Clear Sky Science · zh
可持续且可解释的心脏病预测:面向生物医学医疗应用的临床决策支持方法
为何更智能的心脏筛查至关重要
心脏病是全球头号杀手,但许多人仍然是在发生严重事件(如心肌梗死)之后才发现自己存在风险。医生已经收集一些简单的测量值——例如年龄、血压、胆固醇和基本检测结果——但要把这些信息迅速且可靠地转化为关于心脏病的二元判断并不容易。本研究探讨了一种新型计算模型,该模型可以从这些常规数值中学习,以极高的准确率预测谁更可能患心脏病,并且关键是能够用医生可理解的方式解释其推理过程。
日益沉重的心脏病负担
每年,心血管疾病在全球造成约1800万人死亡。如果能更早识别高风险患者并尽早干预,许多死亡本可避免。传统诊断测试可能具有创伤性、费用高昂,或在边缘病例中准确性不足。与此同时,医院现在保存着大量患者的数字化数据,从年龄和性别到血压、胆固醇以及基本心脏检测读数。将这股信息洪流转化为清晰、可靠的风险评估,已成为现代医学最大的机遇之一,同时也是最大的挑战之一。
从黑箱到透明助理
近年来,人工智能在识别医学数据中人类可能忽视的微妙模式方面显示出潜力。然而,许多强大的模型表现得像“黑箱”:它们可能很准确,但无法轻易解释为何得出某一具体结论。这种缺乏透明性在医疗领域是一个问题,因为医生必须为诊断和治疗选择提供理由。作者通过设计基于一维卷积神经网络(1D CNN)的心脏病预测系统来弥补这一差距。与需要专家手工设计观察特征的旧方法不同,该网络自动发现标准患者测量值中的有用模式,同时仍被设计为足够高效,适合计算资源有限的门诊使用。
模型如何从常规体检中学习
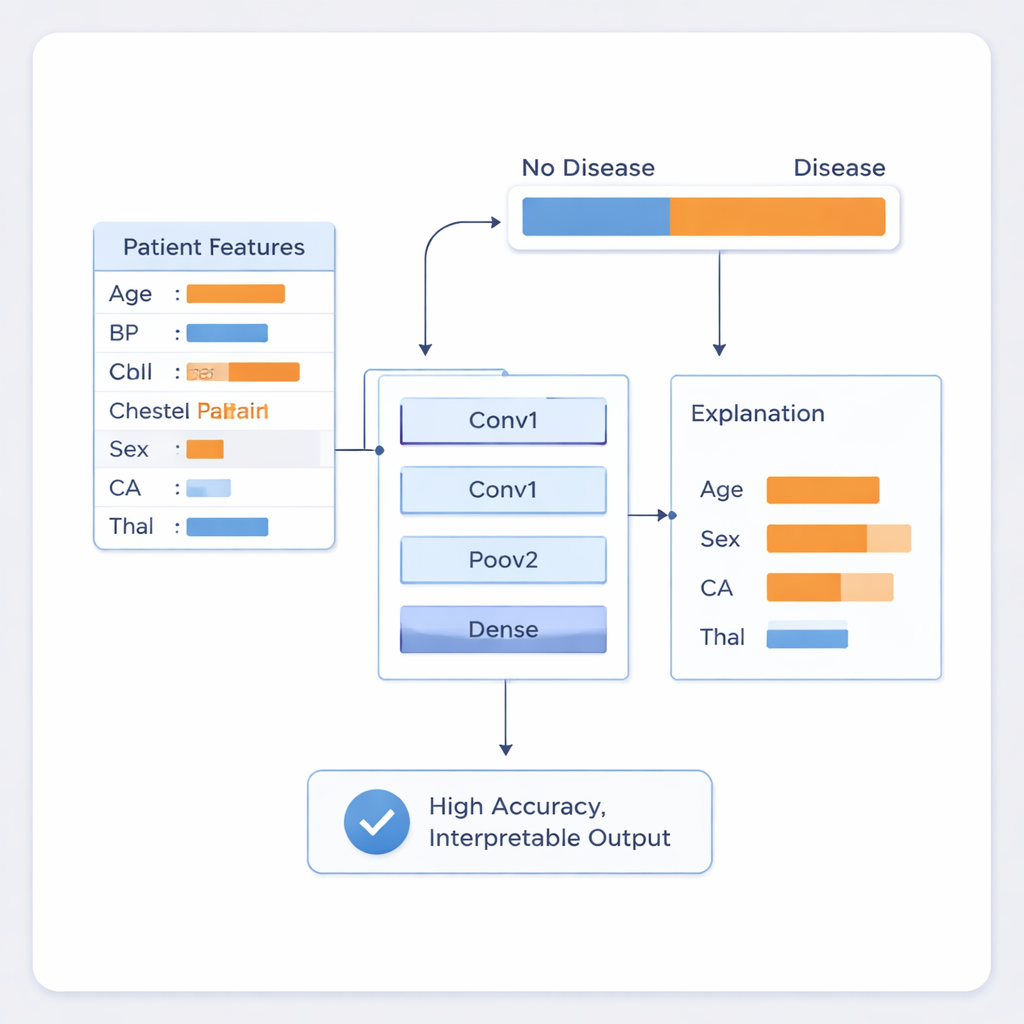
研究人员在一个广泛使用的心脏病数据集上训练了他们的系统,该数据集包含303名患者记录,每条记录有14项常规收集的项目,如年龄、性别、血压、胆固醇水平、胸痛类型及基本心脏检测结果。他们对数据进行了细致处理:对数值进行了标准化,以避免某一测量项主导学习过程,并将胸痛类型等类别变量转为数值形式。为最大化相对较小的数据集并模拟真实临床测量中的自然噪声,团队在训练数据中加入了少量随机变动。随后,他们将这些记录输入到一个紧凑的1D CNN架构,包含两层主要的模式检测层,随后是将这些模式合成为最终“有病”或“无病”预测的层。
将数值转化为可信的解释
在临床环境中,仅有性能还不够,因此作者将模型与两种解释技术LIME和SHAP配合使用。这些方法探测已训练的网络,以估计每个输入因素在个体患者预测中将结果推向“有病”或“无病”的程度。实际上,这意味着系统不仅能告诉医生某患者为高风险,还能指出例如其结果主要由性别、狭窄血管数量和一种名为地中海贫血(thalassemia)的血液疾病的组合所驱动。这些被突出的特征与已知的心脏病风险医学知识一致,帮助临床医生判断何时信任模型、何时对其提出质疑。
可能惠及日常诊所的结果
在模型此前未见过的测试数据上,它大约能在100名患者中正确分类98名的心脏病状态,在标注有病病例时达到完全精确(在该样本中没有产生误报),并总体上表现出近乎完美的辨别病与健康心脏的能力。同样重要的是,该系统很轻量:在标准云硬件上训练只需几分钟,且能在不到一秒的时间内给出答案,表明它可在普通医院计算机上运行,而无需专用超级计算机。尽管该研究基于一个历史数据集,且需要在更多医院和不同人群中进行更广泛的测试,但它指向了这样一种未来:常规体检数据结合透明的人工智能,可以为医生提供一个额外且值得信赖的“第二意见”,帮助在资源受限的医疗环境中更早发现心脏病。
引用: Kehkashan, T., Abdelhaq, M., Al-Shamayleh, A.S. et al. Sustainable and interpretable heart disease prediction: a clinical decision support approach for biomedical healthcare applications. Sci Rep 16, 7213 (2026). https://doi.org/10.1038/s41598-026-37840-0
关键词: 心脏病预测, 可解释的人工智能, 临床决策支持, 卷积神经网络, 医学数据分析