Clear Sky Science · zh
UncerTrans:面向早期动作预测的具不确定性感知的时间变换器
为什么及早看懂动作能保我们安全
想象一下,一台家用机器人只凭一次手腕轻摆就能判断某人是要将热水安全地倒入杯中,还是可能不小心撞翻水壶。在工厂、医院和智能家居中,机器越来越多地与人共享空间,只有在事故开始后才作出反应就太晚了。本文提出了UncerTrans,一种新的人工智能系统,不仅能基于动作的最初阶段预测人可能要做的事情,还会告诉我们它对自身猜测有多确信——当涉及到人的安全时,这种能力至关重要。
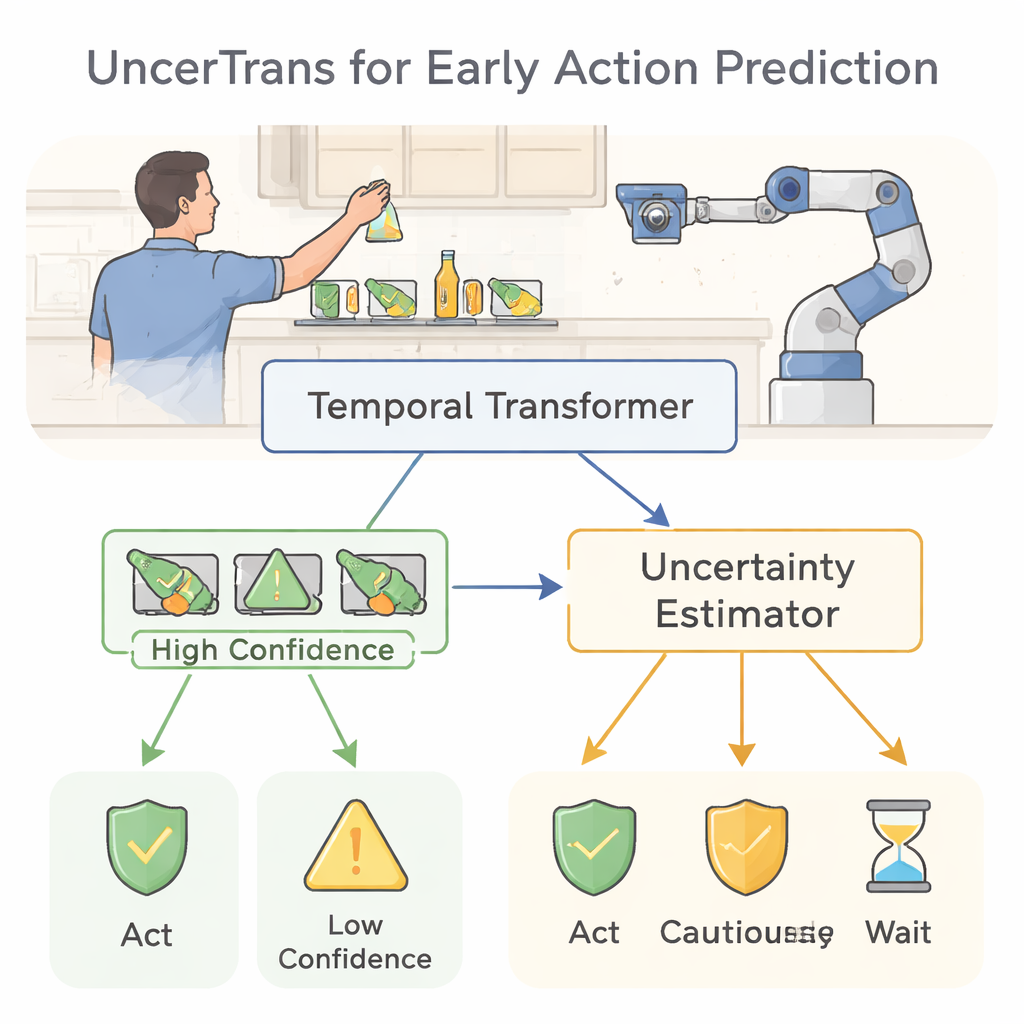
从观察到预测人的动作
目前大多数计算机视觉系统只有在动作接近完成时才会识别出某人在做什么:它们将完整的视频片段分类为“切菜”或“拿杯子”。这对事后分析有帮助,但无法防止烫伤、碰撞或跌倒。早期动作预测解决的是更困难的问题:在只看到动作的10–20%时便判断完整动作将会是什么。挑战在于许多动作在开始时看起来很相似——伸手拿水壶可能意味着要倒水,也可能意味着要把它撞翻——因此系统必须在信息有限的情况下仍然避免产生危险错误。
教机器关注关键时刻
UncerTrans通过使用时间变换器来应对这一点,这是一种最初为语言任务开发的现代神经网络架构。它不是读取句子中的单词,而是观察随时间变化的短视频片段。模型将早期动作序列分成若干段,并使用注意力机制决定哪些时刻最重要。对最近帧给予更高权重,呼应了我们的直觉:最新的动作通常最能揭示意图。这一设计使系统即便只看到整个动作的一小部分,也能捕捉到指尖等细微动作和手臂轨迹等更大尺度的模式。
让机器学会承认不确定
UncerTrans的一项关键创新是不满足于给出单一的确定答案。相反,它使用一种称为蒙特卡洛丢弃(Monte Carlo dropout)的技术对相同输入执行多次略有不同的推断。每次运行随机丢弃不同的内部连接,从而产生略有差异的预测。通过观察这些预测间的分歧程度,系统可以估计自身的不确定性:聚集紧密的预测表示高置信度,而分散的预测则表明存疑。UncerTrans进一步区分了由有限训练经验引起的不确定性和视频本身噪声,并动态调整测试运行次数——当初始样本看起来模糊时使用更多次,当样本已达成一致时则使用更少次。
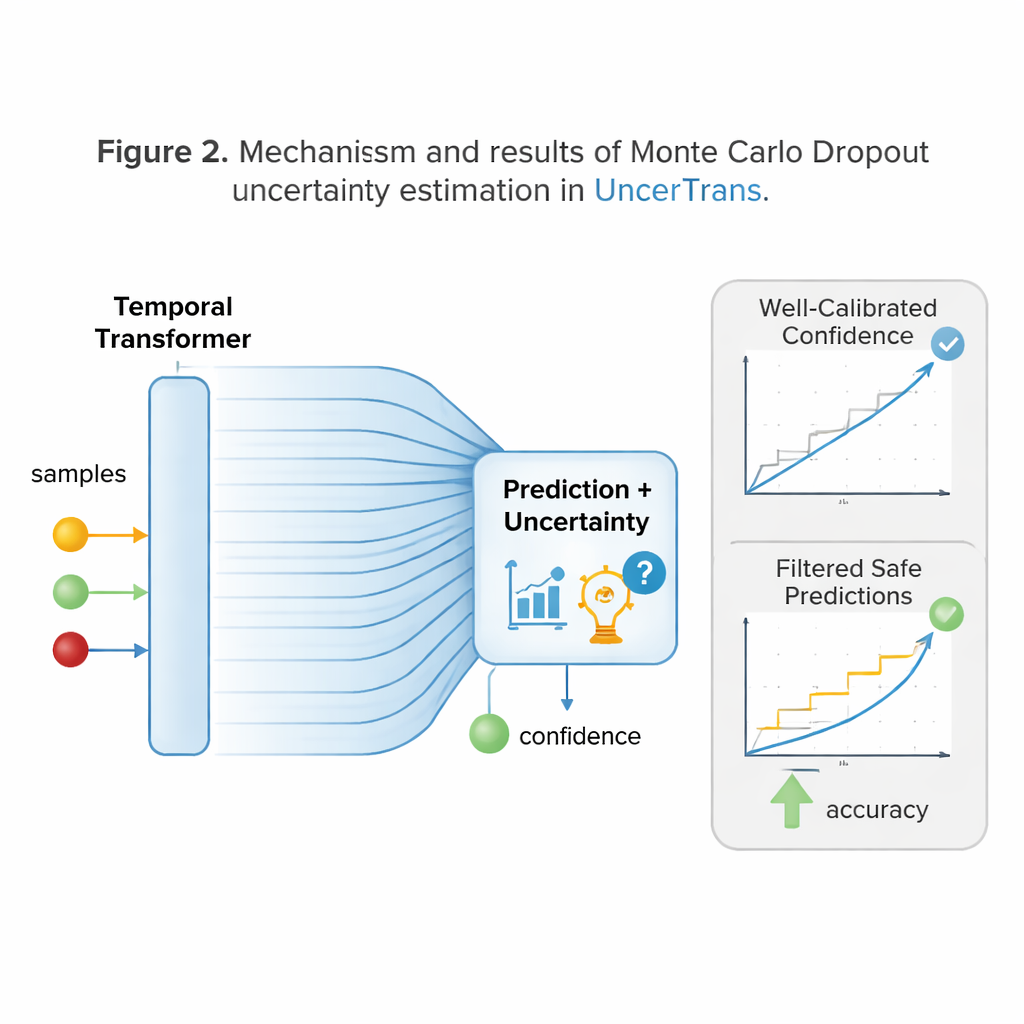
把置信度转化为更安全的决策
知道自己可能出错只有在能改变行为时才有用。UncerTrans将其置信度估计转化为实际决策。对于不确定性低的预测,系统可以果断行动——例如触发警告或将机器人臂移出危险区域。处于中等不确定性的情况下,它可以选择更保守的行为,如减速或请求更多信息。当不确定性非常高时,它可以拒绝做出决定,继续观测。对一个大型“第一视角”厨房视频数据集的测试显示,UncerTrans在仅看到动作前10%时,较多种强基线方法能更准确地预测即将发生的动作。值得注意的是,当它剔除最不确定的30%样本后,剩余预测的准确率上升到约84%,这证明了具不确定性感知筛选的实际价值。
这对日常人机协作意味着什么
对非专业读者而言,结论很直接:UncerTrans是朝着让机器在有限线索下不仅能猜测我们下一步动作,而且能判断这些猜测是否可信的一大步。通过将时间敏感的视觉模型与内部“置信计”相结合,该系统能在厨房、工厂和护理设施等混乱的真实环境中更快、更安全地做出反应。尽管该方法仍有计算成本并需进一步改进,但它为未来能够及早预见危险、在不确定时谨慎应对并最终更安全融入人类空间的机器人和监控系统提供了有希望的蓝图。
引用: Zhai, X., Liu, Y. UncerTrans: uncertainty-aware temporal transformer for early action prediction. Sci Rep 16, 7068 (2026). https://doi.org/10.1038/s41598-026-38107-4
关键词: 早期动作预测, 人机协作, 人工智能中的不确定性, 视觉变换器模型, 安全智能系统