Clear Sky Science · zh
通过比较蒸馏纠正噪声标签:一种域自适应方法
为什么杂乱数据是一个日益严重的问题
现代人工智能依赖大量数据,但这些数据常常错误、不完整或标注不一致。当标签存在噪声——例如将一张猫的照片标为狗——学习系统可能被误导,导致准确性和可靠性下降。本文针对这一现实问题:如何训练图像识别系统,使其即便在训练标签有缺陷且图像来自不同环境(如线上商店与真实照片)时仍能表现良好。
在不同“世界”间学习
在实践中,AI 模型常从一个“源”世界学习——在那里标签经过严格校验——然后需要在标签稀缺且易出错的“目标”世界中表现。例如,在摄影棚拍摄的办公物品整洁且标注正确,而同一物品的网络摄像头或日常照片则杂乱且标注不一致。传统的域自适应方法试图通过对齐两个世界的总体统计特征来弥合差距。然而,它们通常假设目标域中可得的标签是正确的——这一冒险的假设在众包标签、低质量传感器或自动注释工具广泛存在的真实应用中往往不成立。
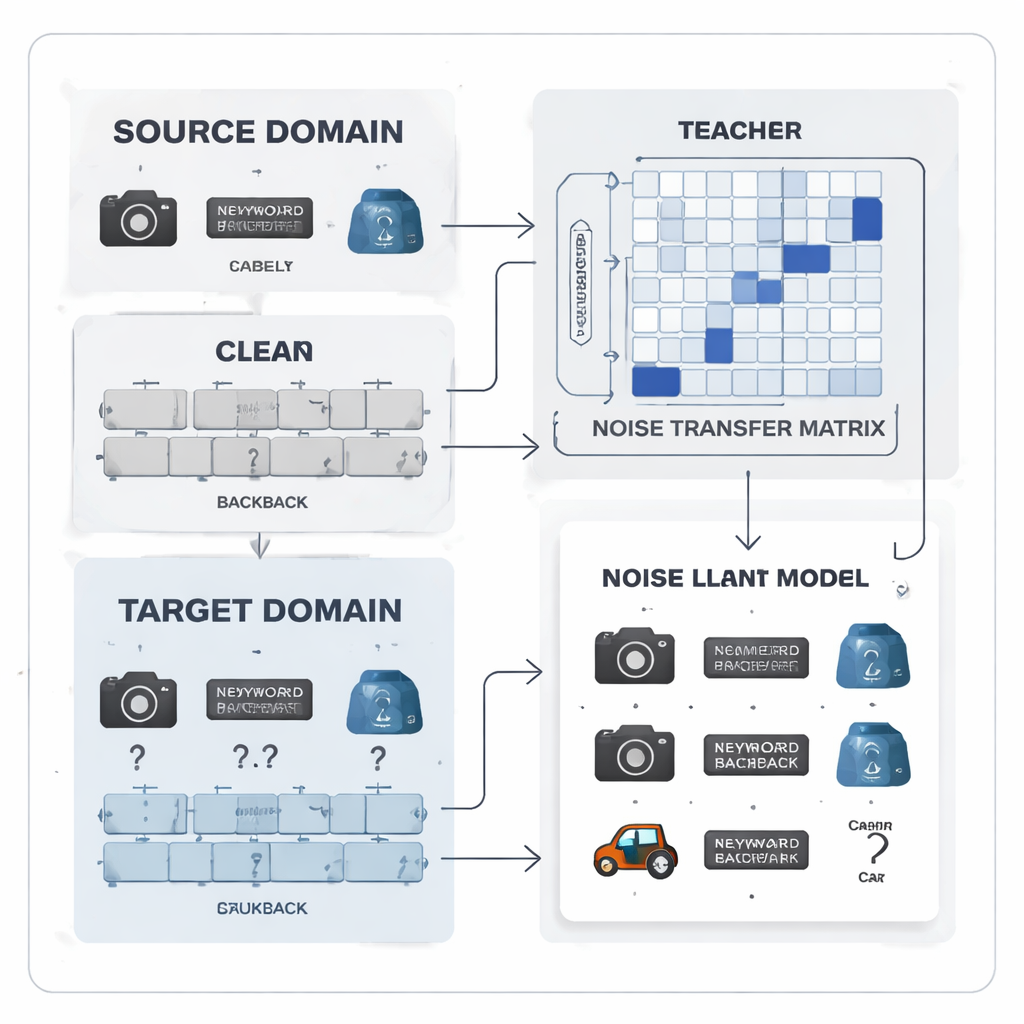
把标签错误变成可学习的模式
作者提出将标签噪声视为一种可学习的模式,而非随机混乱。他们引入了“噪声迁移矩阵”,用于刻画每个真实类别被错误标注为其它类别的概率分布。与其从少量完美的“锚点”样本估计该表——在标签噪声大且类不平衡时这不现实——方法直接在训练过程中学习该矩阵。为启动学习,该方法构建类别“原型”,即由强大的预训练模型提取的每类的平均特征指纹。利用这些原型间的相似性初始化矩阵,使得易混淆的类别(例如相似的办公工具)从一开始就被更紧密地关联,从而给予系统早期纠正标签的能力。
师生协作以获得更干净的信号
系统核心是一对师生神经网络。教师基于一个大型自监督视觉模型,该模型从海量无标签数据中学到了丰富的视觉特征。学生是一个更轻量的网络,必须在噪声的目标数据上表现良好。教师输出的软预测得分揭示了不同类别之间的相关性;由这些得分构建的类别相关矩阵总结了哪些标签倾向于共同出现。该矩阵作为引导,推动噪声迁移矩阵朝更现实的纠正方向靠拢。同时,通过所谓的蒸馏过程训练学生以匹配教师的行为,而对比学习鼓励两者对同一图像的不同增强视图生成相似的内部表征,并对不同对象生成区分开的表征。
保持修正稳定并避免过度自信
任由噪声迁移矩阵自由变化可能导致其不稳定或对离群点过于敏感。为防止这种情况,作者使用了一种基于奇异值分解的数学技巧,将矩阵分解为基本的伸缩方向。通过惩罚这些方向所暗示的整体“体积”,该方法抑制会放大噪声的极端扭曲。另一个问题是模型变得过于自信,几乎将所有概率集中到单一类别;在这种尖锐预测下,很难修正错误标签。为此,方法加入了一种基于 Tsallis 熵的熵正则化,使预测概率保持更加平滑。这使噪声迁移矩阵更容易将概率质量从错误类别部分重新分配给更合理的备选项。
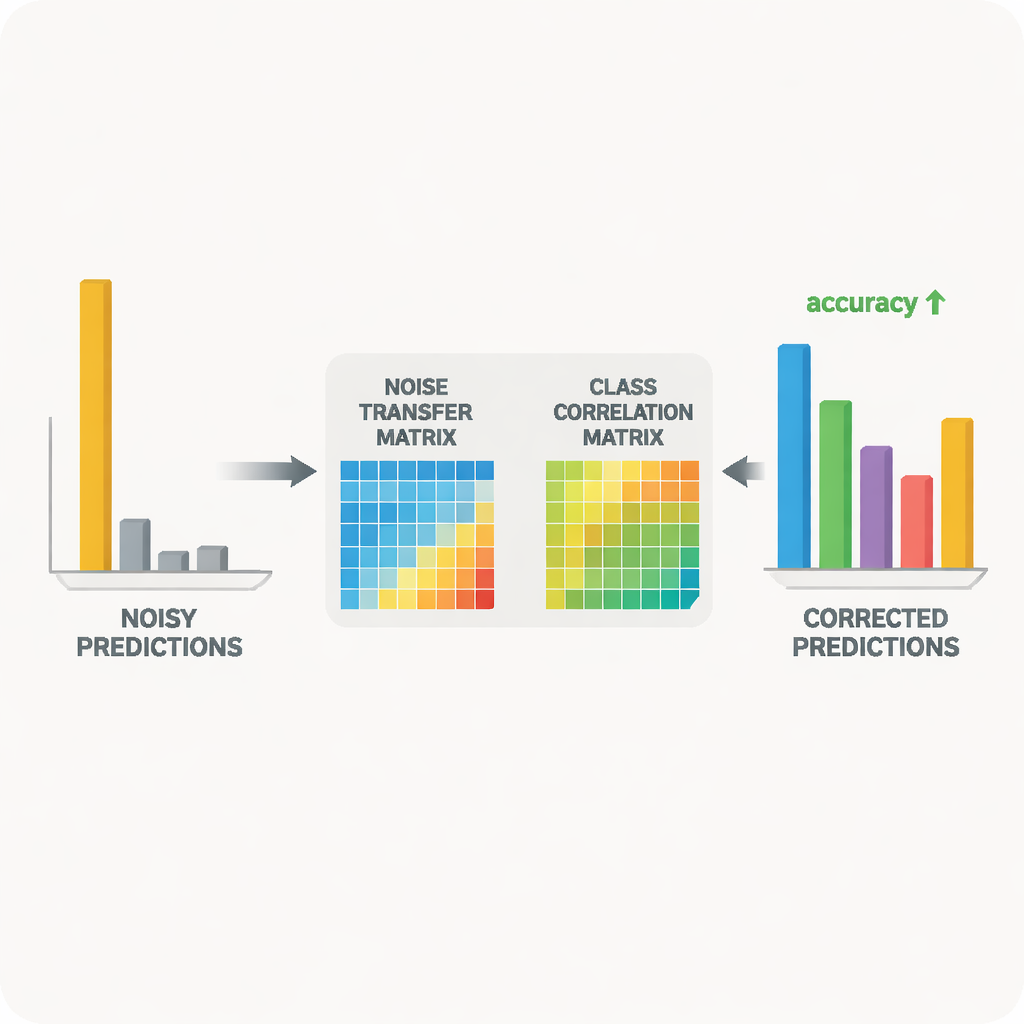
在真实图像集上验证想法
研究人员在两个广泛使用的跨域目标识别基准上测试了他们的方法:Office‑31 和 Office‑Home,包含多种风格(如产品照片、剪贴画和真实快照)下的日常办公物品图像。在多种“在一种风格上训练、在另一种上测试”的任务中,该方法在最困难、域间差异最大的情况下尤其表现出与领先算法相当或更优的性能。详尽的消融研究表明,每个组成部分——噪声矩阵的体积控制、类别相关性的引导以及熵平滑——都带来了可测的增益。对学习到的矩阵和特征空间的可视化证明,随着训练进行,错误标注的样本逐步被拉向其正确类别,源域与目标域的图像分布也变得更为一致。
这对日常 AI 系统意味着什么
对非专业读者来说,关键结论是:这项工作使 AI 模型对人类和机器在数据标注中的错误更加宽容,尤其是在模型必须从干净的实验室条件迁移到更混乱的真实环境时。通过显式学习标签出错的方式并使用强大的教师模型来引导纠正,该方法能净化噪声训练信号,产生更准确、更鲁棒的分类器。尽管该方法需要额外计算开销,但它指向了一个未来:可以更安全、更有效地利用在“野外”收集的大型不完美数据集,减少对繁复人工标注的依赖。
引用: Feng, Y., Liu, J. & Zhong, H. Correcting noisy labels via comparative distillation: a domain adaptation approach. Sci Rep 16, 7422 (2026). https://doi.org/10.1038/s41598-026-37935-8
关键词: 噪声标签, 域自适应, 知识蒸馏, 图像分类, 半监督学习