Clear Sky Science · zh
面向连续控制强化学习的风险敏感双分布评论员与 lambda 下置信界
教机器人变得谨慎
当今许多最令人印象深刻的机器人和游戏程序都依赖强化学习——一种通过试错、代理通过收集奖励来学习的训练过程。但这些代理经常追求尽可能高的得分,同时忽视其决策的风险,从而导致学习不稳定和偶发崩溃。本文提出了一种称为 TDC-λ(Twin Distributional Critics with a Lambda Lower Confidence Bound)的方法,教会这些代理不仅要追求高回报,还要在学习过程中保持可靠的安全性。
为何稳定性对学习机器很重要
诸如广泛使用的 TD3 和 Soft Actor–Critic(SAC)等标准连续控制算法,使机器人能够在复杂模拟器中奔跑、跳跃和保持平衡。然而,这些方法通常用一个单一数值来评估每个动作:对其长期回报的估计。当学习过程存在噪声时,这个简单的分数可能具有误导性,导致系统高估某些动作的价值。结果是学习曲线在平均上看似良好,但不同运行之间波动很大——如果同一算法要控制物理机器或安全关键系统,这种波动是令人担忧的。
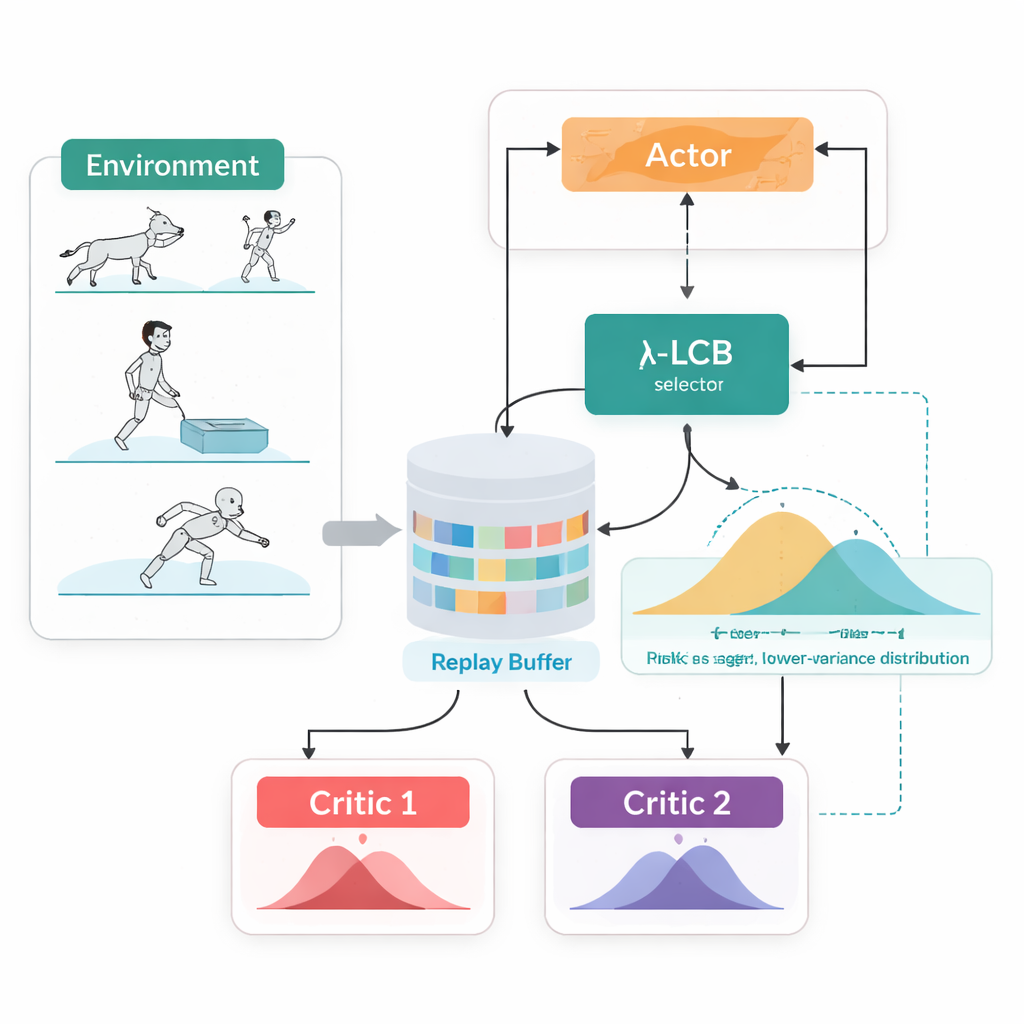
观察完整的未来,而非单一数字
TDC-λ 通过改变代理评估未来的方式来解决这一问题。它不再仅为每个动作预测一个期望回报,而是学习两个独立的“评论员”,每个评论员输出未来回报的完整分布。由这些分布可计算出的不仅是平均结果,还有可能性的离散程度。该离散程度反映了不确定性或风险。通过一个简明的规则——下置信界,TDC-λ 更倾向于选择预测更安全结果的评论员:这种结果可能略微不那么乐观,但由更一致的证据支持。一个名为风险参数 λ 的设定,平滑地调整这一选择的谨慎程度——当 λ 为零时行为类似传统的 TD3 风格方法,随着 λ 增大则变得更保守。
一个训练循环,两种行动方式
TDC-λ 的另一个实用特性是它在统一框架内同时支持确定性和随机性两种选动作方式。在训练期间,用户可以选择经典的确定性策略或经过 tanh 压缩的高斯策略以采样动作,促进探索。无论选择哪种策略,双分布评论员都以相同方式进行训练,而评估始终使用确定性的均值动作。该设计利用了早期研究的发现:测试时的确定性行为往往与采样策略表现相当或更好,同时在学习期间仍允许富有探索性的策略。
将方法付诸检验
作者在五个流行的 MuJoCo 基准任务上评估了 TDC-λ,其中模拟机器人如 HalfCheetah、Hopper、Ant、Walker2d 和 Humanoid 必须学习高效移动。在这些任务中,该方法在最终表现上与强基线(包括 TD3、DDPG、SAC 以及一种名为 MEOW 的先进流模型方法)持平或有所改进,同时在重复运行中的变异性持续更低。在更难、维度更高的任务(如 Humanoid)中,略高的 λ 值——即更谨慎的目标估计——带来了最佳的长期回报和最紧凑的性能带。其他模拟器(PyBullet 和 NVIDIA Isaac)上的补充实验以及跟踪学习信号变异性的诊断进一步强化了 TDC-λ 在不减慢学习速度的情况下使学习更稳定的结论。
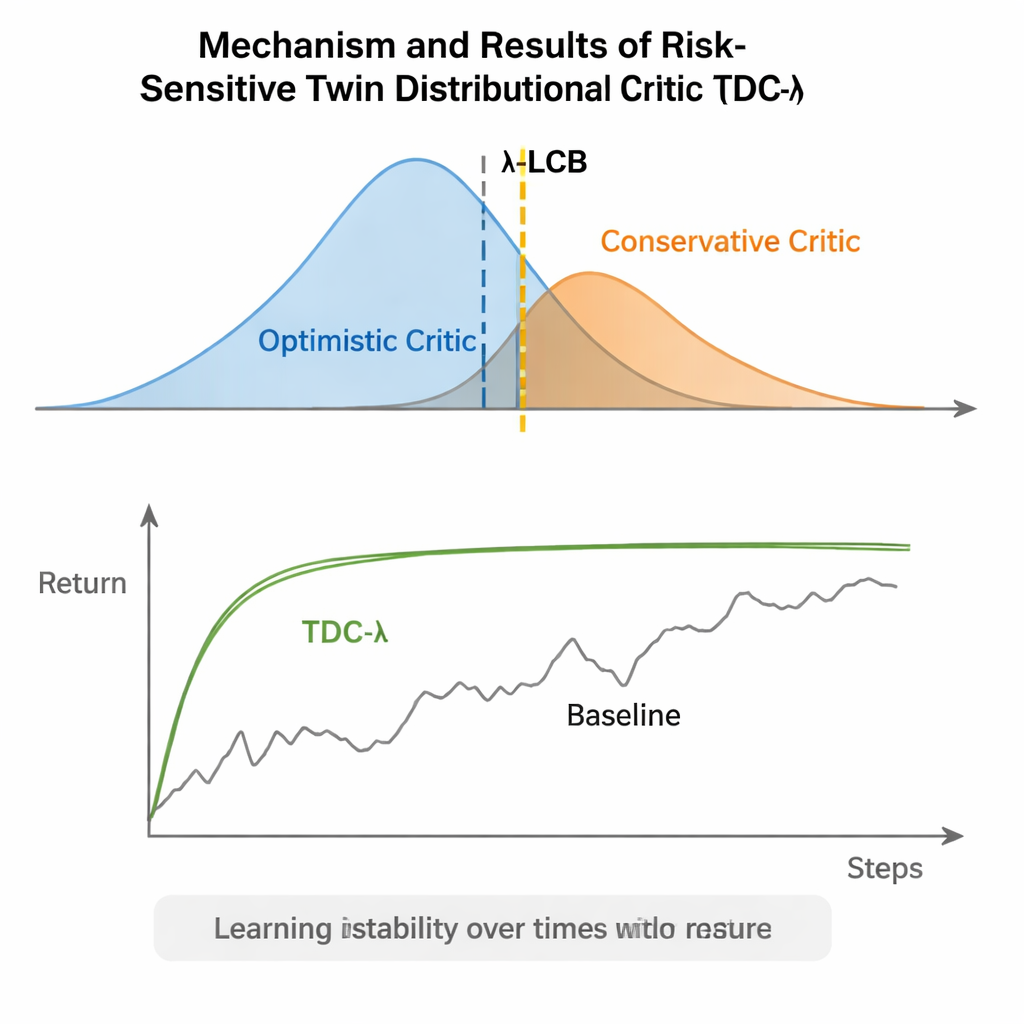
一个简单旋钮,带来更安全的学习
通俗地说,TDC-λ 在决定信任自身乐观程度时为强化学习系统提供了一个“安全边际”。通过学习可能结果的完整分布,然后使用 λ 旋钮倾向于更安全的评论员,该算法在保持高最终性能的同时减少了训练中的剧烈波动。对实践者而言,这为构建更可靠的机器人及其他连续控制系统控制器提供了实用方法:从中度保守的 λ 开始,并根据学习过程的波动情况进行调整。更广泛的结论是,谨慎地塑造代理的学习目标——它从中学习的目标——可以带来很多通常归因于更复杂架构的鲁棒性,使先进的强化学习既更稳健也更易于采用。
引用: Osman, O., Yalcin Kavus, B., Karaca, T.K. et al. Risk sensitive twin distributional critics with a lambda lower confidence bound for continuous control reinforcement learning. Sci Rep 16, 6699 (2026). https://doi.org/10.1038/s41598-026-37910-3
关键词: 强化学习, 连续控制, 风险敏感学习, 分布式评论员, 机器人学