Clear Sky Science · zh
基于模糊C均值聚类的集装箱码头垂直堆放
为何更智能的集装箱堆放很重要
每年,接近十亿个标准化的金属箱——集装箱——通过世界各地的海港流动。快速上下船这些箱子对于保持货物流动和降低成本至关重要。然而,一个看似简单的问题会拖慢速度:当所需的集装箱被错误的箱子掩埋时,起重机必须重新调整堆垛,浪费时间和燃料。本文探讨了一种基于重量的新型数据驱动堆放方式,能减少这种代价高昂的重新堆放,使港口更快、更可靠,而无需更多场地或设备。
混乱堆垛背后的隐性问题
从远处看,集装箱堆场似乎井然有序,但需要装卸的集装箱顺序具有高度不确定性。出港集装箱在船到达前就抵达码头,而其最终装载顺序受船舶稳性规则和不断变化的配载计划影响。通常较重的集装箱放在船舶较低处,较轻的放在上面。然而,当集装箱到达时,操作员往往不知道某个箱子在最终载货中是会被视为“重”还是“轻”。传统策略试图优先处理重箱或分配固定的重量类别,但这很容易适得其反:某天被分类为重的集装箱,下一次可能被视为中等,从而在装船时造成额外的重排。
垂直堆垛及重量平衡的重要性
港口采用不同的集装箱排列方式:并排成行(水平)、按相似类型堆叠成列(垂直)或两者的混合。本研究聚焦于垂直堆放,即将具有相似特征的集装箱放在相同的柱状堆列中。垂直堆放的优势在于,在不干扰过多其他箱子的情况下,更容易取到大致相近重量范围的箱子。但实际上,各重量范围内的箱子数量随航次变化。如果用刚性的分界值来定义重量组——例如每5吨一组——许多接近组边界的箱子会落在不同堆列,尽管它们重量几乎相同。这样会增加堆列内的重量差异,削弱垂直堆放带来的好处。
让数据来划分边界
作者提出一种称为基于模糊C均值的垂直序列堆放(FVSS)的新策略。该方法不是预先确定每个重量组的界限,而是基于同一路线船舶的历史重量数据,使用模糊聚类算法寻找自然形成的簇。“模糊”意味着一个集装箱的重量可以部分属于多个组,反映出例如中等与重之间并无明确界限的现实。算法为每艘船的历史数据选择最佳簇数,并识别每个簇的重量中心。然后根据各重量组中通常落入的箱子数量,将堆场预划分为相应数量的堆列,并为每个堆列分配基于这些中心的参考重量。
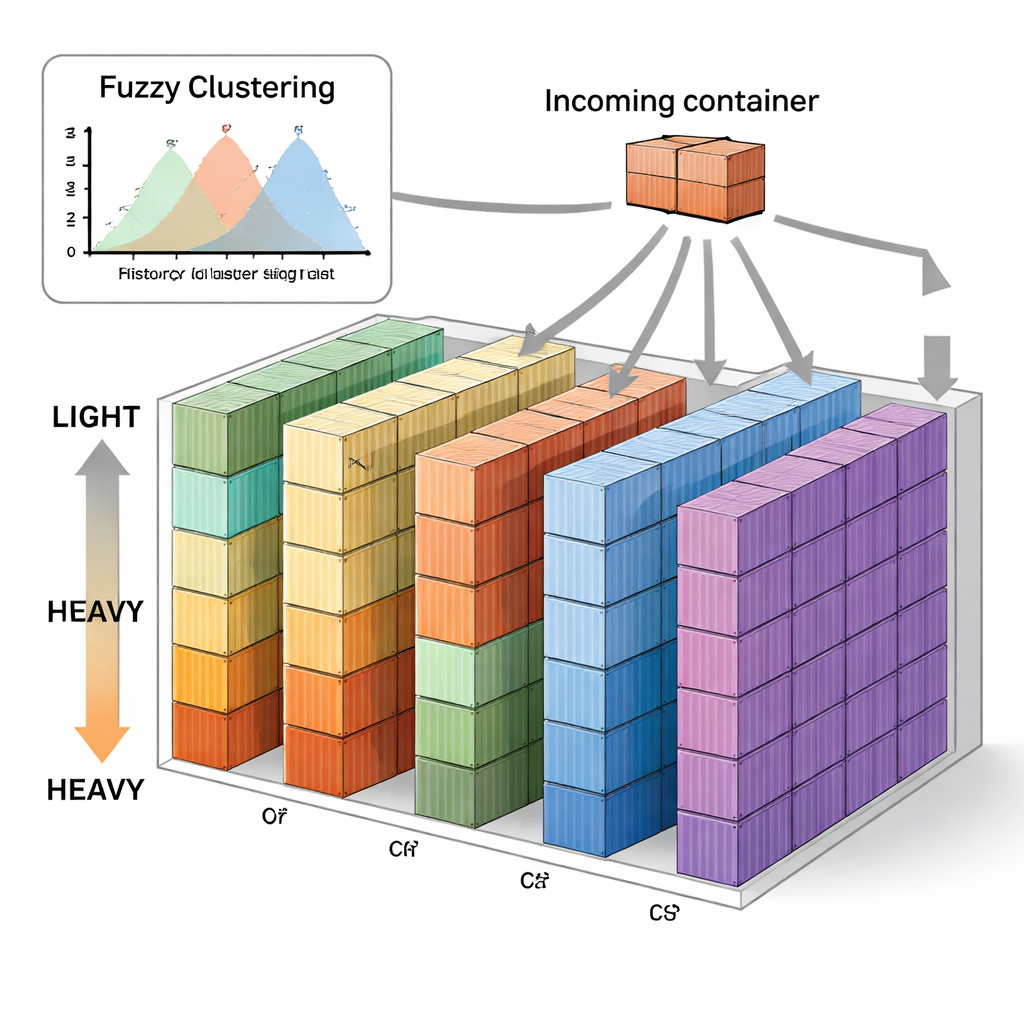
用于实时决策的简单规则
一旦堆场按此方式设置,日常操作遵循一条直观规则:每个到达的集装箱首先基于模糊聚类确定其近似重量类别。如果为该类别保留的堆列有空位,箱子便放入这些堆列;若这些堆列已满或存在多个可选项,系统选择参考重量与该箱实际重量最接近的堆列。随着时间推移,这一规则会逐步将相似重量的箱子引导入相同堆列,无需复杂的优化或持续的机器学习训练。作者使用韩国釜山集装箱码头十个月的真实数据验证了该方法,并将其与多种知名方法比较,包括随机堆放、混合水平—垂直策略,以及基于高斯混合模型和在线学习的先前技术。
对港口的意义
研究的关键度量是每个堆列内集装箱重量的变动程度——变动越小,装船时找到合适箱子的难度越低,重排也越少。在多艘船和两种堆场配置(5列和10列)的情形下,FVSS策略比其他对照方法更大幅降低了堆列内的重量方差,与随机堆放相比最多可提升78%,并较其他先进方法也有显著收益。重要的是,即便研究人员故意扭曲集装箱重量以模拟误差和临时变动,性能仍然稳健。对于港口运营者而言,这意味着可以通过依赖一套自动化但透明的规则,实现更顺畅的起重机作业和更短的船舶周转时间,而且易于在新航次完成后更新,而无需投入大量计算基础设施或复杂的学习系统。
引用: Lee, S., Lee, SH., Choi, S.C. et al. Fuzzy C-means clustering based vertical container stacking in container terminals. Sci Rep 16, 6891 (2026). https://doi.org/10.1038/s41598-026-37994-x
关键词: 集装箱码头, 堆场堆放, 模糊聚类, 海运物流, 运营效率