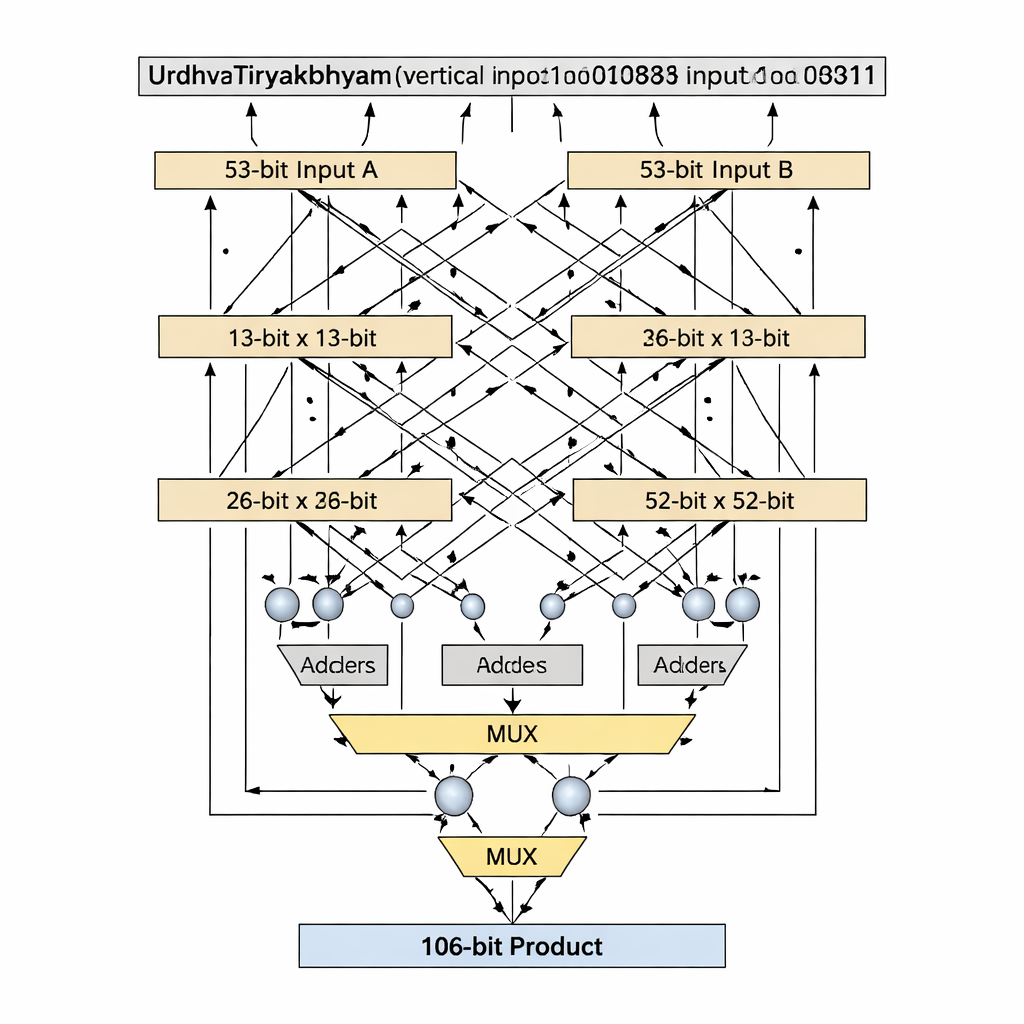
作者提出了一种聚焦于尾数(mantissa)的双精度浮点乘法器——尾数是浮点数中保存大部分有效数字的部分。与许多早期设计将 52 位尾数填充到 54 位不同,他们直接以真实的 53 位有效尾数为工作位宽,避免了浪费的“空白”位,这些位会占用额外存储和芯片连线。设计核心是基于 Urdhva Tiryakbhyam 的 53 位吠陀乘法器,按较小构建模块的层次组织:以 3 位单元构成 6 位单元,再构建 12 位、13 位、26 位和 52 位单元,最终组合成 53 位级。该架构将工作分为三个主要阶段——符号计算、阶码相加与偏置、以及尾数相乘并随后的规格化——既符合 IEEE-754 浮点标准,又裁剪了冗余电路。
用素数位宽构件实现更简洁的硬件
一项关键创新在于如何处理素数位宽(如 13 位和 53 位),这些位宽不能被均匀地拆分为等大小模块。标准吠陀分解假定输入能被均匀划分,但对于素数长度这会变得尴尬或浪费。作者提出了一种“素数位”算法,该算法巧妙地重用更小的 (n−1) 位吠陀乘法器,辅以加法器、多路选择器和单个额外逻辑门,来模拟 n 位乘法器而无需填充。以 13 位级为例,输入被划分为 1 位和 12 位段;利用 12 位吠陀乘法器、基于最高位的条件选择(通过多路选择器)以及少量加法器生成部分积。相同模式可扩展到以 52 位为核心的 53 位级。这种定制分解缩短了关键路径——信号必须经过的最长逻辑链路——同时保持逻辑单元数量较低。
在速度、规模与功耗上的实测收益
该设计以 Verilog 硬件描述语言实现,并在 Xilinx Zynq 可编程门阵列(FPGA)上使用 Vivado 工具综合部署。在 13、26、52、53 和 64 位的吠陀乘法器比较中,所提出的 53 位单元在延迟、逻辑使用(查找表与 I/O 引脚)和估算功耗之间表现出良好平衡。与基于 Booth、Karatsuba 及其他吠陀排列的早期双精度乘法器相比,新架构显著降低了最坏情况延迟和所需 FPGA 资源量,同时没有增加周边浮点电路的复杂度。由于尾数乘法更快且逻辑深度更浅,切换活动减少,这表明尽管直接跨技术的功耗比较困难,但该设计在功耗-延迟乘积上具有优势。
对人工智能与信号处理的影响
为在实际工作负载中测试该设计,作者将他们的吠陀双精度乘法器集成到卷积神经网络(CNN)的卷积引擎中,在该处乘加(MAC)操作主导运行时间。将传统 IEEE-754 与早期吠陀乘法器替换为新设计后,卷积延迟减少、功耗下降、推理时间缩短,同时分类准确率保持不变。类似优势也预期适用于其他计算密集任务,例如数字滤波、边缘检测和医学影像处理管线——更快的乘法器能直接提高吞吐量,并让设备更凉爽或使用更小的电池。
对日常技术的意义
简而言之,本文表明:将吠陀数学中一种精巧的乘法思想借用并将其与现代二进制格式精心匹配,能够产生一种比标准设计更小、更快且更节能的乘法器。这个改进的构建模块可以插入处理器、信号处理芯片和 AI 加速器,从而带来更快的数据分析、更灵敏的设备以及在从智能手机到医学扫描仪的系统中潜在的更低功耗。作者还提出了未来方向,包括用于更低能耗的可逆逻辑以及并入更大型处理单元,暗示这一古老算术与现代硬件的结合才刚刚起步。
引用: Kumar, A.S., Sahitya, G., Kusuma, R. et al. Efficient computation and design of high speed double precision Vedic multiplier architecture. Sci Rep 16, 7364 (2026). https://doi.org/10.1038/s41598-026-38147-w
关键词: 吠陀乘法器, 浮点算术, FPGA 设计, 数字信号处理, 卷积神经网络