Clear Sky Science · zh
通过智能优化与进化算法生成边界测试样本以检测随机性
几乎随机为何关乎日常安全
每次在线购物、解锁手机或发送私密信息时,都有看不见的数学骰子在为保护数据安全而掷动。这些骰子以长串的、据称是随机的比特形式出现,用作加密密钥。如果这些比特的随机性比应有的稍差一点,决心充足的攻击者有时就能发现可利用的模式。本文探讨了一种制造“几乎随机”测试序列的新方法——这些数据看上去极为随机但隐藏着微小缺陷——以便工程师能够对守护我们数字生活的设备进行严苛的压力测试。
当随机数不够随机时
现代安全系统依赖两类随机数生成器。真正的随机数生成器依赖不可预测的物理效应,如电子噪声或量子涨落;伪随机生成器则使用算法将短的随机种子扩展为长序列。实际上,两者的质量最终都取决于物理的不确定性来源,即熵源。不幸的是,真实世界的熵源很脆弱:温度变化、硬件老化或设计缺陷都可能悄然降低其随机性。为发现此类问题,标准机构(如 NIST)定义了一系列统计测试,用以检查输出比特是否看起来足够随机。设备越来越多地内置“实时随机性检测器”来监控其运行中的输出。然而,尚无有效方法生成真实且难以察觉的失败样例,以测试这些嵌入式检测器是否真正可靠。
设计勉强未通过随机性测试的序列
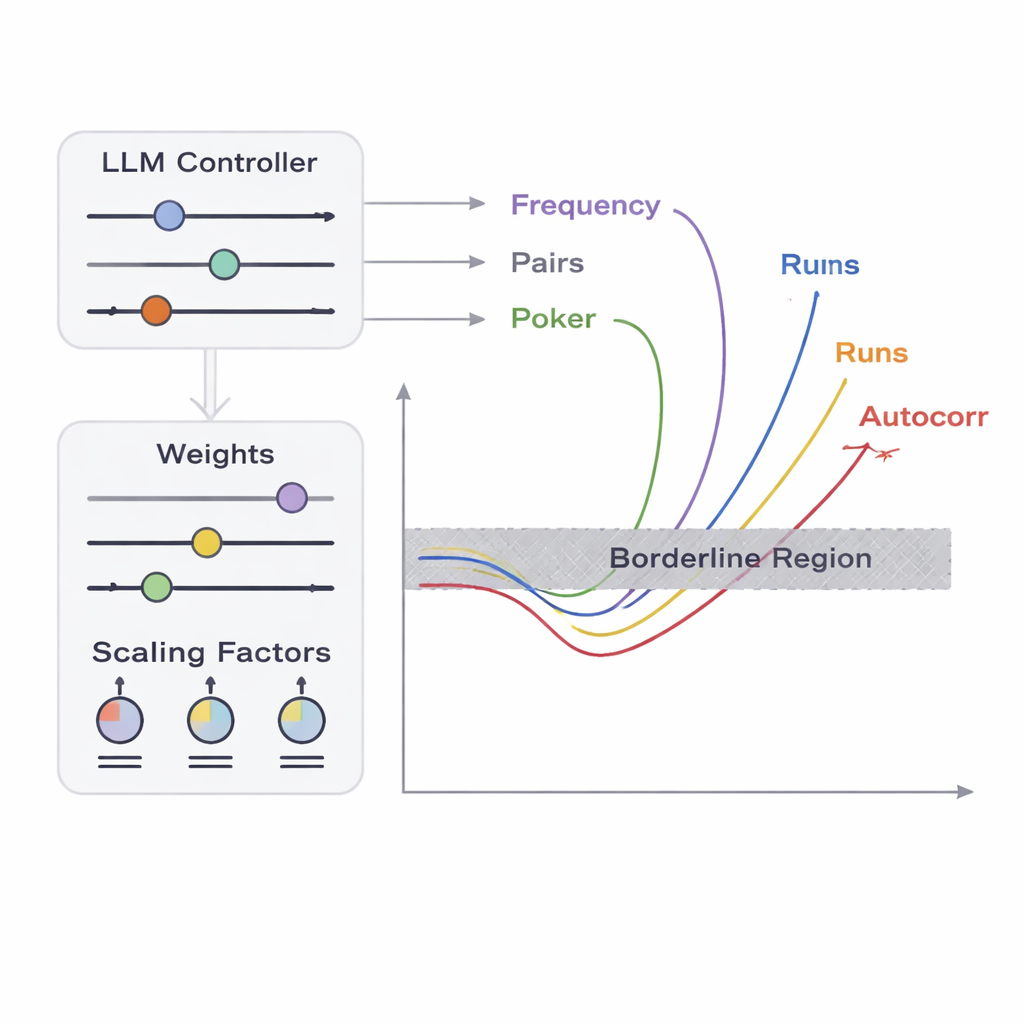
从检测者的角度看,明显的失败——例如输出全为零——很容易被发现。真正的挑战在于鉴别边界情形:那些几乎与理想随机性无异但仅在一项或多项统计检验上勉强不合格的序列。作者聚焦五项经典测试,这些测试考察比特模式的不同方面,包括零和一的频率、比特对的行为、某些短模式的分布、比特与其移位副本的相关性,以及相同比特连续出现的长度分布。他们为每个测试定义了“边界区”:一个窄小区间,数据仅稍微违反通常的接受阈值。要让一条长序列同时落入这些窄小区间的交集,靠运气几乎不可能,因为这些测试以复杂的、非线性的方式相互作用。这正是优化与人工智能发挥作用的地方。
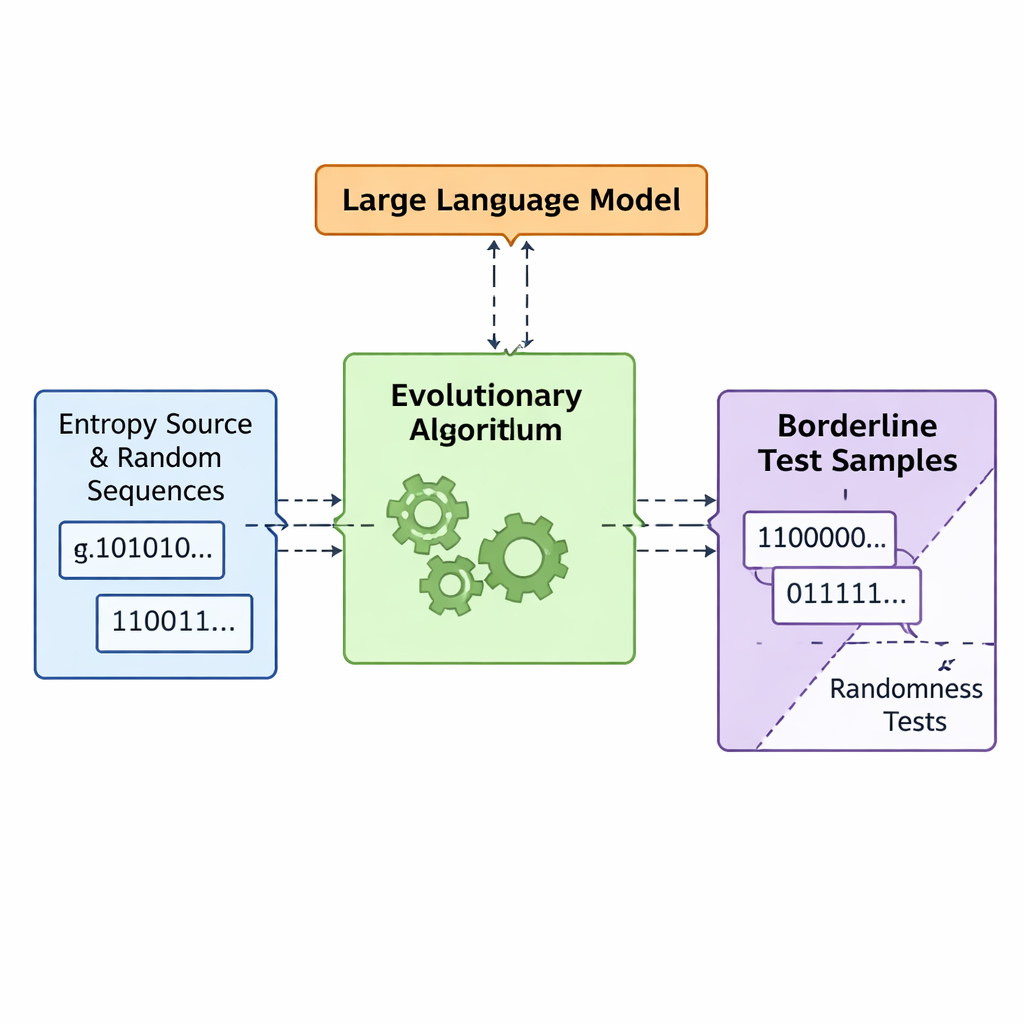
让进化与语言模型共同设计“糟糕”随机性
团队提出了名为 APAM‑IGLLM 的框架,将序列生成视为高维优化问题。每个候选序列是一串比特,其“适应度”衡量其接近五项测试边界区的程度。遗传算法反复对这些序列进行变异与重组,保留那些更接近目标区域的个体。在此之上,大型语言模型(LLM)扮演一种策略教练的角色。在每一代中,它审阅种群的摘要统计和短期历史,然后建议如何调整内部旋钮——决定每项测试在适应度中影响力的权重与缩放因子。这样就形成了一个反馈回路:遗传算法在可能的序列空间中探索,而 LLM 引导搜索,使五项测试得分共同朝向那一极小交集收敛,即序列恰好略微非随机的区域。
有缺陷的数据能看起来离完美随机有多近?
为评估其人工缺陷是否显得真实,作者将生成的序列与广泛使用的基准进行比较。他们计算了香农熵和最小熵(min‑entropy),衡量每字节看起来无法预测的程度,结果在每字节约 7.6–8 比特——接近理论最大值 8,并与商用硬件随机源和 NIST 的公开随机性信标相近。他们还运行了完整的 NIST SP 800‑22 统计测试套件,观察到这些边界序列在通过与未通过的模式上与真正的高质量随机数据几乎相同。换言之,对于标准工具而言,这些样本看起来基本正常,即便它们是刻意工程化以位于多个失败阈值附近。这使得它们成为检查嵌入式随机性检测器稳健性的理想“对抗性”输入。
这对现实世界安全意味着什么
从普通读者的角度看,这项工作为对支撑加密的随机数机制进行安全检测提供了一种新方法。工程师不再仅用明显损坏或明显健康的随机性来测试设备,而可以用精心打造的、近乎合格的序列轰炸设备,这些序列模拟微妙的硬件故障或环境漂移。如果实时随机性检测器漏掉这些边界情形,就表明存在潜在盲点,应该在设备部署到银行、保密通信或区块链系统之前修复。通过将语言模型引导的进化搜索应用于此,作者提供了一种生成此类高要求测试数据的实用工具,有助于将数字安全的隐蔽基础推向更高的可靠性水平。
引用: Gao, P., Zhang, B., Wang, Z. et al. Generating borderline test samples for randomness testers via intelligent optimization and evolutionary algorithms. Sci Rep 16, 7268 (2026). https://doi.org/10.1038/s41598-026-38020-w
关键词: 随机数生成器, 熵源, 进化算法, 大型语言模型, 密码学测试