Clear Sky Science · zh
使用混合特征选择方法高效检测 TON-IoT 数据集中的入侵
为何保护智能设备至关重要
数以十亿计的日常设备——从家庭摄像头到工厂传感器——通过互联网相互通信,形成我们所称的物联网(IoT)。这种互联带来便利和效率,但也为黑客打开了新入口。本文摘要探讨一个简单却关键的问题:如何在这些庞大的设备网络中可靠地发现攻击,而无需依赖耗电、资源密集的安全软件?
发现数字入侵的挑战
为研究物联网系统上的攻击,研究人员常依赖大型公开数据集,这些数据记录了正常运行与网络攻击期间的流量特征。其中最广泛使用的是 ToN-IoT 数据集,它来自逼真的工业测试台并捕获了真实流量,包含多种攻击类型,如拒绝服务、勒索软件、密码破解和中间人窃听。然而,作者指出这个数据集存在一个隐蔽问题:许多攻击来自固定的 IP 地址段和端口号。这意味着模型可能通过“识别”攻击者身份来作弊,而非学习恶意行为的本质。这样训练的模型在实验室里得分很高,但在攻击者来自新地址时可能严重失效。
从冗余数据到精简的行为视角
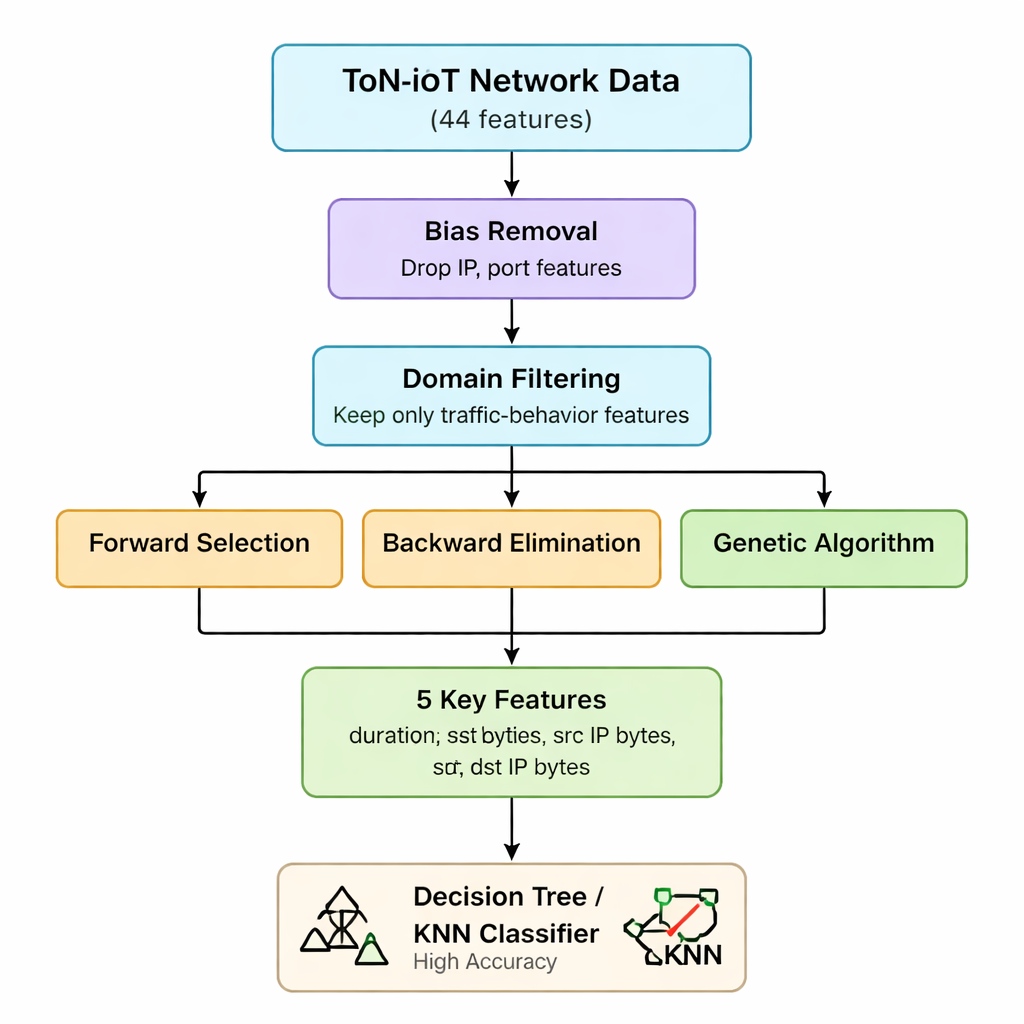
原始 ToN-IoT 网络数据对每个连接包含 44 项不同测量,从 IP 信息到网页与加密流量细节不等。处理全部特征会增加计算时间和内存需求,这对资源有限的物联网网关和边缘设备是个问题。作者首先基于对攻击机制的理解,剔除那些有偏差(例如 IP 地址和端口号)或对区分攻击帮助不大的特征。他们认为大多数物联网威胁最终表现为数据包和字节的发送/接收数量以及连接持续时间的异常模式——与通信双方身份无关。第一阶段将特征集从 44 项缩减到 7 项与流量量级和持续时间相关的核心统计量。
混合特征选择:从三种视角审视相同数据
接着,团队应用三种不同的“包装式”方法,这些方法通过反复训练模型、逐步添加、移除或重组特征来判断哪些子集最为重要。前向选择从空集开始,只有在特征提升准确率时才保留该特征;后向剔除从全部七项开始,移除那些删除后不损害准确率的特征;遗传算法则并行探索大量组合,通过代际演化寻找更优子集。三种方法均使用简单的决策树分类器,以准确率为评估标准。通过对结果取交集,作者得出稳定的五个核心特征:连接时长、发送字节数、接收字节数及其对应的 IP 层字节计数。这五个变量有效捕捉到那种表明多种攻击类型的异常流量激增或不平衡现象。
轻量模型仍具强劲表现
在这个精简且以行为为中心的数据集上,研究人员评估了几种直接的机器学习模型区分安全流量与攻击流量的能力。仅使用这五个特征时,决策树在“攻击 vs 正常”的二分类任务上达到 98.6% 的准确率,在区分多种攻击类别的任务上达到 97.2% 的准确率。k 近邻模型表现相近,而诸如随机森林或梯度提升等更复杂的集成方法仅带来微小提升,但需要更多计算和内存。更为关键的是,作者通过统计检验确认所选特征确实具有信息量,而非数据采集方式的伪像。他们也指出,旨在与正常流量混淆的细微中间人攻击依然更难检测,这暗示未来工作可能需要更丰富的协议或时序线索来应对这些情况。
对现实世界安全的意义
对非专业读者来说,关键结论是:保护物联网系统并不总需要庞大的模型或数十项技术性度量。通过剔除只在单一实验环境中有效的线索,并转而聚焦于少量流量行为,作者表明简单、快速的算法仍能高可靠地检测大多数攻击。他们的五特征版本 ToN-IoT 数据集更易在资源受限的边缘设备上处理,使其适用于必须实时应对威胁的路由器、网关和小型集线器。简而言之,该研究为日益环绕我们的日常智能设备提供了更可部署、值得信赖的入侵检测路径。
引用: Dharini, N., Janani, V.S. & Katiravan, J. Efficient detection of intrusions in TON-IoT dataset using hybrid feature selection approach. Sci Rep 16, 7763 (2026). https://doi.org/10.1038/s41598-026-37834-y
关键词: 物联网安全, 入侵检测, 机器学习, 特征选择, 网络流量